жҖҺд№ҲзҗҶи§Јwebзҡ„ж—¶й—ҙдёҺз©әй—ҙеӨҚжқӮеәҰ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңжҖҺд№ҲзҗҶи§Јwebзҡ„ж—¶й—ҙдёҺз©әй—ҙеӨҚжқӮеәҰвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁжҖҺд№ҲзҗҶи§Јwebзҡ„ж—¶й—ҙдёҺз©әй—ҙеӨҚжқӮеәҰй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқжҖҺд№ҲзҗҶи§Јwebзҡ„ж—¶й—ҙдёҺз©әй—ҙеӨҚжқӮеәҰвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
з®—жі•пјҲAlgorithmпјүжҳҜжҢҮз”ЁжқҘж“ҚдҪңж•°жҚ®гҖҒи§ЈеҶізЁӢеәҸй—®йўҳзҡ„дёҖз»„ж–№жі•гҖӮеҜ№дәҺеҗҢдёҖдёӘй—®йўҳпјҢдҪҝз”ЁдёҚеҗҢзҡ„з®—жі•пјҢд№ҹи®ёжңҖз»Ҳеҫ—еҲ°зҡ„з»“жһңжҳҜдёҖж ·зҡ„пјҢжҜ”еҰӮжҺ’еәҸе°ұжңүеүҚйқўзҡ„еҚҒеӨ§з»Ҹе…ёжҺ’еәҸе’ҢеҮ з§ҚеҘҮи‘©жҺ’еәҸпјҢиҷҪ然结жһңзӣёеҗҢпјҢдҪҶеңЁиҝҮзЁӢдёӯж¶ҲиҖ—зҡ„иө„жәҗе’Ңж—¶й—ҙеҚҙдјҡжңүеҫҲеӨ§зҡ„еҢәеҲ«пјҢжҜ”еҰӮеҝ«йҖҹжҺ’еәҸдёҺзҢҙеӯҗжҺ’еәҸпјҡпјүгҖӮ
йӮЈд№ҲжҲ‘们еә”иҜҘеҰӮдҪ•еҺ»иЎЎйҮҸдёҚеҗҢз®—жі•д№Ӣй—ҙзҡ„дјҳеҠЈе‘ўпјҹ
дё»иҰҒиҝҳжҳҜд»Һз®—жі•жүҖеҚ з”Ёзҡ„гҖҢж—¶й—ҙгҖҚе’ҢгҖҢз©әй—ҙгҖҚдёӨдёӘз»ҙеәҰеҺ»иҖғйҮҸгҖӮ
ж—¶й—ҙз»ҙеәҰпјҡжҳҜжҢҮжү§иЎҢеҪ“еүҚз®—жі•жүҖж¶ҲиҖ—зҡ„ж—¶й—ҙпјҢжҲ‘们йҖҡеёёз”ЁгҖҢж—¶й—ҙеӨҚжқӮеәҰгҖҚжқҘжҸҸиҝ°гҖӮ
з©әй—ҙз»ҙеәҰпјҡжҳҜжҢҮжү§иЎҢеҪ“еүҚз®—жі•йңҖиҰҒеҚ з”ЁеӨҡе°‘еҶ…еӯҳз©әй—ҙпјҢжҲ‘们йҖҡеёёз”ЁгҖҢз©әй—ҙеӨҚжқӮеәҰгҖҚжқҘжҸҸиҝ°гҖӮ
ж—¶й—ҙеӨҚжқӮеәҰ
еӨ§Oз¬ҰеҸ·иЎЁзӨәжі•
еӨ§OиЎЁзӨәжі•пјҡз®—жі•зҡ„ж—¶й—ҙеӨҚжқӮеәҰйҖҡеёёз”ЁеӨ§Oз¬ҰеҸ·иЎЁиҝ°пјҢе®ҡд№үдёә T[n] = O(f(n))гҖӮз§°еҮҪж•°T(n)д»Ҙf(n)дёәз•ҢжҲ–иҖ…з§°T(n)еҸ—йҷҗдәҺf(n)гҖӮ
еҰӮжһңдёҖдёӘй—®йўҳзҡ„规模жҳҜnпјҢи§ЈиҝҷдёҖй—®йўҳзҡ„жҹҗдёҖз®—жі•жүҖйңҖиҰҒзҡ„ж—¶й—ҙдёәT(n)гҖӮT(n)з§°дёәиҝҷдёҖз®—жі•зҡ„вҖңж—¶й—ҙеӨҚжқӮеәҰвҖқгҖӮ
дёҠйқўе…¬ејҸдёӯз”ЁеҲ°зҡ„ Landauз¬ҰеҸ·жҳҜз”ұеҫ·еӣҪж•°и®әеӯҰ家дҝқзҪ—В·е·ҙиө«жӣјпјҲPaul BachmannпјүеңЁе…¶1892е№ҙзҡ„и‘—дҪңгҖҠи§Јжһҗж•°и®әгҖӢйҰ–е…Ҳеј•е…ҘпјҢз”ұеҸҰдёҖдҪҚеҫ·еӣҪж•°и®әеӯҰ家иүҫеҫ·и’ҷВ·жң—йҒ“пјҲEdmund LandauпјүжҺЁе№ҝгҖӮLandauз¬ҰеҸ·зҡ„дҪңз”ЁеңЁдәҺз”Ёз®ҖеҚ•зҡ„еҮҪж•°жқҘжҸҸиҝ°еӨҚжқӮеҮҪж•°иЎҢдёәпјҢз»ҷеҮәдёҖдёӘдёҠжҲ–дёӢпјҲзЎ®пјүз•ҢгҖӮеңЁи®Ўз®—з®—жі•еӨҚжқӮеәҰж—¶дёҖиҲ¬еҸӘз”ЁеҲ°еӨ§Oз¬ҰеҸ·пјҢLandauз¬ҰеҸ·дҪ“зі»дёӯзҡ„е°Ҹoз¬ҰеҸ·гҖҒОҳз¬ҰеҸ·зӯүзӯүжҜ”иҫғдёҚеёёз”ЁгҖӮиҝҷйҮҢзҡ„OпјҢжңҖеҲқжҳҜз”ЁеӨ§еҶҷеёҢи…Ҡеӯ—жҜҚпјҢдҪҶзҺ°еңЁйғҪз”ЁеӨ§еҶҷиӢұиҜӯеӯ—жҜҚOпјӣе°Ҹoз¬ҰеҸ·д№ҹжҳҜз”Ёе°ҸеҶҷиӢұиҜӯеӯ—жҜҚoпјҢОҳз¬ҰеҸ·еҲҷз»ҙжҢҒеӨ§еҶҷеёҢи…Ҡеӯ—жҜҚОҳгҖӮ
еӨ§Oз¬ҰеҸ·жҳҜдёҖз§Қз®—жі•гҖҢеӨҚжқӮеәҰгҖҚзҡ„гҖҢзӣёеҜ№гҖҚгҖҢиЎЁзӨәгҖҚж–№ејҸгҖӮ
иҝҷдёӘеҸҘеӯҗйҮҢжңүдёҖдәӣйҮҚиҰҒиҖҢдёҘи°Ёзҡ„з”ЁиҜҚпјҡ
зӣёеҜ№(relative)пјҡдҪ еҸӘиғҪжҜ”иҫғзӣёеҗҢзҡ„дәӢзү©гҖӮдҪ дёҚиғҪжҠҠдёҖдёӘеҒҡз®—ж•°д№ҳжі•зҡ„з®—жі•е’ҢжҺ’еәҸж•ҙж•°еҲ—иЎЁзҡ„з®—жі•иҝӣиЎҢжҜ”иҫғгҖӮдҪҶжҳҜпјҢжҜ”иҫғ2дёӘз®—жі•жүҖеҒҡзҡ„з®—жңҜж“ҚдҪңпјҲдёҖдёӘеҒҡд№ҳжі•пјҢдёҖдёӘеҒҡеҠ жі•пјүе°Ҷдјҡе‘ҠиҜүдҪ дёҖдәӣжңүж„Ҹд№үзҡ„дёңиҘҝпјӣ
иЎЁзӨә(representation)пјҡеӨ§O(з”Ёе®ғжңҖз®ҖеҚ•зҡ„еҪўејҸ)жҠҠз®—жі•й—ҙзҡ„жҜ”иҫғз®ҖеҢ–дёәдәҶдёҖдёӘеҚ•дёҖеҸҳйҮҸгҖӮиҝҷдёӘеҸҳйҮҸзҡ„йҖүжӢ©еҹәдәҺи§ӮеҜҹжҲ–еҒҮи®ҫгҖӮдҫӢеҰӮпјҢжҺ’еәҸз®—жі•д№Ӣй—ҙзҡ„еҜ№жҜ”йҖҡеёёжҳҜеҹәдәҺжҜ”иҫғж“ҚдҪң(жҜ”иҫғ2дёӘз»“зӮ№жқҘеҶіе®ҡиҝҷ2дёӘз»“зӮ№зҡ„зӣёеҜ№йЎәеәҸ)гҖӮиҝҷйҮҢйқўе°ұеҒҮи®ҫдәҶжҜ”иҫғж“ҚдҪңзҡ„и®Ўз®—ејҖй”ҖеҫҲеӨ§гҖӮдҪҶжҳҜпјҢеҰӮжһңжҜ”иҫғж“ҚдҪңзҡ„и®Ўз®—ејҖй”ҖдёҚеӨ§пјҢиҖҢдәӨжҚўж“ҚдҪңзҡ„и®Ўз®—ејҖй”ҖеҫҲеӨ§пјҢеҸҲдјҡжҖҺд№Ҳж ·е‘ўпјҹиҝҷе°ұж”№еҸҳдәҶе…ҲеүҚзҡ„жҜ”иҫғж–№ејҸпјӣ
еӨҚжқӮеәҰ(complexity)пјҡеҰӮжһңжҺ’еәҸ10,000дёӘе…ғзҙ иҠұиҙ№дәҶжҲ‘1з§’пјҢйӮЈд№ҲжҺ’еәҸ1зҷҫдёҮдёӘе…ғзҙ дјҡиҠұеӨҡе°‘ж—¶й—ҙпјҹеңЁиҝҷдёӘдҫӢеӯҗйҮҢпјҢеӨҚжқӮеәҰе°ұжҳҜзӣёеҜ№е…¶д»–дёңиҘҝзҡ„еәҰйҮҸз»“жһңгҖӮ
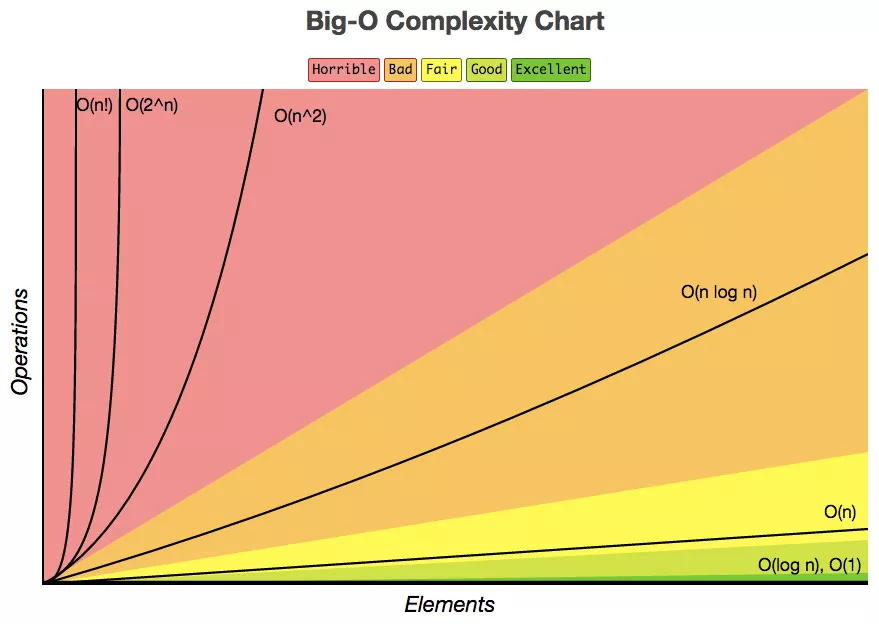
еёёи§Ғзҡ„ж—¶й—ҙеӨҚжқӮеәҰйҮҸзә§
жҲ‘们е…Ҳд»Һеёёи§Ғзҡ„ж—¶й—ҙеӨҚжқӮеәҰйҮҸзә§иҝӣиЎҢеӨ§Oзҡ„зҗҶи§Јпјҡ
еёёж•°йҳ¶O(1)
зәҝжҖ§йҳ¶O(n)
е№іж–№йҳ¶O(nВІ)
еҜ№ж•°йҳ¶O(logn)
зәҝжҖ§еҜ№ж•°йҳ¶O(nlogn)
O(1)

ж— и®әд»Јз Ғжү§иЎҢдәҶеӨҡе°‘иЎҢпјҢе…¶д»–еҢәеҹҹдёҚдјҡеҪұе“ҚеҲ°ж“ҚдҪңпјҢиҝҷдёӘд»Јз Ғзҡ„ж—¶й—ҙеӨҚжқӮеәҰйғҪжҳҜO(1)
void swapTwoInts(int &a, int &b){
int temp = a;
a = b;
b = temp;
}O(n)
еңЁдёӢйқўиҝҷж®өд»Јз ҒпјҢforеҫӘзҺҜйҮҢйқўзҡ„д»Јз Ғдјҡжү§иЎҢ n йҒҚпјҢеӣ жӯӨе®ғж¶ҲиҖ—зҡ„ж—¶й—ҙжҳҜйҡҸзқҖ n зҡ„еҸҳеҢ–иҖҢеҸҳеҢ–зҡ„пјҢеӣ жӯӨеҸҜд»Ҙз”ЁO(n)жқҘиЎЁзӨәе®ғзҡ„ж—¶й—ҙеӨҚжқӮеәҰгҖӮ
int sum ( int n ){
int ret = 0;
for ( int i = 0 ; i <= n ; i ++){
ret += i;
}
return ret;
}зү№еҲ«дёҖжҸҗзҡ„жҳҜ c * O(n) дёӯзҡ„ c еҸҜиғҪе°ҸдәҺ 1 пјҢжҜ”еҰӮдёӢйқўиҝҷж®өд»Јз Ғпјҡ
void reverse ( string &s ) {
int n = s.size();
for (int i = 0 ; i < n/2 ; i++){
swap ( s[i] , s[n-1-i]);
}
}O(nВІ)

еҪ“еӯҳеңЁеҸҢйҮҚеҫӘзҺҜзҡ„ж—¶еҖҷпјҢеҚіжҠҠ O(n) зҡ„д»Јз ҒеҶҚеөҢеҘ—еҫӘзҺҜдёҖйҒҚпјҢе®ғзҡ„ж—¶й—ҙеӨҚжқӮеәҰе°ұжҳҜ O(nВІ) дәҶгҖӮ
void selectionSort(int arr[],int n){
for(int i = 0; i < n ; i++){
int minIndex = i;
for (int j = i + 1; j < n ; j++ )
if (arr[j] < arr[minIndex])
minIndex = j;
swap ( arr[i], arr[minIndex]);
}
}иҝҷйҮҢз®ҖеҚ•зҡ„жҺЁеҜјдёҖдёӢ
дёҚйҡҫеҫ—еҲ°е…¬ејҸпјҡ
(n - 1) + (n - 2) + (n - 3) + ... + 0
= (0 + n - 1) * n / 2
= O (n ^2)
еҪ“然并дёҚжҳҜжүҖжңүзҡ„еҸҢйҮҚеҫӘзҺҜйғҪжҳҜ O(nВІ)пјҢжҜ”еҰӮдёӢйқўиҝҷж®өиҫ“еҮә 30n ж¬ЎHello,дә”еҲҶй’ҹеӯҰз®—жі•пјҡпјүзҡ„д»Јз ҒгҖӮ
void printInformation (int n ){
for (int i = 1 ; i <= n ; i++)
for (int j = 1 ; j <= 30 ; j ++)
cout<< "Hello,дә”еҲҶй’ҹеӯҰз®—жі•пјҡпјү"<< endl;
}O(logn)
![еӣҫзүҮ]()
int binarySearch( int arr[], int n , int target){
int l = 0, r = n - 1;
while ( l <= r) {
int mid = l + (r - l) / 2;
if (arr[mid] == target) return mid;
if (arr[mid] > target ) r = mid - 1;
else l = mid + 1;
}
return -1;
}еңЁдәҢеҲҶжҹҘжүҫжі•зҡ„д»Јз ҒдёӯпјҢйҖҡиҝҮwhileеҫӘзҺҜпјҢжҲҗ 2 еҖҚж•°зҡ„зј©еҮҸжҗңзҙўиҢғеӣҙпјҢд№ҹе°ұжҳҜиҜҙйңҖиҰҒз»ҸиҝҮ log2^n ж¬ЎеҚіеҸҜи·іеҮәеҫӘзҺҜгҖӮ
еҗҢж ·зҡ„иҝҳжңүдёӢйқўдёӨж®өд»Јз Ғд№ҹжҳҜ O(logn) зә§еҲ«зҡ„ж—¶й—ҙеӨҚжқӮеәҰгҖӮ
// ж•ҙеҪўиҪ¬жҲҗеӯ—з¬ҰдёІ
string intToString ( int num ){
string s = "";
// n з»ҸиҝҮеҮ ж¬ЎвҖңйҷӨд»Ҙ10вҖқзҡ„ж“ҚдҪңеҗҺпјҢзӯүдәҺ0
while (num ){
s += '0' + num%10;
num /= 10;
}
reverse(s)
return s;
}void hello (int n ) {
// n йҷӨд»ҘеҮ ж¬Ў 2 еҲ° 1
for ( int sz = 1; sz < n ; sz += sz)
for (int i = 1; i < n; i++)
cout<< "Hello,дә”еҲҶй’ҹеӯҰз®—жі•пјҡпјү"<< endl;
}O(nlogn)
е°Ҷж—¶й—ҙеӨҚжқӮеәҰдёәO(logn)зҡ„д»Јз ҒеҫӘзҺҜNйҒҚзҡ„иҜқпјҢйӮЈд№Ҳе®ғзҡ„ж—¶й—ҙеӨҚжқӮеәҰе°ұжҳҜ n * O(logn)пјҢд№ҹе°ұжҳҜдәҶO(nlogn)гҖӮ
void hello (){
for( m = 1 ; m < n ; m++){
i = 1;
while( i < n ){
i = i * 2;
}
}
}дёҚеёёи§Ғзҡ„ж—¶й—ҙеӨҚжқӮеәҰ
дёӢйқўжқҘеҲҶжһҗдёҖжіўеҸҰеӨ–еҮ з§ҚеӨҚжқӮеәҰпјҡ йҖ’еҪ’з®—жі•зҡ„ж—¶й—ҙеӨҚжқӮеәҰпјҲrecursive algorithm time complexityпјүпјҢжңҖеҘҪжғ…еҶөж—¶й—ҙеӨҚжқӮеәҰпјҲbest case time complexityпјүгҖҒжңҖеқҸжғ…еҶөж—¶й—ҙеӨҚжқӮеәҰпјҲworst case time complexityпјүгҖҒе№іеқҮж—¶й—ҙеӨҚжқӮеәҰпјҲaverage case time complexityпјүе’ҢеқҮж‘Ҡж—¶й—ҙеӨҚжқӮеәҰпјҲamortized time complexityпјүгҖӮ
йҖ’еҪ’з®—жі•зҡ„ж—¶й—ҙеӨҚжқӮеәҰ
еҰӮжһңйҖ’еҪ’еҮҪж•°дёӯпјҢеҸӘиҝӣиЎҢдёҖж¬ЎйҖ’еҪ’и°ғз”ЁпјҢйҖ’еҪ’ж·ұеәҰдёәdepthпјӣ
еңЁжҜҸдёӘйҖ’еҪ’зҡ„еҮҪж•°дёӯпјҢж—¶й—ҙеӨҚжқӮеәҰдёәTпјӣ
еҲҷжҖ»дҪ“зҡ„ж—¶й—ҙеӨҚжқӮеәҰдёәO(T * depth)гҖӮ
еңЁеүҚйқўзҡ„еӯҰд№ дёӯпјҢеҪ’并жҺ’еәҸ дёҺ еҝ«йҖҹжҺ’еәҸ йғҪеёҰжңүйҖ’еҪ’зҡ„жҖқжғіпјҢ并且时й—ҙеӨҚжқӮеәҰйғҪжҳҜO(nlogn) пјҢдҪҶ并дёҚжҳҜжңүйҖ’еҪ’зҡ„еҮҪж•°е°ұдёҖе®ҡжҳҜ O(nlogn) зә§еҲ«зҡ„гҖӮд»Һд»ҘдёӢдёӨз§Қжғ…еҶөиҝӣиЎҢеҲҶжһҗгҖӮ
в‘ йҖ’еҪ’дёӯиҝӣиЎҢдёҖж¬ЎйҖ’еҪ’и°ғз”Ёзҡ„еӨҚжқӮеәҰеҲҶжһҗ
дәҢеҲҶжҹҘжүҫжі•
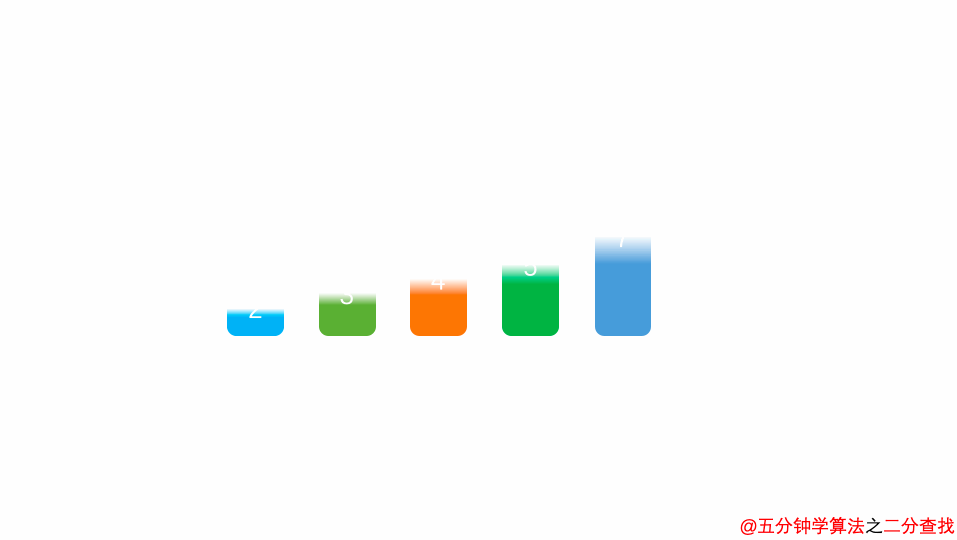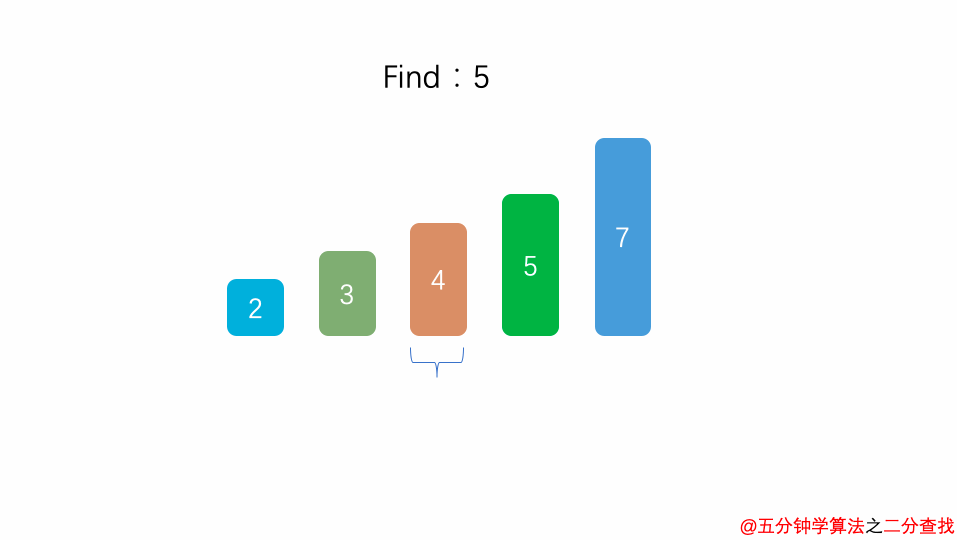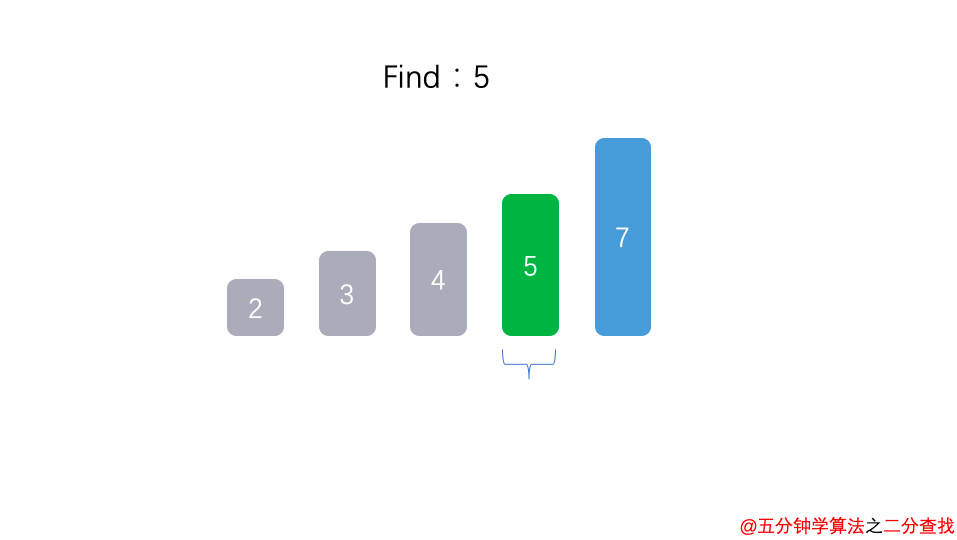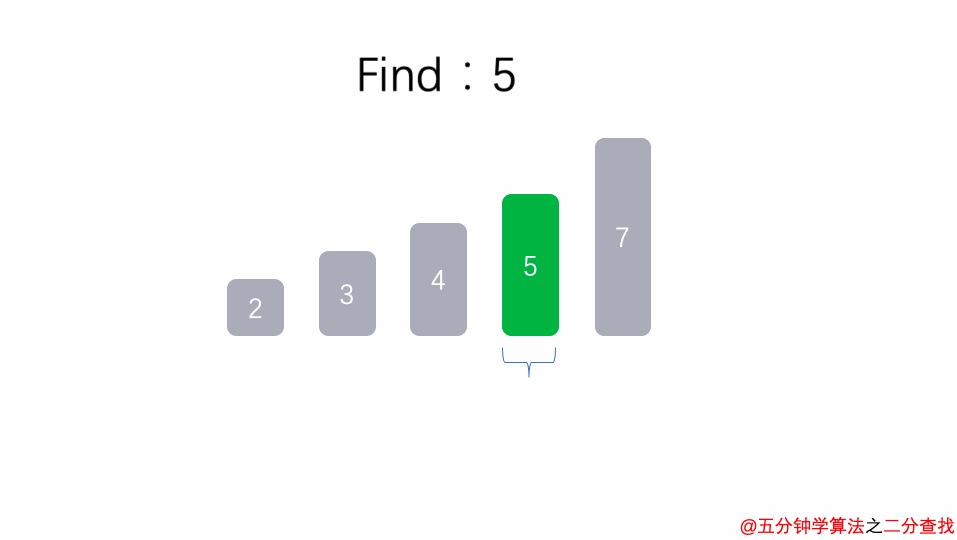
int binarySearch(int arr[], int l, int r, int target){
if( l > r ) return -1;
int mid = l + (r-l)/2;
if( arr[mid] == target ) return mid;
else if( arr[mid] > target )
return binarySearch(arr, l, mid-1, target); // е·Ұиҫ№
else
return binarySearch(arr, mid+1, r, target); // еҸіиҫ№
}жҜ”еҰӮеңЁиҝҷж®өдәҢеҲҶжҹҘжүҫжі•зҡ„д»Јз ҒдёӯпјҢжҜҸж¬ЎеңЁ [ l , r ] иҢғеӣҙдёӯеҺ»жҹҘжүҫзӣ®ж Үзҡ„дҪҚзҪ®пјҢеҰӮжһңдёӯй—ҙзҡ„е…ғзҙ arr[mid]дёҚжҳҜtargetпјҢйӮЈд№ҲеҲӨж–ӯarr[mid]жҳҜжҜ”targetеӨ§ иҝҳжҳҜ е°Ҹ пјҢиҝӣиҖҢеҶҚж¬Ўи°ғз”ЁbinarySearchиҝҷдёӘеҮҪж•°гҖӮ
еңЁиҝҷдёӘйҖ’еҪ’еҮҪж•°дёӯпјҢжҜҸдёҖж¬ЎжІЎжңүжүҫеҲ°targetж—¶пјҢиҰҒд№Ҳи°ғз”Ё е·Ұиҫ№ зҡ„binarySearchеҮҪж•°пјҢиҰҒд№Ҳи°ғз”Ё еҸіиҫ№ зҡ„binarySearchеҮҪж•°гҖӮд№ҹе°ұжҳҜиҜҙеңЁжӯӨж¬ЎйҖ’еҪ’дёӯпјҢжңҖеӨҡи°ғз”ЁдәҶдёҖж¬ЎйҖ’еҪ’и°ғз”ЁиҖҢе·ІгҖӮж №жҚ®ж•°еӯҰзҹҘиҜҶпјҢйңҖиҰҒlog2nж¬ЎжүҚиғҪйҖ’еҪ’еҲ°еә•гҖӮеӣ жӯӨпјҢдәҢеҲҶжҹҘжүҫжі•зҡ„ж—¶й—ҙеӨҚжқӮеәҰдёә O(logn)гҖӮ
жұӮе’Ң

int sum (int n) {
if (n == 0) return 0;
return n + sum( n - 1 )
}еңЁиҝҷж®өд»Јз ҒдёӯжҜ”иҫғе®№жҳ“зҗҶи§ЈйҖ’еҪ’ж·ұеәҰйҡҸиҫ“е…Ҙ n зҡ„еўһеҠ иҖҢзәҝжҖ§йҖ’еўһпјҢеӣ жӯӨж—¶й—ҙеӨҚжқӮеәҰдёә O (n)гҖӮ
жұӮе№Ӯ

//йҖ’еҪ’ж·ұеәҰпјҡlogn
//ж—¶й—ҙеӨҚжқӮеәҰпјҡO(logn)
double pow( double x, int n){
if (n == 0) return 1.0;
double t = pow(x,n/2);
if (n %2) return x*t*t;
return t * t;
}йҖ’еҪ’ж·ұеәҰдёәlognпјҢеӣ дёәжҳҜжұӮйңҖиҰҒйҷӨд»Ҙ 2 еӨҡе°‘ж¬ЎжүҚиғҪеҲ°еә•гҖӮ
в‘Ў йҖ’еҪ’дёӯиҝӣиЎҢеӨҡж¬ЎйҖ’еҪ’и°ғз”Ёзҡ„еӨҚжқӮеәҰеҲҶжһҗ
йҖ’еҪ’з®—жі•дёӯжҜ”иҫғйҡҫи®Ўз®—зҡ„жҳҜеӨҡж¬ЎйҖ’еҪ’и°ғз”ЁгҖӮ
е…ҲзңӢдёӢйқўиҝҷж®өд»Јз ҒпјҢжңүдёӨж¬ЎйҖ’еҪ’и°ғз”ЁгҖӮ
// O(2^n) жҢҮж•°зә§еҲ«зҡ„ж•°йҮҸзә§пјҢеҗҺз»ӯеҠЁжҖҒ规еҲ’зҡ„дјҳеҢ–зӮ№
int f(int n){
if (n == 0) return 1;
return f(n-1) + f(n - 1);
}
дёҺд№ӢжңүжүҖзұ»дјјзҡ„жҳҜ еҪ’并жҺ’еәҸ зҡ„йҖ’еҪ’ж ‘пјҢеҢәеҲ«зӮ№еңЁдәҺ
1. дёҠиҝ°дҫӢеӯҗдёӯж ‘зҡ„ж·ұеәҰдёәnпјҢиҖҢ еҪ’并жҺ’еәҸ зҡ„йҖ’еҪ’ж ‘ж·ұеәҰдёәlognгҖӮ
2. дёҠиҝ°дҫӢеӯҗдёӯжҜҸж¬ЎеӨ„зҗҶзҡ„ж•°жҚ®и§„жЁЎжҳҜдёҖж ·зҡ„пјҢиҖҢеңЁ еҪ’并жҺ’еәҸ дёӯжҜҸдёӘиҠӮзӮ№еӨ„зҗҶзҡ„ж•°жҚ®и§„жЁЎжҳҜйҖҗжёҗзј©е°Ҹзҡ„
еӣ жӯӨпјҢеңЁеҰӮ еҪ’并жҺ’еәҸ зӯүжҺ’еәҸз®—жі•дёӯпјҢжҜҸдёҖеұӮеӨ„зҗҶзҡ„ж•°жҚ®йҮҸдёә O(n) зә§еҲ«пјҢеҗҢж—¶жңүlognеұӮпјҢж—¶й—ҙеӨҚжқӮеәҰдҫҝжҳҜ O(nlogn)гҖӮ
жңҖеҘҪгҖҒжңҖеқҸжғ…еҶөж—¶й—ҙеӨҚжқӮеәҰ

жңҖеҘҪгҖҒжңҖеқҸжғ…еҶөж—¶й—ҙеӨҚжқӮеәҰжҢҮзҡ„жҳҜзү№ж®Ҡжғ…еҶөдёӢзҡ„ж—¶й—ҙеӨҚжқӮеәҰгҖӮ
еҠЁеӣҫиЎЁжҳҺзҡ„жҳҜеңЁж•°з»„ array дёӯеҜ»жүҫеҸҳйҮҸ x 第дёҖж¬ЎеҮәзҺ°зҡ„дҪҚзҪ®пјҢиӢҘжІЎжңүжүҫеҲ°пјҢеҲҷиҝ”еӣһ -1пјӣеҗҰеҲҷиҝ”еӣһдҪҚзҪ®дёӢж ҮгҖӮ
int find(int[] array, int n, int x) {
for ( int i = 0 ; i < n; i++) {
if (array[i] == x) {
return i;
break;
}
}
return -1;
}еңЁиҝҷйҮҢеҪ“ж•°з»„дёӯ第дёҖдёӘе…ғзҙ е°ұжҳҜиҰҒжүҫзҡ„ x ж—¶пјҢж—¶й—ҙеӨҚжқӮеәҰжҳҜ O(1)пјӣиҖҢеҪ“жңҖеҗҺдёҖдёӘе…ғзҙ жүҚжҳҜ x ж—¶пјҢж—¶й—ҙеӨҚжқӮеәҰеҲҷжҳҜ O(n)гҖӮ
жңҖеҘҪжғ…еҶөж—¶й—ҙеӨҚжқӮеәҰе°ұжҳҜеңЁжңҖзҗҶжғіжғ…еҶөдёӢжү§иЎҢд»Јз Ғзҡ„ж—¶й—ҙеӨҚжқӮеәҰпјҢе®ғзҡ„ж—¶й—ҙжҳҜжңҖзҹӯзҡ„пјӣжңҖеқҸжғ…еҶөж—¶й—ҙеӨҚжқӮеәҰе°ұжҳҜеңЁжңҖзіҹзі•жғ…еҶөдёӢжү§иЎҢд»Јз Ғзҡ„ж—¶й—ҙеӨҚжқӮеәҰпјҢе®ғзҡ„ж—¶й—ҙжҳҜжңҖй•ҝзҡ„гҖӮ
е№іеқҮжғ…еҶөж—¶й—ҙеӨҚжқӮеәҰ
жңҖеҘҪгҖҒжңҖеқҸж—¶й—ҙеӨҚжқӮеәҰеҸҚеә”зҡ„жҳҜжһҒз«ҜжқЎд»¶дёӢзҡ„еӨҚжқӮеәҰпјҢеҸ‘з”ҹзҡ„жҰӮзҺҮдёҚеӨ§пјҢдёҚиғҪд»ЈиЎЁе№іеқҮж°ҙе№ігҖӮйӮЈд№ҲдёәдәҶжӣҙеҘҪзҡ„иЎЁзӨәе№іеқҮжғ…еҶөдёӢзҡ„з®—жі•еӨҚжқӮеәҰпјҢе°ұйңҖиҰҒеј•е…Ҙе№іеқҮж—¶й—ҙеӨҚжқӮеәҰгҖӮ
е№іеқҮжғ…еҶөж—¶й—ҙеӨҚжқӮеәҰеҸҜз”Ёд»Јз ҒеңЁжүҖжңүеҸҜиғҪжғ…еҶөдёӢжү§иЎҢж¬Ўж•°зҡ„еҠ жқғе№іеқҮеҖјиЎЁзӨәгҖӮ
иҝҳжҳҜд»ҘfindеҮҪж•°дёәдҫӢпјҢд»ҺжҰӮзҺҮзҡ„и§’еәҰзңӢпјҢ x еңЁж•°з»„дёӯжҜҸдёҖдёӘдҪҚзҪ®зҡ„еҸҜиғҪжҖ§жҳҜзӣёеҗҢзҡ„пјҢдёә 1 / nгҖӮйӮЈд№ҲпјҢйӮЈд№Ҳе№іеқҮжғ…еҶөж—¶й—ҙеӨҚжқӮеәҰе°ұеҸҜд»Ҙз”ЁдёӢйқўзҡ„ж–№ејҸи®Ўз®—пјҡ
((1 + 2 + вҖҰ + n) / n + n) / 2 = (3n + 1) / 4
findеҮҪж•°зҡ„е№іеқҮж—¶й—ҙеӨҚжқӮеәҰдёә O(n)гҖӮ
еқҮж‘ҠеӨҚжқӮеәҰеҲҶжһҗ
жҲ‘们йҖҡиҝҮдёҖдёӘеҠЁжҖҒж•°з»„зҡ„push_backж“ҚдҪңжқҘзҗҶи§ЈеқҮж‘ҠеӨҚжқӮеәҰгҖӮ

template <typename T>
class MyVector{
private:
T* data;
int size; // еӯҳеӮЁж•°з»„дёӯзҡ„е…ғзҙ дёӘж•°
int capacity; // еӯҳеӮЁж•°з»„дёӯеҸҜд»Ҙе®№зәізҡ„жңҖеӨ§зҡ„е…ғзҙ дёӘж•°
// еӨҚжқӮеәҰдёә O(n)
void resize(int newCapacity){
T *newData = new T[newCapacity];
for( int i = 0 ; i < size ; i ++ ){
newData[i] = data[i];
}
data = newData;
capacity = newCapacity;
}
public:
MyVector(){
data = new T[100];
size = 0;
capacity = 100;
}
// е№іеқҮеӨҚжқӮеәҰдёә O(1)
void push_back(T e){
if(size == capacity)
resize(2 * capacity);
data[size++] = e;
}
// е№іеқҮеӨҚжқӮеәҰдёә O(1)
T pop_back(){
size --;
return data[size];
}
};push_backе®һзҺ°зҡ„еҠҹиғҪжҳҜеҫҖж•°з»„зҡ„жң«е°ҫеўһеҠ дёҖдёӘе…ғзҙ пјҢеҰӮжһңж•°з»„жІЎжңүж»ЎпјҢзӣҙжҺҘеҫҖеҗҺйқўжҸ’е…Ҙе…ғзҙ пјӣеҰӮжһңж•°з»„ж»ЎдәҶпјҢеҚіsize == capacityпјҢеҲҷе°Ҷж•°з»„жү©е®№дёҖеҖҚпјҢ然еҗҺеҶҚжҸ’е…Ҙе…ғзҙ гҖӮ
дҫӢеҰӮпјҢж•°з»„й•ҝеәҰдёә nпјҢеҲҷеүҚ n ж¬Ўи°ғз”Ёpush_backеӨҚжқӮеәҰйғҪдёә O(1) зә§еҲ«пјӣеңЁз¬¬ n + 1 ж¬ЎеҲҷйңҖиҰҒе…ҲиҝӣиЎҢ n ж¬Ўе…ғзҙ иҪ¬з§»ж“ҚдҪңпјҢ然еҗҺеҶҚиҝӣиЎҢ 1 ж¬ЎжҸ’е…Ҙж“ҚдҪңпјҢеӨҚжқӮеәҰдёә O(n)гҖӮ
еӣ жӯӨпјҢе№іеқҮжқҘзңӢпјҡеҜ№дәҺе®№йҮҸдёә n зҡ„еҠЁжҖҒж•°з»„пјҢеүҚйқўж·»еҠ е…ғзҙ йңҖиҰҒж¶ҲиҖ—дәҶ 1 * n зҡ„ж—¶й—ҙпјҢжү©е®№ж“ҚдҪңж¶ҲиҖ— n ж—¶й—ҙ пјҢ
жҖ»е…ұе°ұжҳҜ 2 * n зҡ„ж—¶й—ҙпјҢеӣ жӯӨеқҮж‘Ҡж—¶й—ҙеӨҚжқӮеәҰдёә O(2n / n) = O(2)пјҢд№ҹе°ұжҳҜ O(1) зә§еҲ«дәҶгҖӮ
еҸҜд»Ҙеҫ—еҮәдёҖдёӘжҜ”иҫғжңүж„ҸжҖқзҡ„з»“и®әпјҡдёҖдёӘзӣёеҜ№жҜ”иҫғиҖ—ж—¶зҡ„ж“ҚдҪңпјҢеҰӮжһңиғҪдҝқиҜҒе®ғдёҚдјҡжҜҸж¬ЎйғҪиў«и§ҰеҸ‘пјҢйӮЈд№ҲиҝҷдёӘзӣёеҜ№жҜ”иҫғиҖ—ж—¶зҡ„ж“ҚдҪңпјҢе®ғжүҖзӣёеә”зҡ„ж—¶й—ҙжҳҜеҸҜд»ҘеҲҶж‘ҠеҲ°е…¶е®ғзҡ„ж“ҚдҪңдёӯжқҘзҡ„гҖӮ
з©әй—ҙеӨҚжқӮеәҰ
дёҖдёӘзЁӢеәҸзҡ„з©әй—ҙеӨҚжқӮеәҰжҳҜжҢҮиҝҗиЎҢе®ҢдёҖдёӘзЁӢеәҸжүҖйңҖеҶ…еӯҳзҡ„еӨ§е°ҸгҖӮеҲ©з”ЁзЁӢеәҸзҡ„з©әй—ҙеӨҚжқӮеәҰпјҢеҸҜд»ҘеҜ№зЁӢеәҸзҡ„иҝҗиЎҢжүҖйңҖиҰҒзҡ„еҶ…еӯҳеӨҡе°‘жңүдёӘйў„е…Ҳдј°и®ЎгҖӮдёҖдёӘзЁӢеәҸжү§иЎҢж—¶йҷӨдәҶйңҖиҰҒеӯҳеӮЁз©әй—ҙе’ҢеӯҳеӮЁжң¬иә«жүҖдҪҝз”Ёзҡ„жҢҮд»ӨгҖҒеёёж•°гҖҒеҸҳйҮҸе’Ңиҫ“е…Ҙж•°жҚ®еӨ–пјҢиҝҳйңҖиҰҒдёҖдәӣеҜ№ж•°жҚ®иҝӣиЎҢж“ҚдҪңзҡ„е·ҘдҪңеҚ•е…ғе’ҢеӯҳеӮЁдёҖдәӣдёәзҺ°е®һи®Ўз®—жүҖйңҖдҝЎжҒҜзҡ„иҫ…еҠ©з©әй—ҙгҖӮзЁӢеәҸжү§иЎҢж—¶жүҖйңҖеӯҳеӮЁз©әй—ҙеҢ…жӢ¬д»ҘдёӢдёӨйғЁеҲҶпјҡ
(1) еӣәе®ҡйғЁеҲҶпјҢиҝҷйғЁеҲҶз©әй—ҙзҡ„еӨ§е°ҸдёҺиҫ“е…Ҙ/иҫ“еҮәзҡ„ж•°жҚ®зҡ„дёӘж•°еӨҡе°‘гҖҒж•°еҖјж— е…ігҖӮдё»иҰҒеҢ…жӢ¬жҢҮд»Өз©әй—ҙпјҲеҚід»Јз Ғз©әй—ҙпјүгҖҒж•°жҚ®з©әй—ҙпјҲеёёйҮҸгҖҒз®ҖеҚ•еҸҳйҮҸпјүзӯүжүҖеҚ зҡ„з©әй—ҙгҖӮиҝҷйғЁеҲҶеұһдәҺйқҷжҖҒз©әй—ҙгҖӮ
(2) еҸҜеҸҳз©әй—ҙпјҢиҝҷйғЁеҲҶз©әй—ҙзҡ„дё»иҰҒеҢ…жӢ¬еҠЁжҖҒеҲҶй…Қзҡ„з©әй—ҙпјҢд»ҘеҸҠйҖ’еҪ’ж ҲжүҖйңҖзҡ„з©әй—ҙзӯүгҖӮиҝҷйғЁеҲҶзҡ„з©әй—ҙеӨ§е°ҸдёҺз®—жі•жңүе…ігҖӮ
дёҖдёӘз®—жі•жүҖйңҖзҡ„еӯҳеӮЁз©әй—ҙз”Ёf(n)иЎЁзӨәгҖӮS(n)=O(f(n))пјҢе…¶дёӯnдёәй—®йўҳзҡ„规模пјҢS(n)иЎЁзӨәз©әй—ҙеӨҚжқӮеәҰгҖӮ
з©әй—ҙеӨҚжқӮеәҰеҸҜд»ҘзҗҶи§ЈдёәйҷӨдәҶеҺҹе§ӢеәҸеҲ—еӨ§е°Ҹзҡ„еҶ…еӯҳпјҢеңЁз®—жі•иҝҮзЁӢдёӯз”ЁеҲ°зҡ„йўқеӨ–зҡ„еӯҳеӮЁз©әй—ҙгҖӮ
д»ҘдәҢеҸүжҹҘжүҫж ‘дёәдҫӢпјҢдёҫдҫӢиҜҙжҳҺдәҢеҸүжҺ’еәҸж ‘зҡ„жҹҘжүҫжҖ§иғҪгҖӮ
е№іиЎЎдәҢеҸүж ‘
еҰӮжһңдәҢеҸүж ‘зҡ„жҳҜд»Ҙзәўй»‘ж ‘зӯүе№іиЎЎдәҢеҸүж ‘е®һзҺ°зҡ„пјҢеҲҷ n дёӘиҠӮзӮ№зҡ„дәҢеҸүжҺ’еәҸж ‘зҡ„й«ҳеәҰдёә log2n+1 пјҢе…¶жҹҘжүҫж•ҲзҺҮдёәO(Log2n)пјҢиҝ‘дјјдәҺжҠҳеҚҠжҹҘжүҫгҖӮ
еҲ—иЎЁдәҢеҸүж ‘
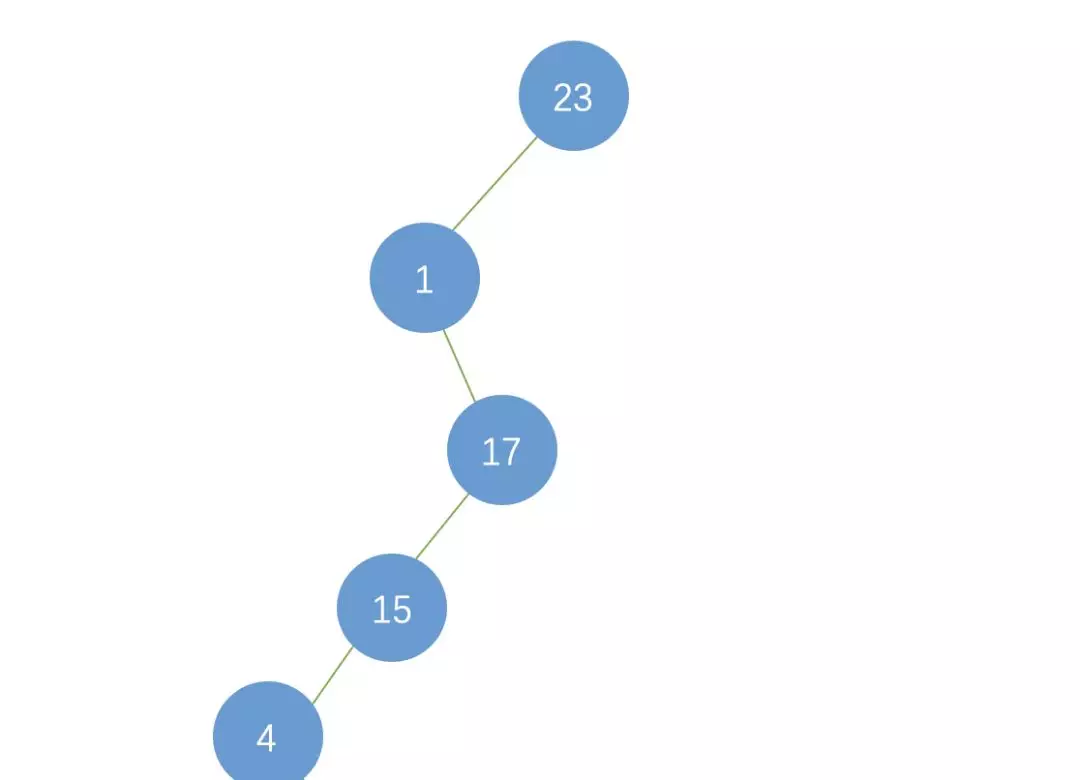
еҰӮжһңдәҢеҸүж ‘йҖҖеҸҳдёәеҲ—иЎЁдәҶпјҢеҲҷ n дёӘиҠӮзӮ№зҡ„й«ҳеәҰжҲ–иҖ…иҜҙжҳҜй•ҝеәҰеҸҳдёәдәҶnпјҢжҹҘжүҫж•ҲзҺҮдёәO(n)пјҢеҸҳжҲҗдәҶйЎәеәҸжҹҘжүҫгҖӮ
дёҖиҲ¬дәҢеҸүж ‘
д»ӢдәҺгҖҢеҲ—иЎЁдәҢеҸүж ‘гҖҚдёҺгҖҢе№іиЎЎдәҢеҸүж ‘гҖҚд№Ӣй—ҙпјҢжҹҘжүҫжҖ§иғҪд№ҹеңЁO(Log2n)еҲ°O(n)д№Ӣй—ҙгҖӮ
еҶ°зҒ«дәӨиһҚ
еҜ№дәҺдёҖдёӘз®—жі•пјҢе…¶ж—¶й—ҙеӨҚжқӮеәҰе’Ңз©әй—ҙеӨҚжқӮеәҰеҫҖеҫҖжҳҜзӣёдә’еҪұе“Қзҡ„гҖӮ
жҜ”еҰӮиҜҙпјҢиҰҒеҲӨж–ӯжҹҗжҹҗе№ҙжҳҜдёҚжҳҜй—°е№ҙпјҡ
1. еҸҜд»Ҙзј–еҶҷдёҖдёӘз®—жі•жқҘи®Ўз®—пјҢиҝҷд№ҹе°ұж„Ҹе‘ізқҖпјҢжҜҸж¬Ўз»ҷдёҖдёӘе№ҙд»ҪпјҢйғҪжҳҜиҰҒйҖҡиҝҮи®Ўз®—еҫ—еҲ°жҳҜеҗҰжҳҜй—°е№ҙзҡ„з»“жһңгҖӮ
2. иҝҳжңүеҸҰдёҖдёӘеҠһжі•е°ұжҳҜпјҢдәӢе…Ҳе»әз«ӢдёҖдёӘжңү 5555 дёӘе…ғзҙ зҡ„ж•°з»„пјҲе№ҙж•°жҜ”зҺ°е®һеӨҡе°ұиЎҢпјүпјҢ然еҗҺжҠҠжүҖжңүзҡ„е№ҙд»ҪжҢүдёӢж Үзҡ„ж•°еӯ—еҜ№еә”пјҢеҰӮжһңжҳҜй—°е№ҙпјҢжӯӨж•°з»„йЎ№зҡ„еҖје°ұжҳҜ1пјҢеҰӮжһңдёҚжҳҜеҖјдёә0гҖӮиҝҷж ·пјҢжүҖи°“зҡ„еҲӨж–ӯжҹҗдёҖе№ҙжҳҜеҗҰжҳҜй—°е№ҙпјҢе°ұеҸҳжҲҗдәҶжҹҘжүҫиҝҷдёӘж•°з»„зҡ„жҹҗдёҖйЎ№зҡ„еҖјжҳҜеӨҡе°‘зҡ„й—®йўҳгҖӮжӯӨж—¶пјҢжҲ‘们зҡ„иҝҗз®—жҳҜжңҖе°ҸеҢ–дәҶпјҢдҪҶжҳҜзЎ¬зӣҳдёҠжҲ–иҖ…еҶ…еӯҳдёӯйңҖиҰҒеӯҳеӮЁиҝҷ 5555 дёӘ 0 е’Ң 1 гҖӮ
иҝҷе°ұжҳҜе…ёеһӢзҡ„дҪҝз”Ёз©әй—ҙжҚўж—¶й—ҙзҡ„жҰӮеҝөгҖӮ
еҪ“иҝҪжұӮдёҖдёӘиҫғеҘҪзҡ„ж—¶й—ҙеӨҚжқӮеәҰж—¶пјҢеҸҜиғҪдјҡдҪҝз©әй—ҙеӨҚжқӮеәҰзҡ„жҖ§иғҪеҸҳе·®пјҢеҚіеҸҜиғҪеҜјиҮҙеҚ з”ЁиҫғеӨҡзҡ„еӯҳеӮЁз©әй—ҙпјӣ
еҸҚд№ӢпјҢжұӮдёҖдёӘиҫғеҘҪзҡ„з©әй—ҙеӨҚжқӮеәҰж—¶пјҢеҸҜиғҪдјҡдҪҝж—¶й—ҙеӨҚжқӮеәҰзҡ„жҖ§иғҪеҸҳе·®пјҢеҚіеҸҜиғҪеҜјиҮҙеҚ з”Ёиҫғй•ҝзҡ„иҝҗиЎҢж—¶й—ҙгҖӮ
еҸҰеӨ–пјҢз®—жі•зҡ„жүҖжңүжҖ§иғҪд№Ӣй—ҙйғҪеӯҳеңЁзқҖжҲ–еӨҡжҲ–е°‘зҡ„зӣёдә’еҪұе“ҚгҖӮеӣ жӯӨпјҢеҪ“и®ҫи®ЎдёҖдёӘз®—жі•(зү№еҲ«жҳҜеӨ§еһӢз®—жі•)ж—¶пјҢиҰҒз»јеҗҲиҖғиҷ‘з®—жі•зҡ„еҗ„йЎ№жҖ§иғҪпјҢз®—жі•зҡ„дҪҝз”Ёйў‘зҺҮпјҢз®—жі•еӨ„зҗҶзҡ„ж•°жҚ®йҮҸзҡ„еӨ§е°ҸпјҢз®—жі•жҸҸиҝ°иҜӯиЁҖзҡ„зү№жҖ§пјҢз®—жі•иҝҗиЎҢзҡ„жңәеҷЁзі»з»ҹзҺҜеўғзӯүеҗ„ж–№йқўеӣ зҙ пјҢжүҚиғҪеӨҹи®ҫи®ЎеҮәжҜ”иҫғеҘҪзҡ„з®—жі•гҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңжҖҺд№ҲзҗҶи§Јwebзҡ„ж—¶й—ҙдёҺз©әй—ҙеӨҚжқӮеәҰвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





