这篇文章主要为大家展示了“Python如何爬取实习僧招聘网站”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“Python如何爬取实习僧招聘网站”这篇文章吧。
本次任务背景:
https://www.shixiseng.com
爬取一下实习僧IT互联网的Python实习信息
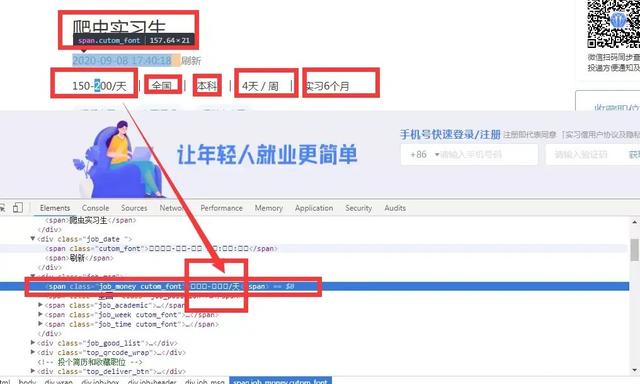
如上图所示,该字段的数据看不见,可能它不希望你很简单的就获得它网站的这些数据,这些数据对他来说比较重要,所以启用了反爬技巧
如果直接运行,这些数据是爬取不下来的,如下图:
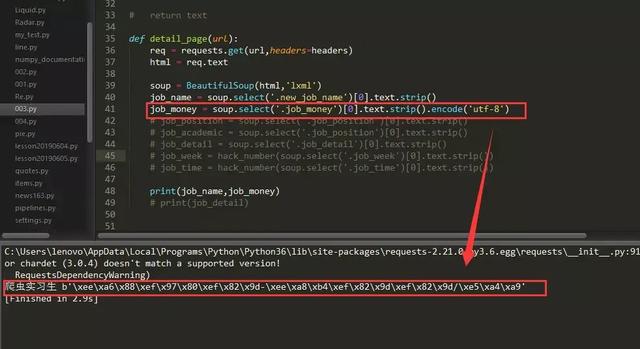
如上图,相关数据已经以“utf-8”编码的方式呈现出来
创建函数hack_number(),用于解码数字

编写好相关代码之后,查看运行结果
完整代码如下:
import requests
from bs4 import BeautifulSoup
headers = {"user-agent":"Mozilla/5.0"}
def hack_number(text):
text = text.encode('utf-8')
text = text.replace(b'\xef\x82\x9d', b'0')
text = text.replace(b'\xee\xa6\x88', b'1')
text = text.replace(b'\xee\xa8\xb4', b'2')
text = text.replace(b'\xef\x91\xbe', b'3')
text = text.replace(b'\xee\x88\x9d', b'4')
text = text.replace(b'\xef\x97\x80', b'5')
text = text.replace(b'\xee\x85\x9f', b'6')
text = text.replace(b'\xee\x98\x92', b'7')
text = text.replace(b'\xef\x80\x95', b'8')
text = text.replace(b'\xef\x94\x9b', b'9')
text = text.decode()
return text
def detail_page(url):
req = requests.get(url,headers=headers)
html = req.text
soup = BeautifulSoup(html,'lxml')
job_name = soup.select('.new_job_name')[0].text.strip()
job_money = hack_number(soup.select('.job_money')[0].text.strip())
job_position = soup.select('.job_position')[0].text.strip()
job_academic = soup.select('.job_academic')[0].text.strip()
job_detail = soup.select('.job_detail')[0].text.strip()
job_week = hack_number(soup.select('.job_week')[0].text.strip())
job_time = hack_number(soup.select('.job_time')[0].text.strip())
print(job_name,job_money,job_position,job_academic,job_week,job_time)
print(job_detail)
#detail_page('https://www.shixiseng.com/intern/inn_1k3vhcwwguaf?pcm=pc_SearchList')
#detail_page('https://www.shixiseng.com/intern/inn_uk1lm380lngh?pcm=pc_SearchList')
#detail_page('https://www.shixiseng.com/intern/inn_fr1o1nii5knw?pcm=pc_SearchList')
for pages in range(1,3):
url = f'https://www.shixiseng.com/interns?page={pages}&keyword=Python&type=intern&area=&months=&days=°ree=&official=&enterprise=&salary=-0&publishTime=&sortType=&city=%E8%B4%B5%E9%98%B3&internExtend='
req = requests.get(url,headers=headers)
html = req.text
soup = BeautifulSoup(html,'lxml')
for item in soup.select('a.title ellipsis font'):
detail_url = f"https://www.shixiseng.com{item.get('href')}"
detail_page(detail_url)以上是“Python如何爬取实习僧招聘网站”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4848094/blog/4745788



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



