Python如何爬取熊猫办公音频素材数据,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
python 3.6
pycharm
requests
parsel
相关模块pip安装即可
import requests
url = 'https://www.tukuppt.com/peiyue/zonghe_0_0_0_0_0_0_1.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
123456import parsel
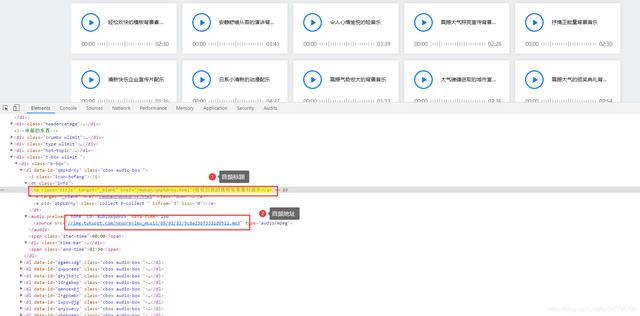
selector = parsel.Selector(response.text)
urls = selector.css('#audio850995 source::attr(src)').getall()
titles = selector.css('.b-box .info .title::text').getall()
data = zip(urls, titles)
for i in data:
mp3_url = 'https:' + i[0]
title = i[1]
12345678def download(url, title): response = requests.get(url=url, headers=headers) path = 'D:\\python\\demo\\熊猫办公素材\\背景音乐\\' + title + '.mp3' with open(path, mode='wb') as f: f.write(response.content) 12345

看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





