这篇文章主要讲解了“Python中怎么使用Pandas实现数据清洗后的数据整合”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Python中怎么使用Pandas实现数据清洗后的数据整合”吧!
Pandas合并数据
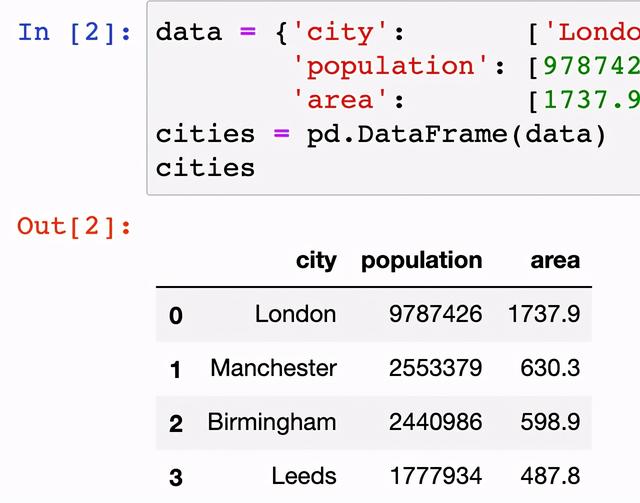
组合或合并数据时,pandas 有几个不同选项。在 Jupyter的Notebook中,创建两个新的数据帧并合并数据。可以使用 append() 来合并这些数据帧。【案例】将城市名,人口和面积的两组数据合并。
import pandas as pd
data = {'city':['London','Manchester','Birmingham','Leeds','Glasgow'],
'population': [9787426, 2553379,2440986,1777934,1209143],
'area':[1737.9,630.3,598.9,487.8, 368.5 ]}
cities = pd.DataFrame(data)
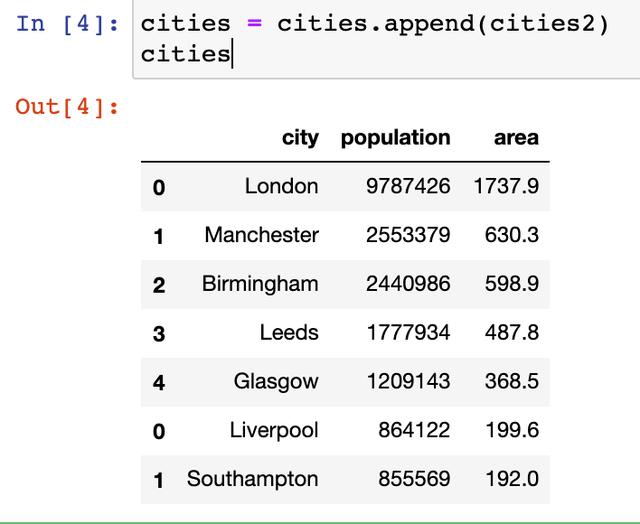
data2 = {'city':['Liverpool','Southampton'],
'population': [864122, 855569],
'area':[199.6, 192.0]}
cities2 = pd.DataFrame(data2)
cities = cities.append(cities2)
cities其操作是“data1 = data1.append(data2)” 将data2连接到data1的尾部。再赋值给data1。要注意data1和data2应具有相同的结构。
B..concat()
frames = [cities, cities2] df = pd.concat(frames) df
像其在ndarray上的同级函数一样numpy.concatenate(),pandas.concat()采用同类对象的列表或字典。
frames = [cities, cities2] df = pd.concat(frames, keys=['x', 'y']) df
加入关键字keys参数进行不同数据来源的区分。
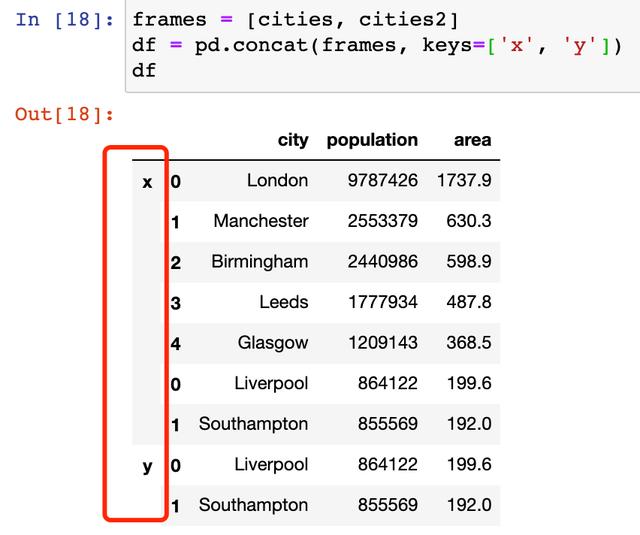
然后可以根据数据来源直接查看定位所需的数据。
df.loc['y']
感谢各位的阅读,以上就是“Python中怎么使用Pandas实现数据清洗后的数据整合”的内容了,经过本文的学习后,相信大家对Python中怎么使用Pandas实现数据清洗后的数据整合这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





