在自己的扫描器开发过程中,扫描器当中自然包括了子域名收集功能,但在遇到泛解析的网站时,也增加了扫描器很多不必要的检测,导致效率和资源的浪费。本文中主要针对扫描器遇到的问题进行解决并优化。
泛域名解析介绍 https://baike.baidu.com/item/%E6%B3%9B%E5%9F%9F%E5%90%8D%E8%A7%A3%E6%9E%90/9845966?fr=aladdin
泛解析的功能为厂商提供了便利,但为自动化扫描带来了麻烦,什么麻烦呢?这里以一个使用了泛解析的厂商作为演示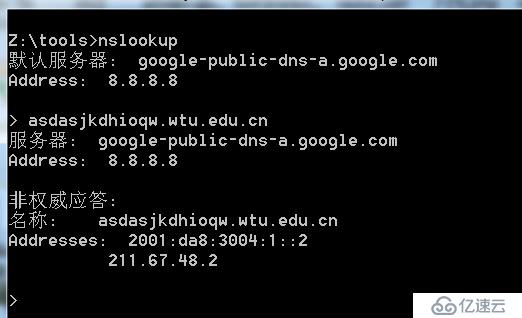
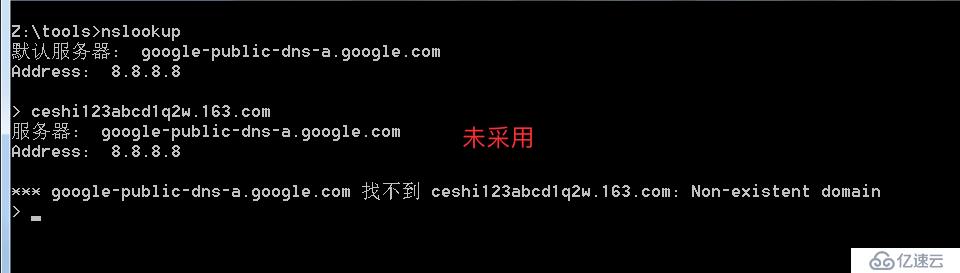
由于该网站使用了泛解析,导致原本不存在的子域名也会成功被解析,那么其实访问这个域名,会重定向到主页
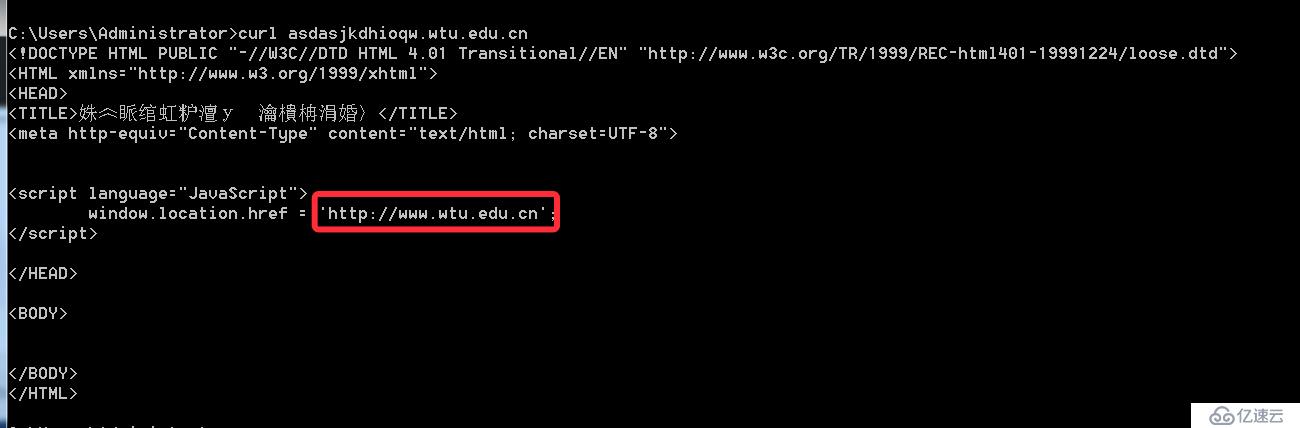
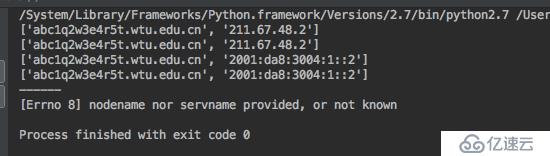
那么在自动化扫描中,通常我们会使用到一个字典组合域名的方式,然后进行dns解析,如果成功解析说明子域名存在,利用这种方式来进行子域名穷举,但使用泛解析的话,则会导致所有的域名都能成功解析,使得子域名穷举变得不精准。
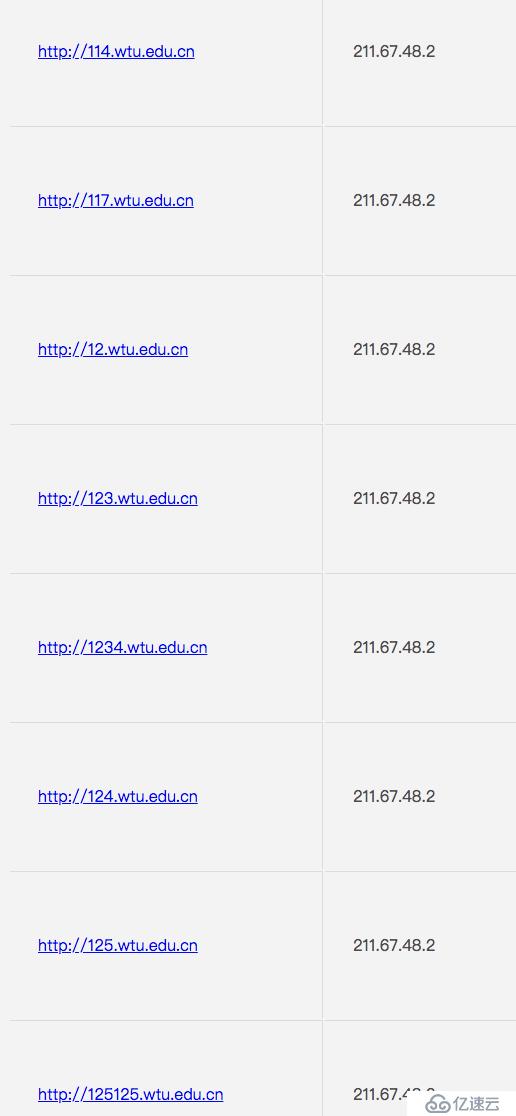
ps:只是一个泛解析测试
那么怎么去判断域名使用了泛解析和如何解决扫描器中遇到这种情况呢?
泛解析的域名会自动匹配所有*.域名的解析,利用这点我们可以故意去解析一个根本不可能存在的域名,如果能成功解析代表使用泛解析,否之未采用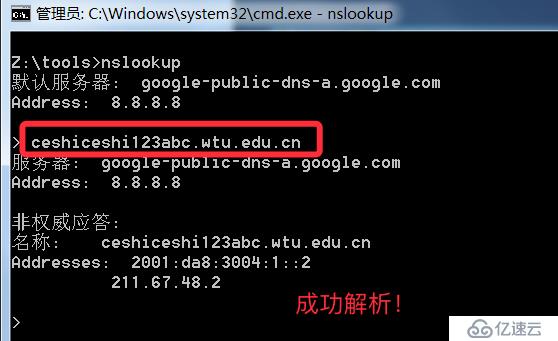
import socket
import sys
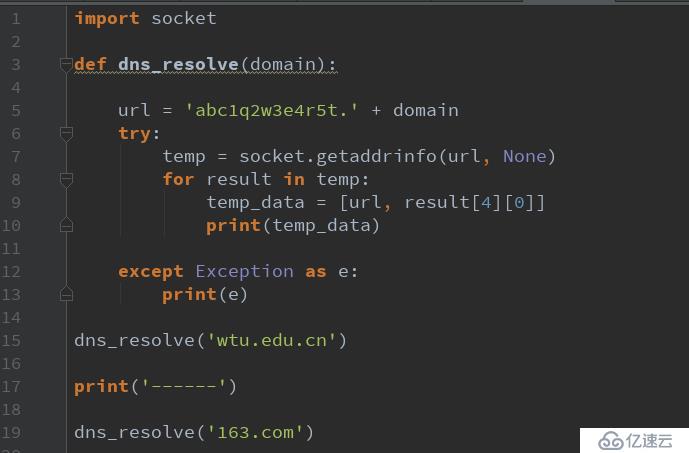
def dns_resolve(domain):
url = 'abc1q2w3e4r5t.' + domain
flag = False
#抛出异常说明使用了泛解析
try:
socket.getaddrinfo(url, None)
flag = True
except:
pass
if not flag:
print('[+] %s 未采用泛解析'%domain)
else:
print('[-] %s 采用泛解析'%domain)
if __name__ == '__main__':
if len(sys.argv) < 2:
print('python3 %s <domain>'%sys.argv[0])
exit(1)
dns_resolve(sys.argv[1])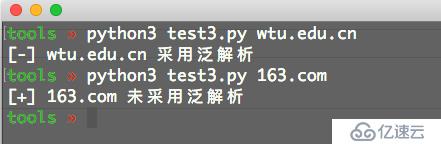
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





