这期内容当中小编将会给大家带来有关如何理解Fedlearner,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
Fedlearner
这次头条开源的Fedlearner与我之前分析过得华为、微众的联邦机器学习平台有什么不同呢?主要体现在以下几个方面:
产品化:Fedlearner的代码里有大量的js、Html模块,也是第一次让我们可以直观的看到联邦机器学习平台大概是什么样的,如果做成产品需要长成什么样。
业务多样化:之前华为、微众更多地强调联邦机器学习在风控业务的落地。头条开始强调联邦学习在推荐、广告等业务中的落地,并且给了很明确的数据,在某教育业务板块广告投放效果增加209%。
可输出性:如果说之前的联邦机器学习平台更多地从理论层面做介绍,这一次字节的Fedlearner强调了可输出性,比如为了保持联邦建模双方的环境一致性,通过K8S的部署模式快速拉起和管理集群。这是为ToB对外输出服务做技术准备。
下面分别介绍下Fedlearner在这三方面的一些工作。
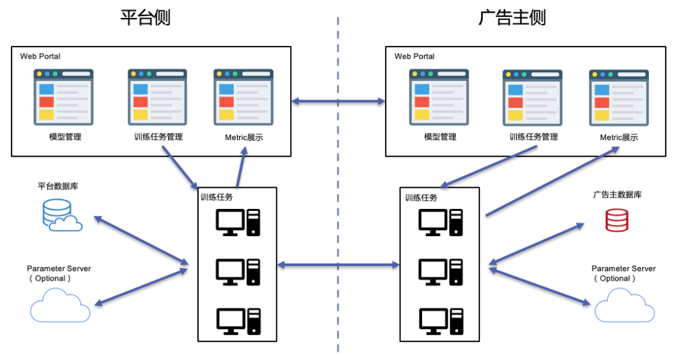
以推荐广告业务为例,联邦机器学习平台的广告主和平台方应该各自管理一套模型展示服务和模型训练服务。
需要有两套协议保证客户的联邦建模,一套是数据一致性问题。比如在纵向联邦学习场景下,用户在页面上点击了某个广告,平台方和广告主各自会捕获一部分日志。如何能实时的保证这两部分捕获的日志的一致性,并且拼接成训练样本,需要一套实时数据样本拼接协议。
另一个协议是多方数据安全协议。比如AB两个业务方,A有4亿用户,B有3亿用户,如何做到通过某种方式找到A和B的交叉用户,并且不让A和B互相猜到对方的数据,需要有一套多方数据安全协议。
基于以上两套协议,在双方联合建模过程中,使用GRPC通信,利用TensorFlow做双方梯度的交换进行联合建模。
联邦机器学习的最大业务场景在推荐广告,这个我在一年前的文章中有预测过。果然头条特别强调了推荐场景的应用。他提到了推荐业务更适合神经网络算法,风控业务适合树形算法。作者也比较认同这样的说法,因为风控需要高可解释性,树形算法天然满足这样的需求。而推荐业务对模型可解释性要求不高,神经网络算法的复杂性可以充分保证推荐排序算法的准确率。
Fedlearner业务负责人给了一组数字可以证明联邦机器学习在推荐业务中的落地效果。
这组数组还是非常有说服力的。其实对于新技术,很多时候面对的壁垒不是技术问题,而是如何证明业务价值,需要第一个吃螃蟹的人,才能推动新技术在行业的落地。联邦机器学习在推荐广告业务中大有可为。
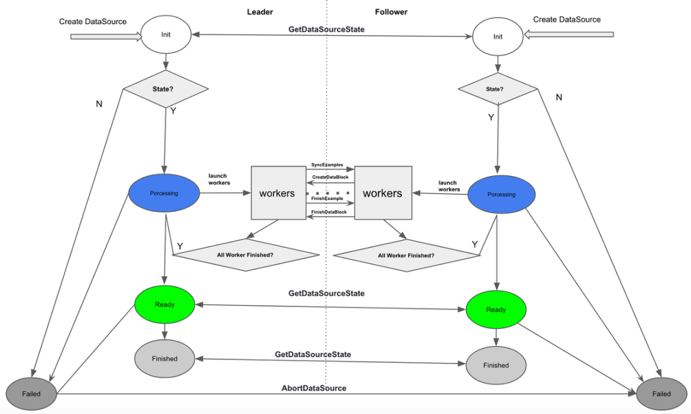
Fedlearner采用的是一套云原生的部署方案。数据存放在HDFS,用MySQL存储系统数据。通过Kubernetes管理和拉起任务。每个Fedlearner的训练任务需要参与双方同时拉起K8S任务,通过Master节点统一管理,Worker建实现通信。
这套方案充分考虑了当前做推荐业务的用户的数仓兼容性,因为大部分客户的数仓体系还是Hadoop生态,数据存储在HDFS。同时用K8S又最大限度的保证了联合建模双方计算引擎环境的一致性。
上述就是小编为大家分享的如何理解Fedlearner了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





