这篇文章主要介绍“Python基础语法和数据类型总结”,在日常操作中,相信很多人在Python基础语法和数据类型总结问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Python基础语法和数据类型总结”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
Python最全基础总结
集合操作
集合运算
字典类型操作方法
list
list操作函数
编写第一个程序
Python中的注释
Python代码基本架构
数据类型
运算符
内置函数
字符串类型
使用%占位符格式化字符串
使用format()函数格式化字符串
使用f-string来格式化字符串
字符串操作
list和tuple
tuple
字典类型
集合类型
哈哈,入门语言,当然第一句话就是hello world,相比于C和Java,Python的语法格式非常简单,直接print()即可
下面我们开始写第一个程序:输出Hello World!

它会输出一个字符串”Hello World!“。
如果多次调用print()函数,如下:

可以看到,每条print()语句,都会占一行。如果想将上面的三句话输出到同一行,可以这样:

通过给print加上end="",将print()函数原来默认的输出内容后加上换行,改成了输出内容后加上空字符串,这样就不会换行了。另外,print()中除了可以接收字符串参数外,也可以接收其他任何参数,还可以调用函数,将函数执行结果打印出来。还可以是一个表达式,将表达式的运行结果打印出来。

在上一端代码中,我们在print()语句后,使用 #给代码加入了注释。这是很常用的一种注释方式:单行注释。
如果有多行的注释,可以使用三对双引号或者单引号将其包裹起来:

除了上面两种注释外,还有一种特别的注释,那就是文档注释。文档注释主要是用于自动生成帮助文档,它对于格式和位置有一定要求。
如果你的程序可能会被其他人用到,为了方便他们,避免它们查看你的代码来获得试用方法,应该提供文档注释,并生成文档提供给他们。
文档注释必须是包、类或函数里的第一个语句。这些字符串可以通过对象的doc成员被自动提取,并且可以被pydoc使用。而且文档注释必须使用三对单引号或者双引号来注释,不能使用#

为了更好更清晰地说明函数的作用,函数的文档应该遵循一定的规则:
Args:列出每个参数的名字,并在名字后使用一个冒号和一个空格,分隔对该参数的名称和描述。如果描述太长超过了单行80字符,使用2或者4个空格的悬挂缩进
Returns:该函数的返回值,包括类型和具体返回值的情况。如果没有返回值或者返回None值可以不写
Raises:抛出的异常。不抛出异常不写。

在前面的几个程序中,我们基本能体会到Python程序的一些特点。
首先,Python代码中,不使用{}或者其他明显的标志来限制代码的开始和结束,而是根据代码的缩进来确定代码的关系:连续的同一缩进的代码为同一个代码块,例如函数中的定义。
一条语句的末尾,不需要使用;来结束,而直接使用换行表示语句末尾。
除此外,Python还有一些颇具特色的写法,例如,如果一条语句太长,可以使用”\“将它分割成多行:

虽然Python中可以不使用;作为语句的分割,但如果在一行中有多条语句,那可以使用;将这些语句分隔开:

在上面这些代码中,我们定义了变量a、b、x、y等。可以看出,在Python中,和很多其他编程语言不一样的地方,Python的变量不需要声明为具体的类型,而是直接给它赋值,Python会根据值设置变量的类型。虽然Python的变量不需要先声明类型直接就可以使用,但并不是说Python没有数据类型。Python的常用数据类型包括:
number(数字)
int(整型)
float(浮点型)
complex(复数):复数由实数部分和虚数部分构成,可以用 a + bj,或者 complex(a,b) 表示, 复数的实部 a 和虚部 b 都是浮点型
bool
string(字符串)
list(列表)
tuple(元组)
set(集合)
dict(字典)
这些类型,我们在后续课程将会一一讲到。
在Python中,提供了常用的运算符。我们先来看看它的数学运算符。
/
%:取余
//:整除
**:乘方


可以看到,整数和浮点数的运算,结果都是浮点数。如果想将浮点数转换成整数,可以这样:

或者将整数转换成浮点数:

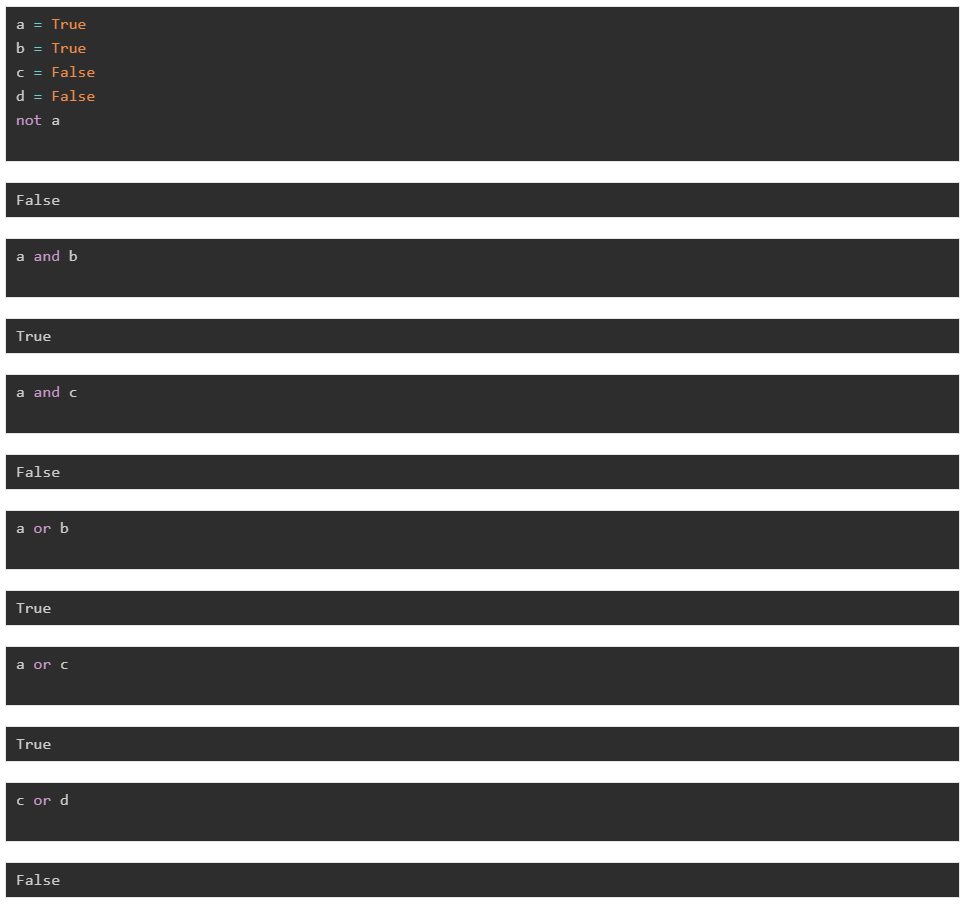
bool 类型只有两个值:True或者False。它的运算操作有 not、and、or

所谓内置函数,就是Python语言本身已经定义好的给我们可以直接使用的函数,例如前面用到的print()、abs()、int()、float()等。这些函数后面我们都会在适当的地方讲到。
前面我们讲了print(),我们来看看输入。
输入使用input(),它接收一个字符串作为显示给用户的提示信息,用户输入后,将会以字符串形式返回给程序。

字符串是最常用的数据类型之一,它用来表示一串不可变的字符。
字符串可以使用双引号或者单引号将字符包含起来
如果字符串中本来就含有单引号或者双引号,可以通过下面的方法来处理:
如果字符串中包含单引号,则使用双引号来包裹这个字符串,反之,如果字符串中包含双引号,则使用单引号来包裹这个字符串,例如:

如果字符串中即有单引号又有双引号,则可以对字符串内的单双引号进行转义,即在字符串内的单双引号前面加上\,例如:

中文的全角单双引号不受影响,即中文单双引号会被当做普通字符。对于内容复杂的字符串,也可以使用""""""或者’’’’’'来包裹字符串,此时无论里面有单引号还是双引号,均会被原封不动地正确处理。
有时候,我们可能需要在字符串中加入一些不确定的内容,例如,根据用户的输入,输出语句问候语:

这种方式可以实现我们的目的,但它在可读性和性能上都不够优化。所以在Python中陆续提供了三种格式化字符串的方式。我们先来看第一种:使用占位符%。如果将上面的代码改成使用%占位符,它可以修改成如下:

这种方式的好处是,%占位符可以自动将非字符串类型的数据转换成字符串,并和字符串其他部分相连接,形成新的字符串。
它的标准格式是:%[(name)][flags][width].[precision]typecode

除了f、s、d外的其他格式字符,请见下面例子:

指定name的方式:

这种格式化数据慢慢被抛弃了,因为它的占位符和值之间必须一一对应,在占位符比较多的时候,比较容易出错。

着这种方式下,使用{}作为占位符,但它的好处在于可以给它指定顺序,例如:

还可以加入变量:

考虑下面这种情况:A喜欢B,可B不喜欢A
如果A、B待定,用前面的格式化方式定义如下:”%s喜欢%s,可%s不喜欢%s” %(“A”,“B”,“B”,“A”)
这种方式的问题在于:
都用%s来指定,看不出A、B的区别
A、B其实各重复了一次,如果重复多次,需要重复写更多次。
如果用format()函数,可以写成:

当然,在format()中也可以使用类似%一样的数据类型等设置:

指定长度和精度:
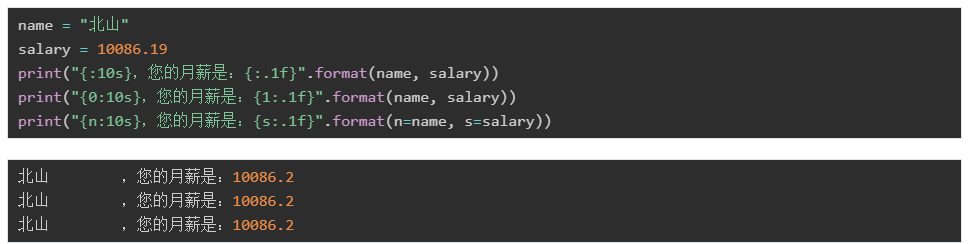
另外,在指定了长度之后,如果对应的值不足,可以指定补足的字符(默认是空格,例如上面北山啦后面的空格),此时必须配合对齐方式来使用:
“<”:左对齐
“^”:居中对齐
“>”:右对齐

format()方法相比较%来说已经有明显的改进,但在某些复杂情况下,还是显得不够灵活。例如:

可以看到,一旦参数比较多,在使用format()的时候,需要做比较多的无用功。其实如果能直接在{}中,和变量直接一一对应,那就方便很多了。可以使用f-string改成

因为f-string的{}中的内容,会在运行时进行运算,因此在{}中也可以直接调用函数、使用表达式,例如:

对于多行文字,为了让代码更美观易读,应该写成如下方式:

当然,在f-string中也可以使用上面的各种限制:

再如:
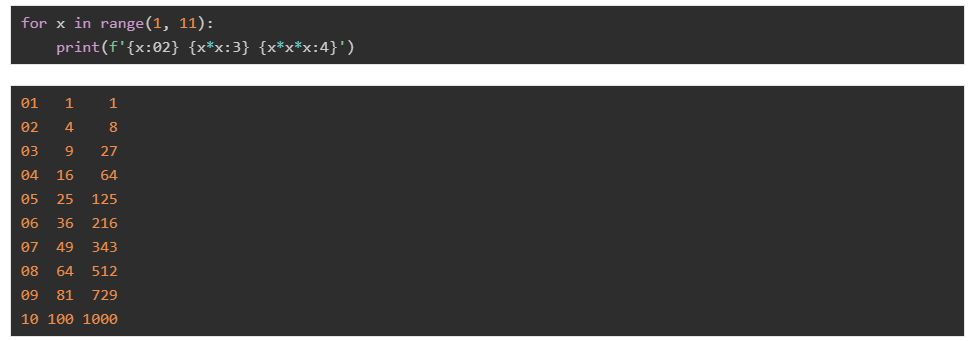
指定对齐方式:

不同进制、不同表示方式的数字:

如果要从字符串中获得其中的一段子字符串,可以通过str[start:end]的方法来获得。其中start为开始索引,end为结束索引,但end对应索引的字符不包含在内。如果只取单个字符,则只需要指定start参数就可以了。

我们经常需要对字符串进行操作,所以Python提供了很多字符串操作的函数供我们使用。
capitalize():字符串首字母大写
title():将字符串中各个单词的首字母大写
lstrip()、rstrip()、strip():分别用于去除字符串左边、右边和左右两边的空格
需要注意的是,上面这些方法,都不会改变原有字符串内容,而是新生成字符串
startswith(prefix, start, end):该字符串是否以某个字符串开始
endswith(suffix, start, end):该字符串是否已某个字符串结尾
find(s, start, end):从字符串中从左到右寻找是否包含字符串s,返回找到的第一个位置。如果没找到,返回-1
rfind(s, start, end):和find()类似,只不过它从右到左寻找
index(s, start, end):和find()类似,但如果没找到将会返回错误
rindex(s, start, end):和index()类似,只不过它从右到左寻找
isalnum():如果字符串中至少有一个字符,且字符串由数字和字母组成,则为true。
isalpha():如果字符串中至少有一个字符,且字符串由字母组成,则为true
isdigit():是否为数字(整数),小数点不算,只支持阿拉伯数字
isnumeric():是否为数字。支持本地语言下的数字,例如中文“一千三百”、“壹万捌仟”等
replace(s1, s2):将字符串中的s1替换成s2

下面我们看一个综合案例。
指定字符串中,将字符串中和第一个字母一样的字母(除第一个字符本身外),都替换成另一个字符“@”,例如:little,替换后成为litt@e,即将little中所有的l(第一个字母是l)都替换成@(除了第一个字母本身),下面是一种实现思路:

使用列表list或者元组tuple,可以存放一系列的数据,例如,将班级所有同学的名字放在一起:
names = [“北山啦”, “李四”, “王五”]
list是一种有序的、可变的数据集合,可变的意思就是可以随时往里添加或者删除元素。
可以通过索引从中取出元素,例如names[1]将取出第二个数据(索引从0开始)。
如果索引超出范围(例如索引大于等于列表个数),将会报错
索引可以是负数,负数表示从后往前计数取数据,最后一个元素的索引此时为-1

列表中的元素,其数据类型不一定要一样。甚至可以使用列表数据作为另一个列表的元素。如:
names = [“北山啦”,“李四”, [“Leonardo”,“Dicaprio”], “王五”],其中,第三个元素(索引为2)为另一个列表
此时,names[2]取出来的值是列表[“Leonardo”,“Dicaprio”],要取Leonardo这个值,则需要在这个列表[“Leonardo”, “Dicaprio”]上使用索引0去获取,因此,可以通过names[2][0]取得

如果要从列表中取出一定范围内的元素,则可以使用list[start:end]的方式来获取,例如:names[1:3]取出从索引1开始到索引3结束(不包含索引3)的2个元素。
start如果省略,表示从0开始
end如果省略,表示到列表最后一个元素结束

如果要创建一系列数字为内容的列表,可以结合list()函数和range()函数来创建,例如,创建包含数字0-99的列表:
print(list(range(100))) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99] range(0, 100)
range()的函数原型:
range(stop) :0开始计数,计数到stop结束,但不包括stop,例如:range(10),生成的数字范围是0-9
range(start, stop[, step]):计数从 start 开始,到stop结束(不包括stop),step是步长,即每次变化的范围,默认为1,即每次加1
start/stop/step均可以为任意整数
“start < stop”,才能生成包含元素的range,如果stop< start,则为空。

append(element):往列表最后附加一个元素
insert(index, element):往列表指定索引位置插入一个元素
可以直接给指定索引元素赋值,用新值替代旧值:names[idx]= value
pop()将最后一个元素从列表中取出来,并从列表中删除该元素
如果要删除列表中的一个索引对应的元素,可以使用del list[idx]的方式
extend(seq):在原来的列表后追加一个系列
remove(obj):从列表中删除第一个匹配obj的元素
clear():清空整个列表
count(obj):计算元素obj在列表中出现次数
sort(key=…, reverse=…):给list排序,可以指定用于排序的key。reverse用于指定是否反序。

[0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 0, -5, -10, -15, -20, -25, -30, -35, -40, -45, -50, -55, -60, -65, -70, -75, -80, -85, -90, -95]
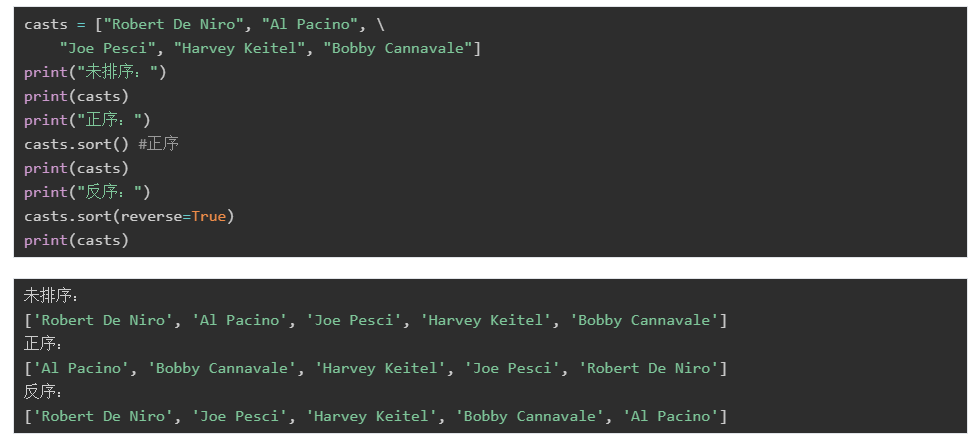
下面我们来看一个更复杂的列表:
the_irishman = [[“Robert”, “De Niro”], [“Al”, “Pacino”],
[“Joe”, “Pesci”], [“Harvey”, “Keitel”], [“Bobby”, “Cannavale”]]
假设我们现在要给它进行排序,那么应该是按照first name还是last name来排序呢?
此时就需要用到sort()函数中的key参数了。通过key可以给它指定一个函数,这个函数来限制应该按照first name还是last name来排序:
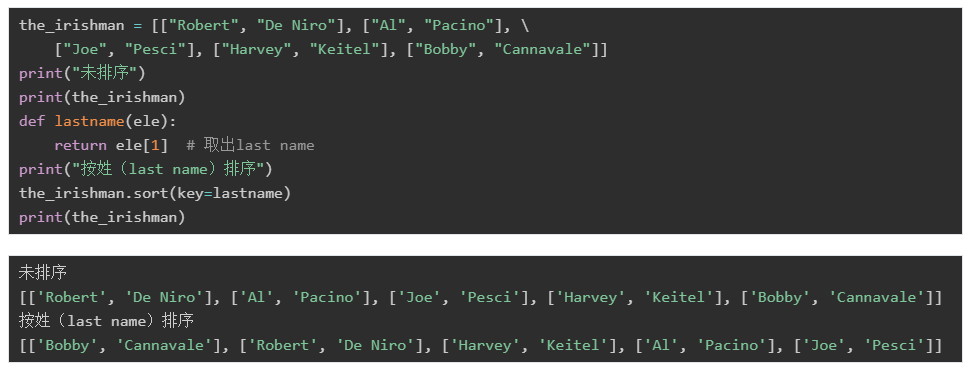
tuple和列表类似,它们的区别在于tuple是不可变的,即如果元组初始化了,则不能改变,tuple没有pop()/insert()这些方法。
需要注意的是,这里的不可变,指的是不能直接将tuple元素改变成另一个元素,但如果tuple的元素是一个可变对象,例如list,那么,list里面的内容是可以改变的,但不能用另一个list去替换tuple中既有的list。

元组还有一个需要特别注意的地方是只有一个元素的元组数据的定义。因为()还是表达式中使用的符号(用来改变操作符顺序),因此如果只有一个元素,定义成 names = (“北山啦”),此时()会被当做表达式符号,这里就会被忽略掉,因此names的值此时为字符串”北山啦”,而不是元组类型。为避免这种情况,可以这样定义单个元素的元组数据:names = (“北山啦”,)

另外还可以使用下面的方法创建元组:

列表和元组均可以乘以一个整数n,表示将原来列表或者元组中的数据复制n份生成新列表或者元组:

列表和列表之间、元组和元组之间,可以使用“+”将两个列表或者元组中的数据合并成新的列表或者元组

注意,tuple和list是不能合并的。
如果想逐个取出列表或者元组中的元素,可以通过for…in…的方式逐个取出元素:

字典(dict)是用于保存键-值(key-value)对的可变容器数据。
字典的每个键值(key-value)对用冒号(:)分割,每个键值对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }
注意,字典中的key必须唯一,即不能有两对key一样的元素。
可以通过d[key]的方式,获得对应key的value。如果不存在对应的key,则会报错。

{'Phoenix': 'Suns', 'Atlanta': 'Hawks', 'Boston': 'Celtics', 'Chicago': 'Bulls', 'Denver': 'Nuggets', 'Detroit': 'Pistons', 'Los Angels': 'Clippers'}
Suns给字典增加数据,可以通过
d[new_key] = new_value
修改某个key对应的值
-d[key] = new_value
删除某个key对应的元素
del d[key],将会删除key对应的键值对,不仅仅是删除值
del d,将会删除整个字典数据

{'Phoenix': 'Suns', 'Atlanta': 'Hawks', 'Boston': 'Celtics', 'Chicago': 'Bulls', 'Denver': 'Nuggets', 'Detroit': 'Pistons', 'Los Angels': 'Lakers', 'Orando': 'Magics'}为了避免key的不唯一,要求key只能使用不变的数据做key,例如:数字、字符串、元组。list因为是可变数据,所以不能当做key。
items():以列表返回可遍历的(键, 值) 元组数组
keys():返回一个包含所有键的可迭代对象,可以使用 list() 来转换为列表
values():返回一个包含所有值的可迭代对象,可以使用 list() 来转换为列表
pop(key[,default]):取出对应key的值,如果不存在,则使用default值
popitem():取出字典中最后一个key-value对
get(key[,default]):取出对应key的值,如果不存在这个key,则使用default值
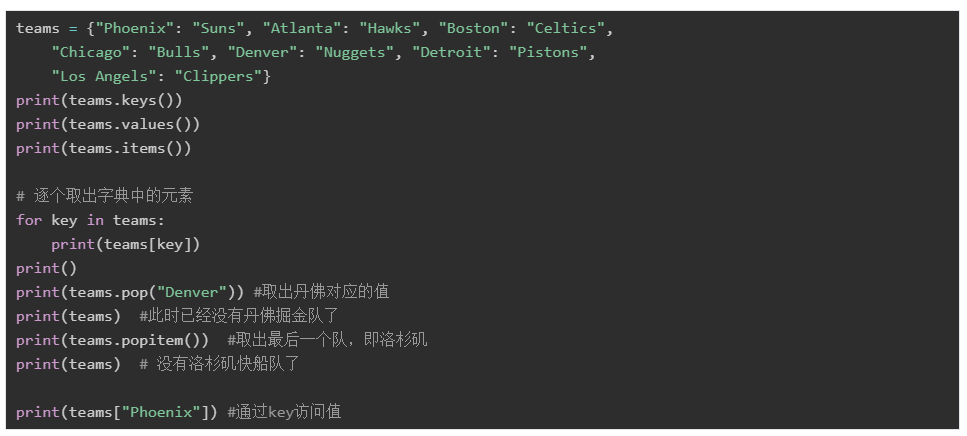
dict_keys(['Phoenix', 'Atlanta', 'Boston', 'Chicago', 'Denver', 'Detroit', 'Los Angels'])
dict_values(['Suns', 'Hawks', 'Celtics', 'Bulls', 'Nuggets', 'Pistons', 'Clippers'])
dict_items([('Phoenix', 'Suns'), ('Atlanta', 'Hawks'), ('Boston', 'Celtics'), ('Chicago', 'Bulls'), ('Denver', 'Nuggets'), ('Detroit', 'Pistons'), ('Los Angels', 'Clippers')])
Suns
Hawks
Celtics
Bulls
Nuggets
Pistons
Clippers
Nuggets
{'Phoenix': 'Suns', 'Atlanta': 'Hawks', 'Boston': 'Celtics', 'Chicago': 'Bulls', 'Detroit': 'Pistons', 'Los Angels': 'Clippers'}
('Los Angels', 'Clippers')
{'Phoenix': 'Suns', 'Atlanta': 'Hawks', 'Boston': 'Celtics', 'Chicago': 'Bulls', 'Detroit': 'Pistons'}
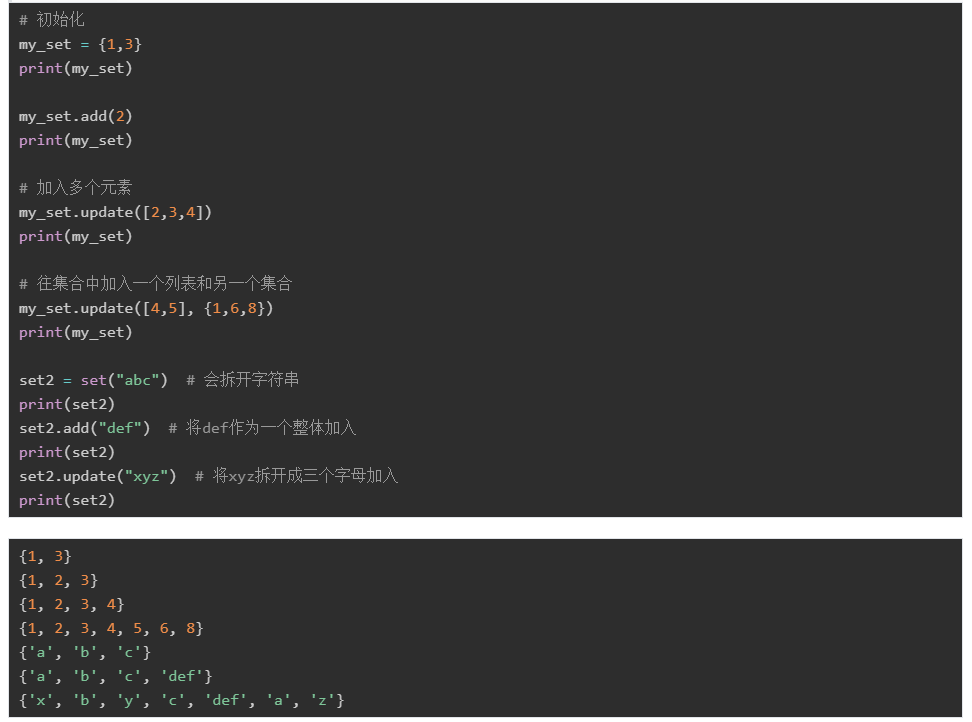
Suns集合(set)是一个无序的不重复元素序列。可以使用set()或者{}来创建一个集合:
如果使用{}创建集合,要注意和字典数据类型的区别——字典数据里是key-value对,而这里是单个的数据
如果创建空集合,不可以使用{},因为系统会首先将其当做字典数据类型来处理。所以空集合请使用set()来创建
如果往集合中放入重复元素,将只会保留一个。
从字符串创建一个集合:

从列表创建一个集合:

从元组创建一个集合:

从字典创建一个集合,此时只会取key作为集合的元素:

- add():往set中增加一个元素,如果该元素已经在set中,则不会成功。参数只能是单个元素,不能使list、tuple或者set
- update(seq):往set中添加多个元素。seq可以是字符串、tuple、list或者另一个set
- 需要注意:add()和update()都是字符串作为参数的时候,两者的区别:add()把字符串当做一个整体加入,而update()会将字符串中的单个字符逐个加入
- discard(item):从集合中删除指定的元素。
- remove(item):从集合中删除指定的元素。如果该元素不存在,会报错。
- pop():从集合中移除一个元素。因为集合是无序的,所以不能确保移除的是哪一个元素
- clear():清空整个集合
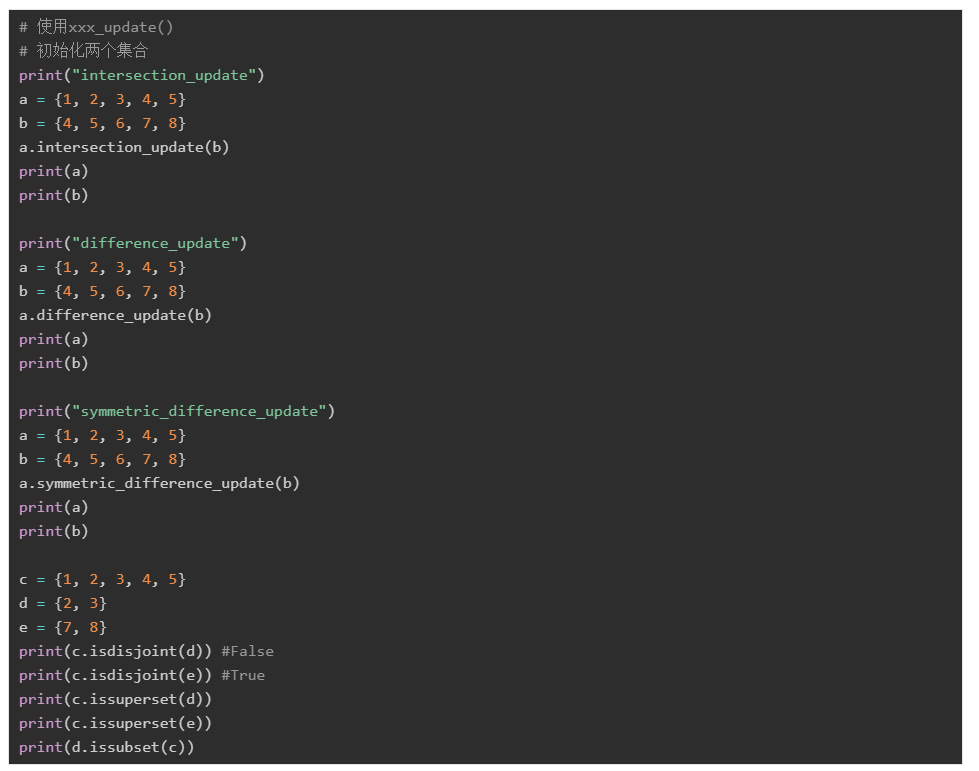
集合之间,可以进行集合操作,主要的集合操作有:
交集(intersection):两个集合操作,生成一个新的集合:只有两个集合中都有的元素,才会被放到新的集合中
可以使用运算符&或者函数intersection()来进行交集操作
并集(Union):两个集合生成一个新的集合,两个集合中的元素都会放到新的集合中
可以使用|操作符或者union()函数进行并集操作
差集(difference):两个集合生成新的集合,在原集合基础上,减去两者都有的元素,生成新的集合。
可以使用-操作符或者difference()函数来进行差集操作
对称差集( symmetric difference):两个集合生成新的集合,新集合中的元素是两个集合的元素减去两者一样的元素。
可以使用^操作符或者symmetric_difference()函数进行对称差集操作

其他操作:
symmetric_difference_update()/ intersection_update()/ difference_update()/update():还是进行前面的对应交、并、差、对称差操作,但将运算的结果,更新到这个集合。
isdisjoint():a.isdisjoint(b),a和b两个集合是否没有交集,没有交集返回True
issubset():a.issubset(b),a是否为b的子集,是返回True
issuperset():a.issuperset(b),a是否为包含b的所有元素,包含返回True

到此,关于“Python基础语法和数据类型总结”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





