这篇文章给大家介绍MySQL中怎么实现排序和分组,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
order by和group by这两个要十分注意,因为一不小心就会产生文件内排序,即file sort,这个性能是十分差的。下面来看具体的案例分析。
首先建表:
create table `tblA`(
`id` int not null primary key auto_increment comment '主键',
`age` int not null comment '年龄',
`birth` timestamp not null comment '生日'
) ;
insert into tblA(age, birth) values(22, now());
insert into tblA(age, birth) values(23, now());
insert into tblA(age, birth) values(24, now());
create index idx_age_birth on tblA(age, birth);
1. order by:
看看下面语句的执行计划:
explain select * from tblA where age > 20 order by age;
explain select * from tblA where age > 20 order by age,birth;
这两个个毫无疑问,可以用到索引。
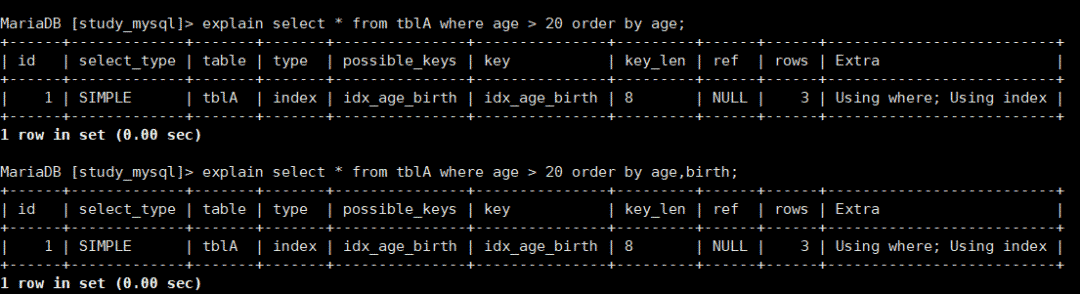
再来看看这个:
explain select * from tblA where age > 20 order by birth;

显然我们可以看到这里产生了filesort,为什么呢?因为age是范围,且order by的直接是二楼,带头大哥没了,所以索引失效了。
那这样呢?
explain select * from tblA where age > 20 order by birth, age;
explain select * from tblA where age > 20 order by age, birth;
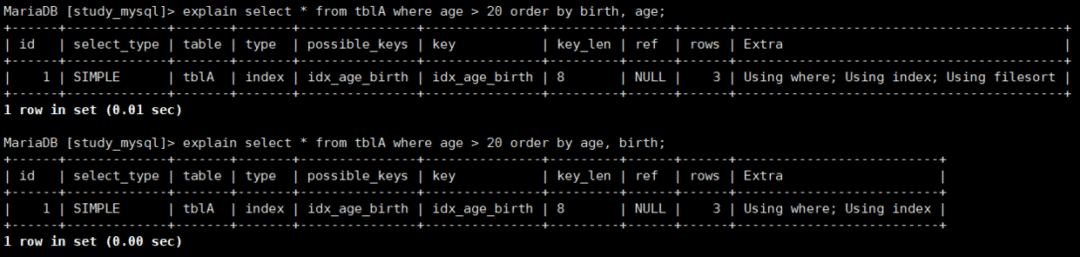
第一个还是不行,因为范围后失效,且order by是从birth二楼开始的。第二个可以用到索引,不会产生filesort,是因为,虽然前面的age是范围,但是order by的又是从age开始,带头大哥在。
上面这些都好理解,看看这个:
explain select * from tblA order by age desc, birth asc;

奇了怪了,带头大哥在,也没有范围,为啥就出现了filesort了呢?
这是因为age是降序,birth又是升序,一升一降,就会导致索引用不上,就会产生filesort了。如果把两个都改成desc或者asc,那就没问题了。
注意:
MySQL的filesort有两种策略,
MySQL4.1之前,叫双路排序。
就是会进行两次磁盘I/O操作。读取行指针和order by的列,
对它们排序,然后扫描排好序的表,再从磁盘中取出数据来。
4.1之后的版本,叫单路排序,只进行一次I/O。
先将数据从磁盘读到内存中,然后在内存中排序。
但是,如果内存,即sort_buffer_size不够大,性能反而不如双路排序。
order by优化小总结:
select *;sort_buffer_size,不管用哪种算法,增大这个都可以提高效率;max_length_for_sort_data,增大这个,会增加用改进算法的概率。2. group by:
group by 其实和order by一样,也是先排序,不过多了一个分组,也遵从最佳左前缀原则。要注意的一点是,where优于having,能用where时就不要用having。
关于MySQL中怎么实现排序和分组就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





