еҰӮдҪ•еҲ©з”Ёзҙўеј•жҸҗй«ҳжҖ§иғҪ
еңЁе…ізі»ж•°жҚ®еә“дёӯпјҢиЎЁдёӯж•°жҚ®жҷ®йҒҚд»Ҙж— еәҸзҡ„зҠ¶жҖҒеӯҳеӮЁеңЁзЈҒзӣҳдёҠпјҢеңЁжІЎжңүзӣёеә”зҙўеј•ж—¶пјҢиӢҘиҰҒеҜ№иЎЁдёӯж•°жҚ®иҝӣиЎҢжҹҘиҜўпјҢе°ұеҸӘиғҪе…ЁиЎЁжЈҖзҙўпјҢе°ҶжүҖжңүи®°еҪ•жҢЁдёӘиҜ»еҸ–пјҢ然еҗҺе’ҢжҹҘиҜўжқЎд»¶иҝӣиЎҢжҜ”иҫғпјҢжҳҫ然пјҢиҝҷз§Қж–№ејҸдјҡеҜјиҮҙеӨ§йҮҸзҡ„зЈҒзӣҳ I/O ж“ҚдҪңе’Ң CPU и®Ўз®—пјҢж¶ҲиҖ—еӨ§йҮҸзҡ„зі»з»ҹж—¶й—ҙпјҢеӣ жӯӨпјҢе»әз«Ӣзҙўеј•е°ұжҲҗдәҶдёҖдёӘеҝ…йЎ»иҖғиҷ‘зҡ„йҖүйЎ№гҖӮ
дҪҝз”Ё CREATE INDEX [зҙўеј•еҗҚ] on иЎЁеҗҚ (еҲ—еҗҚпјҢвҖҰвҖҰ) иҜӯеҸҘеҸҜд»ҘдёәиЎЁдёӯж•°жҚ®е»әз«ӢжңҖеёёз”Ёзҡ„й”®еҖјзҙўеј•пјҢиҖҢй”®еҖјзҙўеј•зҡ„е®һзҺ°еӨ§йғҪйҮҮз”Ё B+ ж ‘ж•°жҚ®з»“жһ„пјҢе®ғжңүд»ҘдёӢдёҖдәӣжҖ§иҙЁпјҡ
1гҖҒ жҳҜдёҖжЈөе№іиЎЎж ‘пјҢеҚід»Һж №иҠӮзӮ№еҲ°еҸ¶еӯҗиҠӮзӮ№зҡ„ж·ұеәҰзӣёе·®дёҚи¶…иҝҮ 1пјӣ
2гҖҒ йқһеҸ¶еӯҗиҠӮзӮ№еҸӘдҝқеӯҳй”®еҖје’ҢжҢҮеҗ‘еӯҗиҠӮзӮ№зҡ„жҢҮй’ҲпјҢдёҚдҝқеӯҳж•°жҚ®пјӣ
3гҖҒ еҸ¶еӯҗиҠӮзӮ№дҝқеӯҳй”®еҖјгҖҒеҜ№еә”и®°еҪ•зҡ„ең°еқҖеҸҠеҸ¶еӯҗиҠӮзӮ№зҡ„й“ҫиЎЁжҢҮй’ҲпјҢй“ҫиЎЁдёӯеҸ¶еӯҗиҠӮзӮ№жҳҜй”®еҖјжңүеәҸзҡ„
дҪҶиҝҷдәӣжҖ§иҙЁе°ұдёҖе®ҡиғҪдҝқиҜҒжҹҘиҜўжҖ§иғҪж»Ўи¶із”ЁжҲ·зҡ„йңҖжұӮеҗ—пјҹдёӢйқўпјҢжҲ‘们д»ҘеҜ№й“¶иЎҢиҙҰжҲ·иҝӣиЎҢж—¶й—ҙж®өжҹҘиҜўдёәдҫӢпјҢжҺўи®Ёзҙўеј•зҡ„жҖ§иғҪй—®йўҳгҖӮ
дёәдәҶж–№дҫҝиҜҙжҳҺй—®йўҳпјҢжҲ‘们еңЁиҝҷйҮҢжҠҠ B+ ж ‘з®ҖеҢ–дёә дёӢеӣҫжүҖзӨәзҡ„B+ ж ‘пјҢд»ҘиҙҰеҸ·е’ҢдәӨжҳ“ж—ҘжңҹдҪңдёәй”®еҖјпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
В
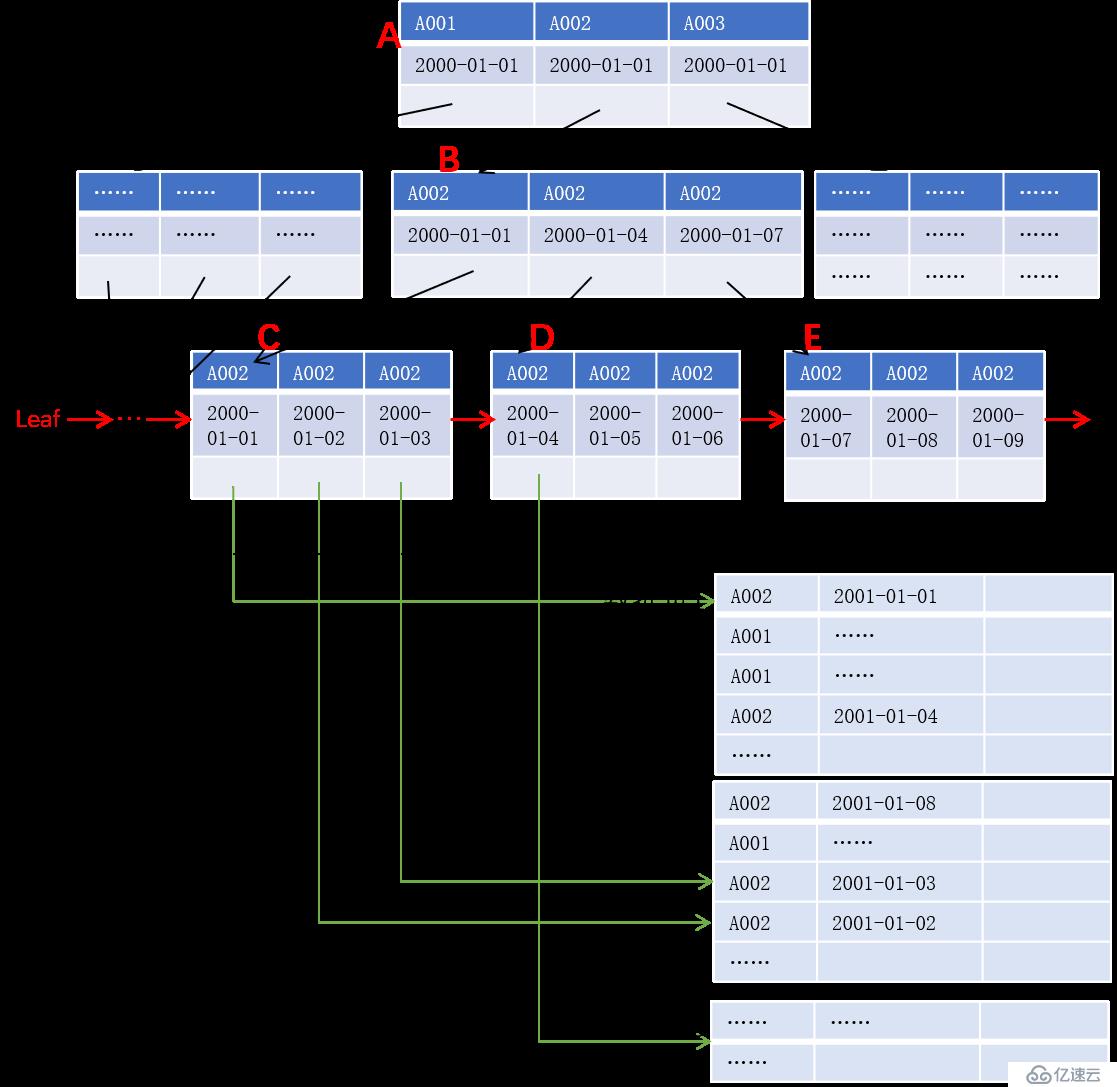
еҰӮжһңжҲ‘们иҰҒжҹҘиҜўиҙҰеҸ· A002 д»Һ 2000-01-01 еҲ° 2000-01-07 зҡ„дәӨжҳ“жөҒж°ҙпјҢж•°жҚ®еә“зі»з»ҹдјҡйҰ–е…ҲиҰҒжҹҘжүҫиҙҰеҸ·дёә A002гҖҒж—ҘжңҹдёҚж—©дәҺ 2000-01-01 зҡ„й”®еҖјжүҖеңЁзҡ„еҸ¶еӯҗиҠӮзӮ№пјҢз»“жһңжҳҜдҫқж¬ЎиҜ»еҸ–зҙўеј•еқ— AгҖҒBгҖҒCпјҢ然еҗҺжүҫеҮәзҙўеј•еқ— C дёӯж»Ўи¶іжқЎд»¶зҡ„й”®еҖјеҜ№еә”зҡ„и®°еҪ•ең°еқҖ并иҜ»еҮәи®°еҪ•иҝ”еӣһпјҢиӢҘзҙўеј•еқ— C дёӯжңҖеҗҺдёҖдёӘж—Ҙжңҹж—©дәҺжҲ–зӯүдәҺ 2001-01-07пјҢеҲҷеҸҜд»Ҙж №жҚ®еҸ¶еӯҗиҠӮзӮ№зҡ„й“ҫиЎЁзӣҙжҺҘиҜ»еҸ–зҙўеј•еҲ— DпјҢд»ҘжӯӨзұ»жҺЁпјҢзӣҙеҲ°жҹҗдёӘзҙўеј•еқ—зҡ„жҹҗдёӘж—ҘжңҹжҜ” 2001-01-07 еӨ§дёәжӯўгҖӮ
и§ӮеҜҹдёҠиҝ°иҝҮзЁӢпјҢжҲ‘们еҸ‘зҺ° 2000-01-01 еҜ№еә”зҡ„и®°еҪ•еңЁж•°жҚ®йЎө 1пјҢ2000-01-02 е’Ң 2000-01-03 еҜ№еә”зҡ„и®°еҪ•еңЁж•°жҚ®йЎө 2пјҢ2000-01-04 еҜ№еә”зҡ„и®°еҪ•еҲҷеңЁж•°жҚ®йЎө 3пјҢ4 жқЎи®°еҪ•йңҖиҰҒиҜ»еҸ– 3 дёӘж•°жҚ®йЎөпјҢжһҒз«Ҝжғ…еҶөдёӢз”ҡиҮід»»ж„ҸдёҖжқЎи®°еҪ•йғҪеңЁдёҚеҗҢзҡ„ж•°жҚ®йЎөпјҢиҖҢжӯӨж—¶еҰӮжһңж•°жҚ®еҢәдёӯи®°еҪ•е·ІжҢүй”®еҖјеәҸеӯҳеӮЁеҲҷеҸҜд»Ҙжҳҫи‘—еҮҸе°‘зЈҒзӣҳ IOгҖӮжӣҙиҝӣдёҖжӯҘпјҢеҰӮжһңи®°еҪ•ж•°жҚ®зӣҙжҺҘдҝқеӯҳеңЁеҸ¶еӯҗиҠӮзӮ№пјҢеҲҷеҸҜд»ҘеҮҸе°‘жҹҘиҜўиҝҮзЁӢдёӯзҙўеј•йЎөдёҺж•°жҚ®йЎөд№Ӣй—ҙзҡ„и·іиҜ»пјҢиҝҷеҜ№дәҺжңәжў°зЎ¬зӣҳзҡ„жҖ§иғҪеҪұе“Қе°Өз”ҡгҖӮ
иҝҷдәӣй—®йўҳеҜ№дәҺйӣҶз®—еҷЁзҡ„з»„иЎЁжқҘиҜҙпјҢеҸҜд»ҘйқһеёёиҪ»жқҫең°еҫ—еҲ°и§ЈеҶігҖӮ
жҲ‘们иҝҳжҳҜд»ҘиӮЎзҘЁдәӨжҳ“ж•°жҚ®дёәдҫӢи®Іи§Јз»„иЎЁзҡ„дҪҝз”ЁгҖӮ
| A |
| 1 | =file("d:/test/stktrade.ctx") |
| 2 | =A1.create@r(#sid,#tdate,open,close,volume) |
| 3 | =connect("mysql") |
| 4 | =A3.cursor("select В * from stktrade order by sid,tdate") |
| 5 | =A2.append(A4) |
| 6 | =A3.close() |
| 7 | =A2.index(idx1;sid,tdate) |
A2: еҲӣе»әж•°жҚ®з»“жһ„дёә (sid,tdate,open,close,volume) зҡ„з»„иЎЁпјҢдё”жҢҮе®ҡ sid е’Ң tdate дёәй”®пјҢ@r жҢҮе®ҡж•°жҚ®жҢүиЎҢеӯҳеӮЁ
A5: е°ҶжҢү sid е’Ң tdate жңүеәҸзҡ„ж•°жҚ®иҝҪеҠ еҲ°з»„иЎЁдёӯ
A6: д»Ҙ sid е’Ң tdate дёәй”®еҖје»әз«Ӣзҙўеј• idx1
| A |
| 1 | =file("d:/test/stktrade.ctx").create() |
| 2 | =A1.icursor(sid=="600036" В && tdate>=date("2018-01-01") && В tdate<=date("2018-01-10"),idx1) |
| 3 | =A2.fetch() |
A1: иҜ»еҸ–з»„иЎЁ
A2: е®ҡд№үж №жҚ®зҙўеј• idx1 жҹҘиҜўж•°жҚ®зҡ„жёёж Ү
A3: еҸ–еҮәжёёж Үдёӯзҡ„ж•°жҚ®
В В еңЁе»әз«Ӣзҙўеј• idx1 ж—¶пјҢд№ҹеҸҜд»Ҙе°ҶжүҖйңҖзҡ„ж•°жҚ®йғҪеӮЁеӯҳеңЁзҙўеј•йҮҢпјҢиӯ¬еҰӮиҰҒе°Ҷ openгҖҒcloseгҖҒvolume иҝҷ 3 еҲ—д№ҹеӮЁеӯҳеңЁзҙўеј• idx1 йҮҢпјҢеҸӘйңҖе°ҶеүҚйқўиЎЁж јйҮҢзҡ„A2.index(idx1;sid,tdate)ж”№дёәA1.index(idx1; sid,tdate; open,close,volume)еҚіеҸҜпјҢиҝҷж ·жҹҘиҜўж—¶е°ұеҸҜд»ҘдёҚиҜ»ж•°жҚ®ж–Ү件гҖҒеҸӘиҜ»еҸ–зҙўеј•ж–Ү件пјҢдҪҝжҹҘиҜўйҖҹеәҰжӣҙеҝ«гҖӮ





