这篇文章主要介绍“怎么使用Kaggle实现对抗验证”,在日常操作中,相信很多人在怎么使用Kaggle实现对抗验证问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么使用Kaggle实现对抗验证”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
首先,导入一些库:

对于本教程,我们将使用Kaggle的IEEE-CIS信用卡欺诈检测数据集。首先,假设您已将训练和测试数据加载到pandas DataFrames中,并将它们分别命名为df_train和df_test。然后,我们将通过替换缺失值进行一些基本的清理。

对于对抗性验证,我们想学习一个模型,该模型可以预测训练数据集中哪些行以及测试集中哪些行。因此,我们创建一个新的目标列,其中测试样本用1标记,训练样本用0标记,如下所示:

这是我们训练模型进行预测的目标。目前,训练数据集和测试数据集是分开的,每个数据集只有一个目标值标签。如果我们在此训练集上训练了一个模型,那么它只会知道一切都为0。我们想改组训练和测试数据集,然后创建新的数据集以拟合和评估对抗性验证模型。我定义了一个用于合并,改组和重新拆分的函数:

新的数据集adversarial_train和adversarial_test包括原始训练集和测试集的混合,而目标则指示原始数据集。注意:我已将TransactionDT添加到特征列表中。
对于建模,我将使用Catboost。我通过将DataFrames放入Catboost Pool对象中来完成数据准备。

这部分很简单:我们只需实例化Catboost分类器并将其拟合到我们的数据中:

让我们继续前进,在保留数据集上绘制ROC曲线:

这是一个完美的模型,这意味着有一种明确的方法可以告诉您任何给定的记录是否在训练或测试集中。这违反了我们的训练和测试集分布相同的假设。
为了了解模型如何做到这一点,让我们看一下最重要的特征:
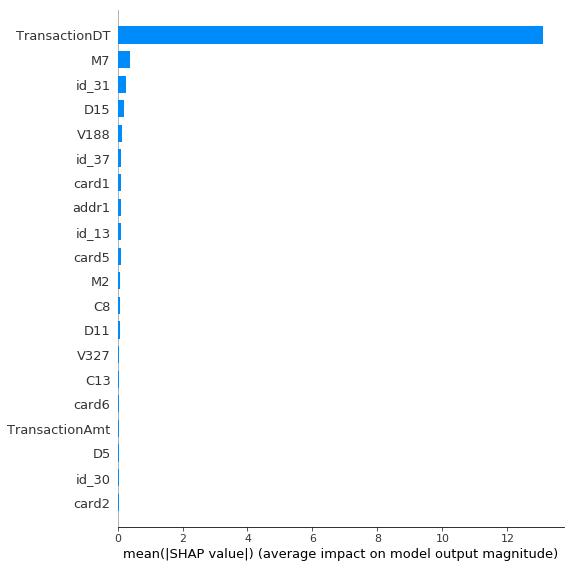
到目前为止,TransactionDT是最重要的特征。鉴于原始的训练和测试数据集来自不同的时期(测试集出现在训练集的未来),这完全合情合理。该模型刚刚了解到,如果TransactionDT大于最后一个训练样本,则它在测试集中。
我之所以包含TransactionDT只是为了说明这一点–通常不建议将原始日期作为模型特征。但是好消息是这项技术以如此戏剧性的方式被发现。这种分析显然可以帮助您识别这种错误。
让我们消除TransactionDT,然后再次运行此分析。

现在,ROC曲线如下所示:
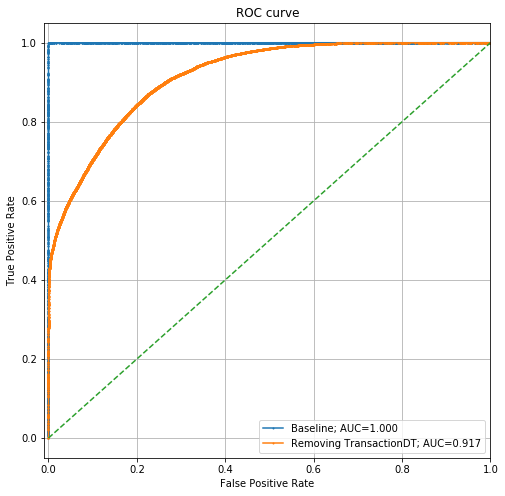
它仍然是一个相当强大的模型,AUC> 0.91,但是比以前弱得多。让我们看一下此模型的特征重要性:
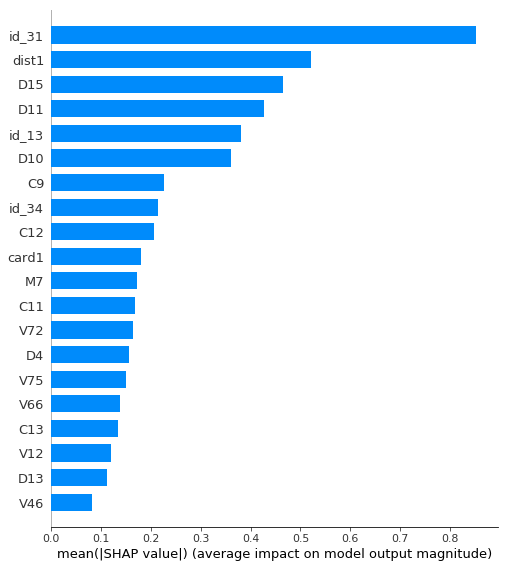
现在,id_31是最重要的功能。让我们看一些值以了解它是什么。

此列包含软件版本号。显然,这在概念上与包含原始日期类似,因为特定软件版本的首次出现将与其发布日期相对应。
让我们通过删除列中所有不是字母的字符来解决此问题:

现在,我们的列的值如下所示:

让我们使用此清除列来训练新的对抗验证模型:
现在,ROC图如下所示:
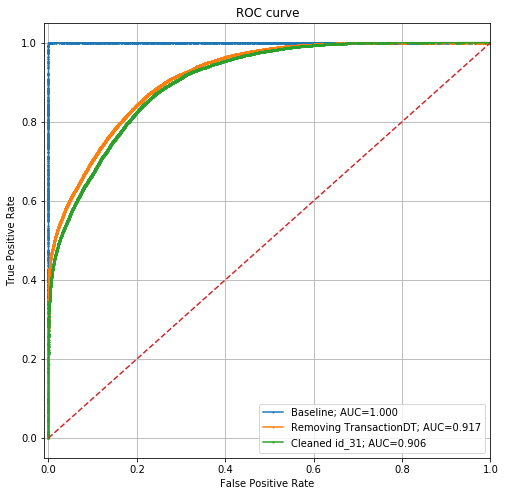
性能已从0.917的AUC下降到0.906。这意味着我们已经很难让模型区分我们的训练数据集和测试数据集,但是它仍然很强大。
到此,关于“怎么使用Kaggle实现对抗验证”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4662955/blog/4695177



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



