如何使用PMML部署机器学习模型,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
预测模型标记语言PMML(Predictive Model Markup Language)是一套与平台和环境无关的模型表示语言,是目前表示机器学习模型的实际标准。从2001年发布的PMML1.1,到2019年最新4.4,PMML标准已经由最初的6个模型扩展到了17个模型,并且提供了挖掘模型(Mining Model)来组合多模型。
作为一个开放的成熟标准,PMML由数据挖掘组织DMG(Data Mining Group)开发和维护,经过十几年的发展,得到了广泛的应用,有超过30家厂商和开源项目(包括SAS,IBM SPSS,KNIME,RapidMiner等主流厂商)在它们的数据挖掘分析产品中支持并应用PMML,这些厂商应用详情见下表:PMML Powered
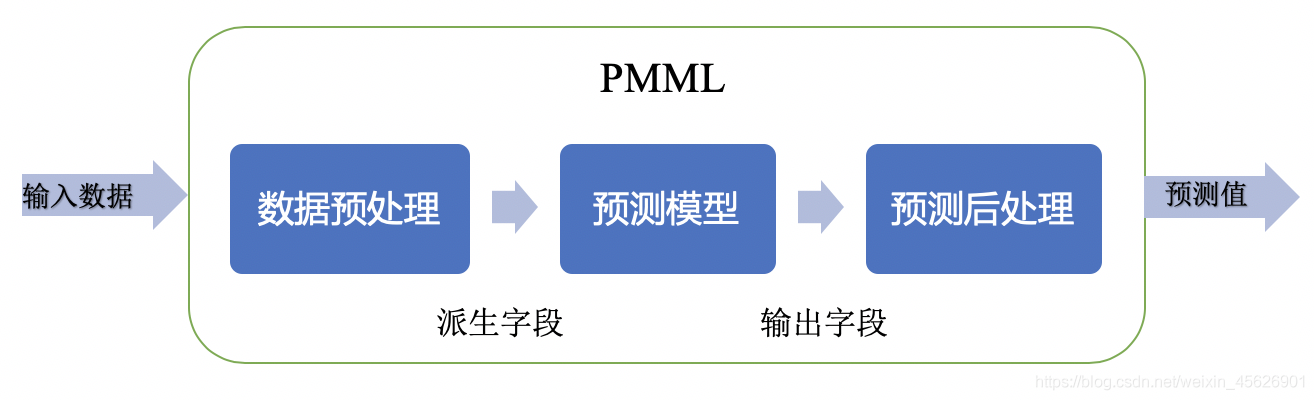
PMML是一套基于XML的标准,通过 XML Schema 定义了使用的元素和属性,主要由以下核心部分组成:
数据字典(Data Dictionary),描述输入数据。
数据转换(Transformation Dictionary和Local Transformations),应用在输入数据字段上生成新的派生字段。
模型定义 (Model),每种模型类型有自己的定义。
输出(Output),指定模型输出结果。
PMML预测过程符合数据挖掘分析流程:
平台无关性。PMML可以让模型部署环境脱离开发环境,实现跨平台部署,是PMML区别于其他模型部署方法最大的优点。比如使用Python建立的模型,导出PMML后可以部署在Java生产环境中。
互操作性。这就是标准协议的最大优势,实现了兼容PMML的预测程序可以读取其他应用导出的标准PMML模型。
广泛支持性。已取得30余家厂商和开源项目的支持,通过已有的多个开源库,很多重量级流行的开源数据挖掘模型都可以转换成PMML。
可读性。PMML模型是一个基于XML的文本文件,使用任意的文本编辑器就可以打开并查看文件内容,比二进制序列化文件更安全可靠。
Python模型:
Nyoka,支持Scikit-Learn,LightGBM,XGBoost,Statsmodels和Keras。https://github.com/nyoka-pmml/nyoka
JPMML系列,比如JPMML-SkLearn、JPMML-XGBoost、JPMML-LightGBM等,提供命令行程序导出模型到PMML。https://github.com/jpmml
R模型:
R pmml包:https://cran.r-project.org/web/packages/pmml/index.html
r2pmml:https://github.com/jpmml/r2pmml
JPMML-R:提供命令行程序导出R模型到PMML,https://github.com/jpmml/jpmml-r
Spark:
Spark mllib,但是只是模型本身,不支持Pipelines,不推荐使用。
JPMML-SparkML,支持Spark ML pipleines。https://github.com/jpmml/jpmml-sparkml
Java:
JPMML-Evaluator,纯Java的PMML预测库,开源协议是AGPL V3。https://github.com/jpmml/jpmml-evaluator
PMML4S,使用Scala开发,同时提供Scala和Java API,接口简单好用,开源协议是常用的宽松协议Apache 2。https://github.com/autodeployai/pmml4s
Python:
PyPMML,PMML的Python预测库,PyPMML是PMML4S包装的Python接口。https://github.com/autodeployai/pypmml
Spark:
JPMML-Evaluator-Spark,https://github.com/jpmml/jpmml-evaluator-spark
PMML4S-Spark,https://github.com/autodeployai/pmml4s-spark
PySpark:
PyPMML-Spark,PySpark中预测PMML模型。https://github.com/autodeployai/pypmml-spark
REST API:
AI-Serving,同时为PMML模型提供REST API和gRPC API,开源协议Apache 2。https://github.com/autodeployai/ai-serving
Openscoring,提供REST API,开源协议AGPL V3。https://github.com/openscoring/openscoring
构建模型,完整Jupyter Notebook,请参考:xgb-iris-pmml.ipynb
使用Iris数据构建一个XGBoost模型,在建模之前对浮点数据进行标准化,利用Scikit-learn中的Pipeline:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import pandas as pd
from xgboost import XGBClassifier
seed = 123456
iris = datasets.load_iris()
target = 'Species'
features = iris.feature_names
iris_df = pd.DataFrame(iris.data, columns=features)
iris_df[target] = iris.target
X, y = iris_df[features], iris_df[target]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=seed)
pipeline = Pipeline([
('scaling', StandardScaler()),
('xgb', XGBClassifier(n_estimators=5, seed=seed))
])
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
y_pred_proba = pipeline.predict_proba(X_test)使用Nyoka,把Pipeline导出PMML:
from nyoka import xgboost_to_pmml
xgboost_to_pmml(pipeline, features, target, "xgb-iris.pmml")使用PyPMML来验证PMML预测值是否和原生Python模型一致:
from pypmml import Model
model = Model.load("xgb-iris.pmml")
model.predict(X_test)读取PMML,进行预测。以下使用PMML4S的Scala接口,您也可以使用它的Java接口,使用非常简单。完整程序,在以下Zeppelin Notebook中:https://github.com/aipredict/ai-deployment/blob/master/deploy-ml-using-pmml/pmml4s-demo.json
因为Github不支持浏览Zeppelin Notebook,可以访问以下地址浏览:https://www.zepl.com/viewer/github/aipredict/ai-deployment/master/deploy-ml-using-pmml/pmml4s-demo.json
import org.pmml4s.model.Model
val model = Model.fromFile("xgb-iris.pmml")
val result = model.predict(Map("sepal length (cm)" -> 5.7, "sepal width (cm)" -> 4.4, "petal length (cm)" -> 1.5, "petal width (cm)" -> 0.4))PMML虽然有很多优点,但也并非毫无缺点,比如:
支持不了所有的数据预处理和后处理操作。虽然PMML已经支持了几乎所有的标准数据处理方式,但是对用户一些自定义操作,还缺乏有效的支持,很难放到PMML中。
模型类型支持有限。特别是缺乏对深度学习模型的支持,PMML下一版5.0会添加对深度模型的支持,目前Nyoka可以支持Keras等深度模型,但生成的是扩展的PMML模型。
PMML是一个松散的规范标准,有的厂商生成的PMML有可能不太符合标准定义的Schema,并且PMML规范允许厂商添加自己的扩展,这些都对使用这些模型造成了一定障碍。
关于如何使用PMML部署机器学习模型问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/aipredict/blog/4672621



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



