如何理解R语言做正态性检验的分析,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
R语言里做做正态性检验通常用到的函数是shaporo.test(),这个是叫Shapiro-Wilk(夏皮罗-威尔克)正态性性检验。
对应的原假设是 样本X来自的总体具有正态性分布
比如代码
> x<-rnorm(100)> shapiro.test(x) Shapiro-Wilk normality testdata: xW = 0.99187, p-value = 0.8117p值大于0.05接受原假设
今天一位同学提出 shaporo.test() 这个函数输出数据的范围是 3~5000,超出5000该如何做呢? 我自己之前还没有注意到过样本量超出5000的情况。
第一个想到的是 在大于5000的样本里再随机选一个小于5000的样本就可以了
示例代码
x<-rnorm(6000)x1<-sample(x,3000,replace = F)shapiro.test(x1)但这种情况好像不太稳定,我试了一下有时候算出来的p值是小于0.05的。那我们就可以多抽几次,看p值小于0.05出现次数的多少
还找到一种方法是 直接可视化数据来观察
可以选密度分布图和qq图
参考链接是 http://www.sthda.com/english/wiki/normality-test-in-r
示例代码
x<-rnorm(6000)library(ggpubr)p1<-ggdensity(x)p2<-ggqqplot(x)library(cowplot)plot_grid(p1,p2,ncol=2)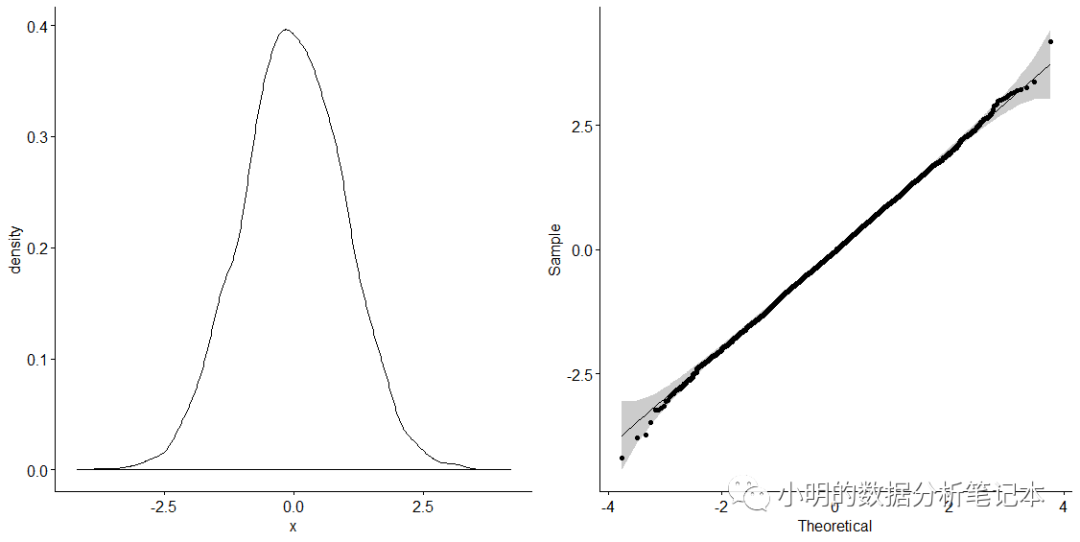
密度分布图是山形,qq图所有的点基本都分布在直线的周围,那就可以判定数据符合正态分布了。
另外还找到一个函数 ad.test()
这个函数对应的R包 nortest
找到这个函数的链接是 https://github.com/jamovi/jmv/issues/160
这个函数对应的是 Anderson-Darling test for normality 这个对应的中文名是啥暂时还不知道。
示例代码
library(nortest)ad.test(rnorm(100, mean = 5, sd = 3)) Anderson-Darling normality testdata: rnorm(100, mean = 5, sd = 3)A = 0.3425, p-value = 0.485这个函数对应的零假设应该也是 样本来自正态总体
比如试一下
ad.test(1:100)Anderson-Darling normality testdata: 1:100A = 1.0837, p-value = 0.007308很明显1:100不符合正态分布
这里得到p值小于0.05,拒绝原假设,最终的结论就是数据总体不符合正态分布。
看完上述内容,你们掌握如何理解R语言做正态性检验的分析的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4579431/blog/4669645



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



