大数据学习路线分享Master的jps,SparkSubmit
类启动后的服务进程,用于提交任务,
哪一段启动提交任务,哪一段启动submit(Driver端)
提交任务流程
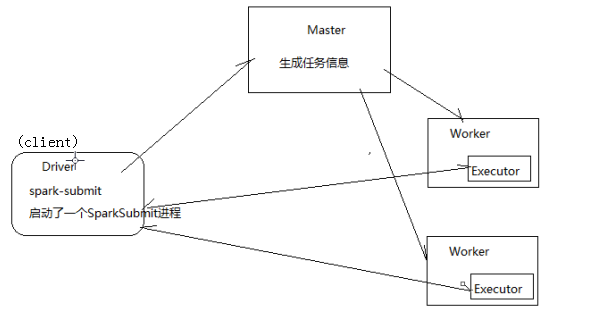
1.Driver端提交任务到Master(启动sparkSubmit进程)
2.Master生成任务信息,放入对列中
3.Master通知Worker启动Executor,(Master过滤出存活的Worker,将任务分配给空闲资源多的worker)
4.worker的Executor向Driver端注册(只有executor真正参与计算) -> worker从Dirver端拿信息
5.Driver端启动Executor将任务划分阶段,分成小的task,再广播给相应的Worker让他去执行
6.worker会将执行完的任务回传给Driver
range 相当于集合子类
scala> 1.to(10) res0: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> 1 to 10 res1: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) |
提交任务到集群的任务类 :
Spark context available as sc
SQL context available as sqlContext
直接调用:

spark WordCount
构建模板代码:
SparkConf:构建配置信息类,该配置优先于集群配置文件
setAppName:指定应用程序名称,如果不指定,会自动生成一个类似于uuid产生的名称
setMaster:指定运行模式:local-用1个线程模拟集群运行,
local[2]: 用2个线程模拟集群运行,loca[*]-当前有多少空闲到的线程就用多少线程来运行该任务
/** * 用spark实现单词计数 */ object SparkWordCount { def main(args: Array[String]): Unit = { /** * 构建模板代码 */ val conf: SparkConf = new SparkConf() .setAppName("SparkWordCount") // .setMaster("local[2]")
// 创建提交任务到集群的入口类(上下文对象) val sc: SparkContext = new SparkContext(conf)
// 获取HDFS的数据 val lines: RDD[String] = sc.textFile(args(0))
// 切分数据,生成一个个单词 val words: RDD[String] = lines.flatMap(_.split(" "))
// 把单词生成一个个元组 val tuples: RDD[(String, Int)] = words.map((_, 1))
// 进行聚合操作 // tuples.reduceByKey((x, y) => x + y) val sumed: RDD[(String, Int)] = tuples.reduceByKey(_+_)
// 以单词出现的次数进行降序排序 val sorted: RDD[(String, Int)] = sumed.sortBy(_._2, false)
// 打印到控制台 // println(sorted.collect.toBuffer) // sorted.foreach(x => println(x)) // sorted.foreach(println)
// 把结果存储到HDFS sorted.saveAsTextFile(args(1))
// 释放资源 sc.stop() } } |
打包后上传Linux
1.首先启动zookeeper,hdfs和Spark集群
启动hdfs
/usr/local/hadoop-2.6.1/sbin/start-dfs.sh
启动spark
/usr/local/spark-1.6.1-bin-hadoop2.6/sbin/start-all.sh
2.使用spark-submit命令提交Spark应用(注意参数的顺序)
/usr/local/spark-1.6.1-bin-hadoop2.6/bin/spark-submit \
--class com.qf.spark.WordCount \
--master spark://node01:7077 \
--executor-memory 2G \
--total-executor-cores 4 \
/root/spark-mvn-1.0-SNAPSHOT.jar \
hdfs://node01:9000/words.txt \
hdfs://node01:9000/out
3.查看程序执行结果
hdfs dfs -cat hdfs://node01:9000/out/part-00000
javaSparkWC
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import scala.Tuple2;
import java.util.Arrays; import java.util.List;
public class JavaSparkWC { public static void main(String[] args) { SparkConf conf = new SparkConf() .setAppName("JavaSparkWC").setMaster("local[1]");
//提交任务入口类 JavaSparkContext jsc = new JavaSparkContext(conf);
//获取数据 JavaRDD<String> lines = jsc.textFile("hdfs://hadoop01:9000/wordcount/input/a.txt"); //切分数据 JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { @Override public Iterable<String> call(String s) throws Exception { List<String> splited = Arrays.asList(s.split(" ")); //生成list return splited; } });
//生成元祖 //一对一组 ,(输入单词,输出单词,输出1) JavaPairRDD<String, Integer> tuples = words.mapToPair(new PairFunction<String, String, Integer>() { @Override public Tuple2<String, Integer> call(String s) throws Exception { return new Tuple2<String, Integer>(s, 1); } });
//聚合 //2个相同key的value,聚合 JavaPairRDD<String, Integer> sumed = tuples.reduceByKey(new Function2<Integer, Integer, Integer>() { @Override public Integer call(Integer v1, Integer v2) throws Exception { return v1 + v2; } });
//此前key为String类型,没有办法排序 //Java api并没有提供sortBy算子,此时需要把两个值位置调换,排序完成后,在换回来 final JavaPairRDD<Integer, String> swaped = sumed.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() { @Override public Tuple2<Integer, String> call(Tuple2<String, Integer> tup) throws Exception { // return new Tuple2<Integer, String>(tup._2, tup._1); return tup.swap(); //swap(),交换方法 } });
//降序排序 JavaPairRDD<Integer, String> sorted = swaped.sortByKey(false); //再次交换 JavaPairRDD<String, Integer> res = sorted.mapToPair( new PairFunction<Tuple2<Integer, String>, String, Integer>() { @Override public Tuple2<String, Integer> call(Tuple2<Integer, String> tup)throws Exception { return tup.swap(); } });
System.out.println(res.collect());
jsc.stop();//释放资源 } } |
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





