这篇文章将为大家详细讲解有关如何进行基于实时ETL的日志存储与分析实践,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
我们正处于大数据、多样化数据(非结构化)的时代,实时的机器数据快速产生,做一家数据公司的核心之一是如何充分利用好大量日志数据。
由此背景,对日志的采集、存储、分析、管理也提出了更高的挑战,其中包括鱼和熊掌的选择问题:
鱼:成本高昂可能导致数据被删除,由此错过了价值发现。在数据量快速增长的同时,客户要保留更长时间的日志,还希望在相应场景下降低存储成本一半或更多。
熊掌:实时数据占机器数据的比例逐步增加,在实时价值越来越受重视的今天,客户希望继续得到交互式、一站式的体验。
鱼和熊掌如何得兼?这里讨论成本与体验的平衡。
SLS是针对机器数据的一站式服务,为用户提供快捷的数据采集、消费、投递以及查询分析等功能,提升运维、运营效率。
我们在服务众多客户的时候,观察到在很多场景下,伴随日志量的不断增长,数据呈现出访问热度的差异。例如:
机器指标不断地追加更新,但在监控指标仪表盘上,新数据的访问频率远超过一天前的数据。
排查异常时,研发人员通过 tail 和 grep 关注 ERROR/WARN 日志的变化,定位问题往往不需要几天前的程序日志。
数据按业务属性有重要程度之分,大量非生产环境日志数据在7天后被访问概率很低,而最近的生产日志需要被灵活访问到。
下面将为大家介绍在 SLS 上兼顾日志数据灵活性、经济性的存储策略与实践。
以 SLB 访问日志处理为例,一个区域下的多个实例数据通常存放在一个全量 Logstore 下(10 秒级延迟)。在该 Logstore 上配置数据加工作业实现数据预处理、按业务标签做数据流转。
错误、高延时的请求,需保证实时查询、快速统计能力,可以规划到一个带 SLS 索引的 Logstore。
其它的所有生产域名请求日志,需要长期存储以备审计、合规,可以转储临时 Logstore(充当桥梁)并投递到更经济的存储。
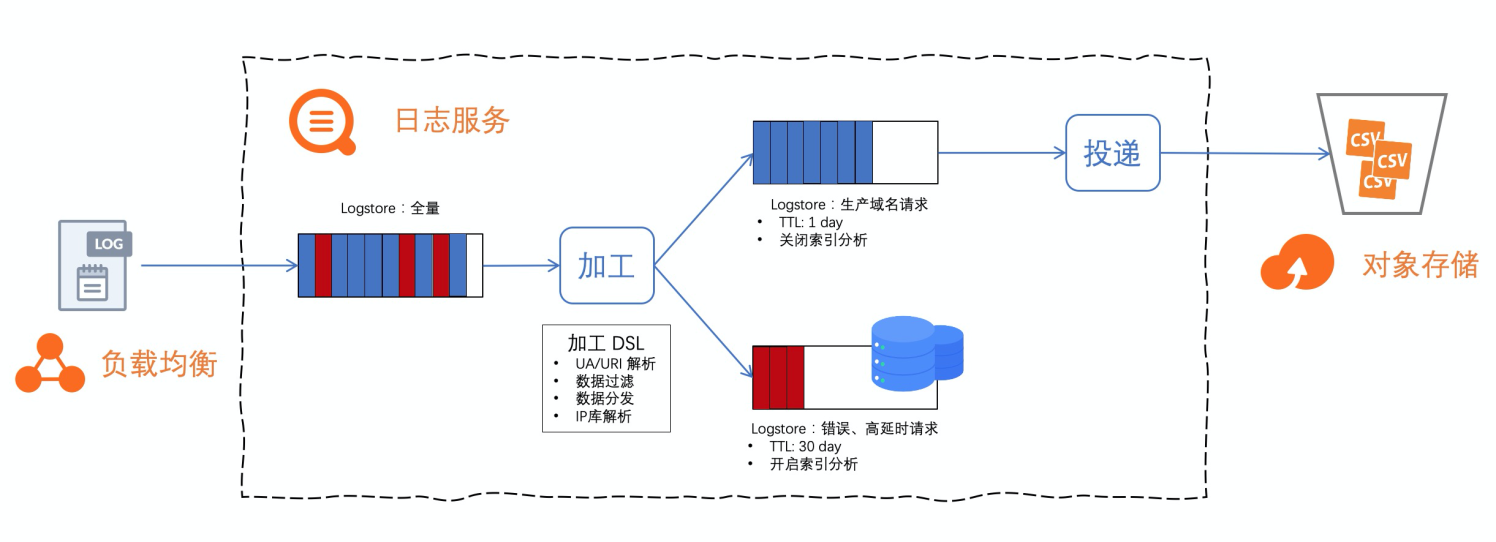
运维数据管道往往比较复杂,SLS 提供的 Serverless 的加工、投递服务,开箱即用。让如上方案实现起来更容易,且具有成本优势。
对于 SLB 七层监听的访问日志,URI 字段包含高价值的业务 key-value 字段,UserAgent 字段可以辅助监控各个端上的服务质量、稳定性。
加工前原日志部分字段:
request_uri: /api/get.convert.v2?fn=callback&url=https%3A%2F%2Fmini.yyrtv.com%2Fr%2F80ba436b763b747d.html%3Ffrom%3D320101%26site%3D1 http_user_agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36
加工 DSL 针对日志规整、抽取场景做处理:
通过 e_kv 抽取 URI 中的业务 key-value 对。
通过 ua_parse_all 对 http_user_agent 字符串做自动抽取。
e_kv('request_uri', prefix = 'uri.')e_set('ua', ua_parse_all(v('http_user_agent')))e_json("ua", depth = 1, fmt = 'root')e_drop_fields('ua', '__tag__:__receive_time__')URI 抽取得到 fn、url 两个业务 key-value 对,使用 e_json 函数对 ua_parse_all 的结果做进一步抽取得到设备、OS、UA 结构化信息。
加工后结果字段如下:
uri.fn: callbackuri.url: https%3A%2F%2Fmini.yyrtv.com%2Fr%2F80ba436b763b747d.html%3Ffrom%3D320101%26site%3D1ua.device: {"family": "Other"}ua.os: {"family": "Windows", "major": "7"}ua.user_agent: {"family": "Chrome", "major": "69", "minor": "0", "patch": "3947"}加工提供算子快速实现多源的数据汇集、同源数据的多目标分发,支持攒批发送(增加吞吐、利于压缩存储)、数据写入异常自动重试。
如下加工 DSL 实现了:
如果 RS 处理延迟有值且大于5.0秒,或者状态码非200,这部分数据写入目标 debug。
符合正则表达式的线上域名产生的访问日志,全部写入到目标 product-host。
e_if(op_or(op_and(op_ne(v('upstream_response_time'), '-'), op_ge(ct_float(v('upstream_response_time')), 5.0)),
op_ne(v('status'), '200')),
e_coutput(name = 'debug'))
e_if(e_search('host ~= ".*-prod\.com"'), e_output(name = 'product-host'))
e_drop()源 Logstore 不开启索引并缩短存储周期到 1 天,将上述两段 DSL 保存到一个加工作业运行,数据实时处理后流向两个下游 Logstore:
debug:存储周期设置为 30 天,开启索引。
product-host:存储周期设置为 1 天,开启 OSS 投递。
计算后端服务器处理延迟超过 60 秒的请求来源 IP 地理分布
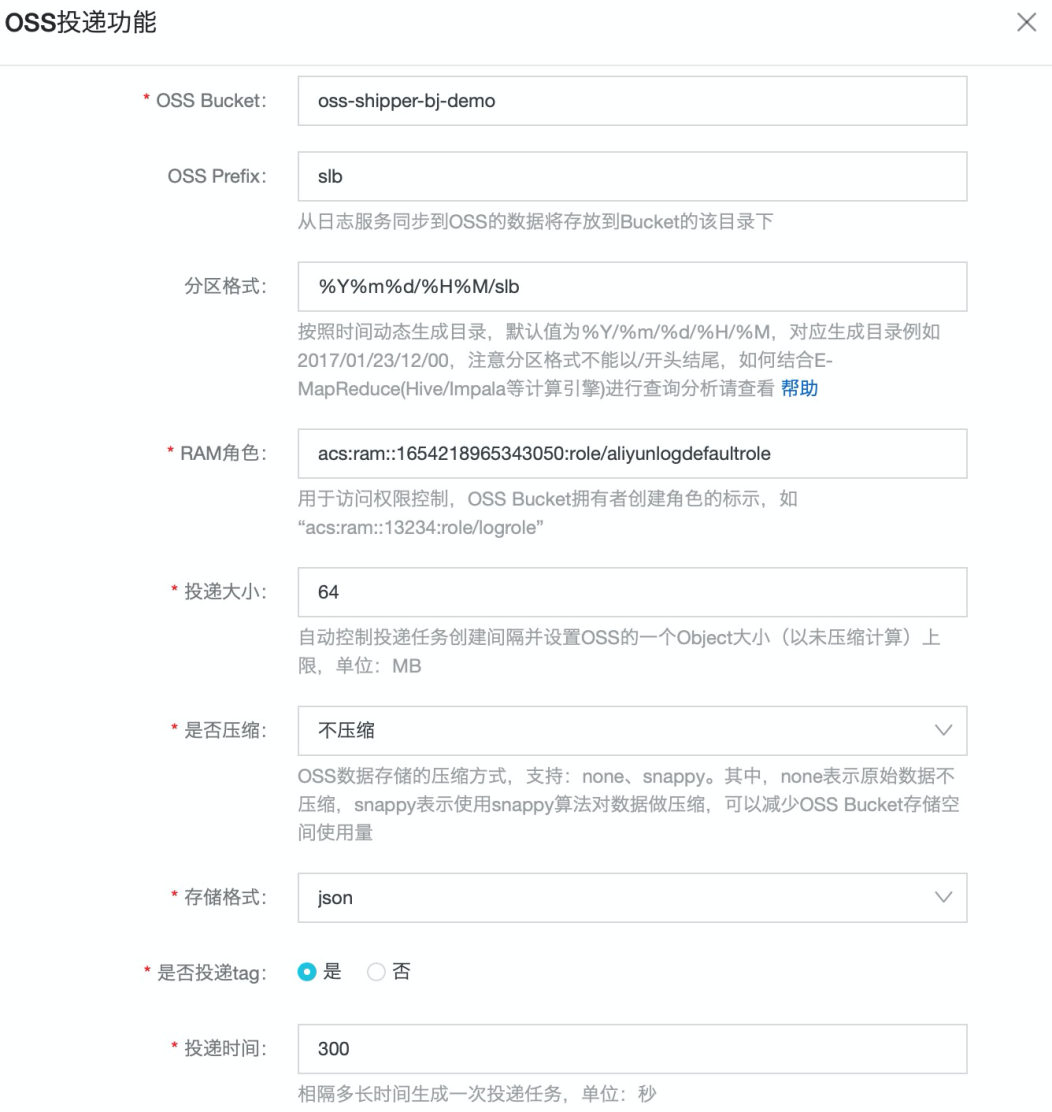
SLS 数据 投递到 OSS 数据湖上,常见有两种场景:
1.极低成本存储
投递时配置开启压缩以降低对象文件大小(日志一般为5~15倍压缩比),数据长期冷存储甚至可以选择归档存储类型或低频访问存储类型 OSS bucket。
2.数据湖存储,兼顾中低频分析
SLS 投递 OSS 提供行存(json/csv)格式、列存(parquet)格式选择,可以根据自定义 key 列表来构建文件。
根据计算引擎(Spark、DLA 等)的特性,选择适当文件格式,可以在计算效率和成本之间取得一个平衡。
例如,使用 OSS select 指定对象文件做简单的数据查询,基于 OSS 的多种存储、计算分离实践都可以通过 Select 做加速。
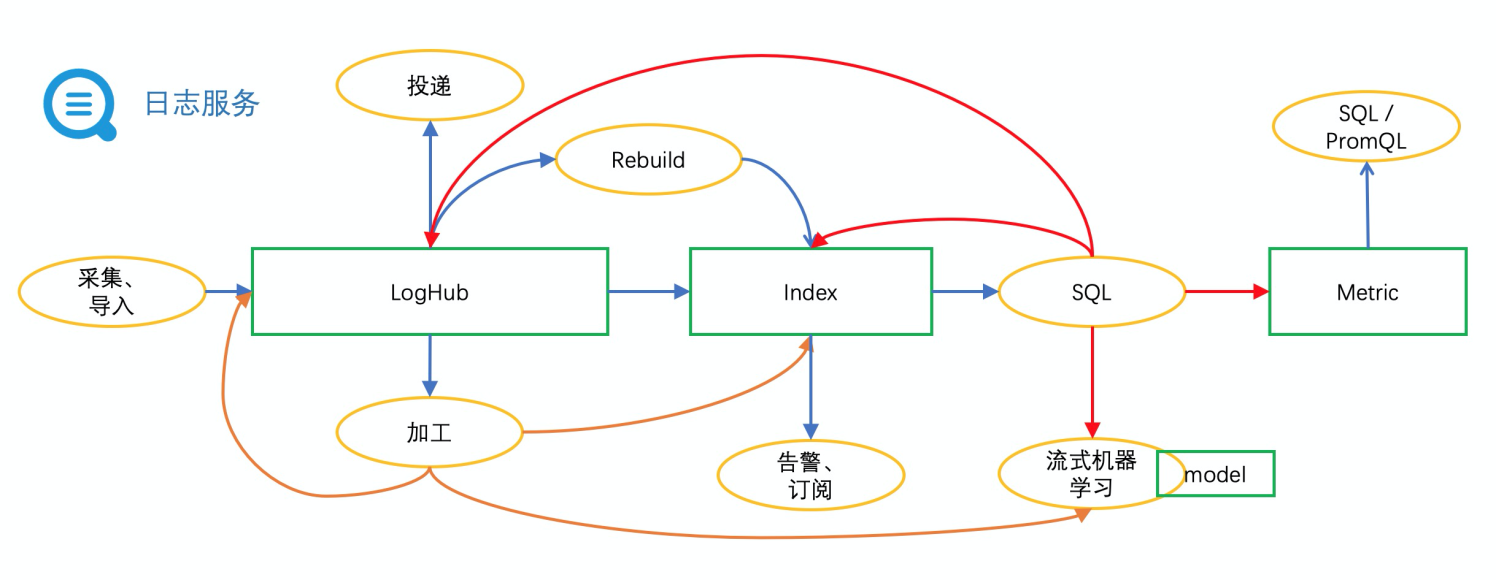
多个存储实体之间,通过连线可以实现数据的流动分层。
在日志数据融合、价值释放、高效利用的道路上,SLS 数据加工、投递持续做好管道服务,满足更多样化的场景需求。
关于如何进行基于实时ETL的日志存储与分析实践就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





