SPL中的集合都是有序的,可以用序号来引用成员,灵活运用序号可以使运算更为简捷高效。
SPL的某些函数中可以使用序号或序号数列作为参数,最简单的应用是直接用序号访问成员,这和一般编程语言中的数组类似。
| A | |
| 1 | [1,3,5,7,9] |
| 2 | =A1(1) |
| 3 | =A1(3) |
| 4 | >A1(2)=4 |
| 5 | >A1(4)=8 |
A2与A3从序列中获取指定位置的成员,位置序号是从1开始的,结果如下:
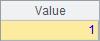
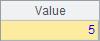
A4与A5修改了序列中的某个成员,用分步执行的方式,可以看到A1中序列的变化如下:

使用A.m(i) 函数可以从后面倒数取或循环取,这个函数为A(i) 提供了有效的补充。
| A | |
| 1 | [1,3,5,7,9] |
| 2 | =A1.m(3) |
| 3 | =A1.m(-2) |
| 4 | =A1.m@r(6) |
| 5 | =A1.m@r(12) |
| 6 | =A1.m(6) |
A2和A3用A.m() 函数从序列中获取指定序号成员的值,其中-2表示倒数第2个成员。A4和A5中的代码添加了@r选项,在获取成员时,如果指定的序号越界则循环取数,如序号12循环A1中的成员2次后,相当于获取第2个成员。A2~A5结果如下:
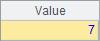
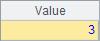
A6中,指定的序号6超过了序列的长度,又没有使用@r选项,会返回空值。

SPL还提供了一组关于位置查找的函数,它们都是以p开头的,如:
| A | |
| 1 | [3,5,1,9,7] |
| 2 | =A1.pos(5) |
| 3 | =A1.pmin() |
| 4 | =A1.pmax() |
| 5 | =A1.pselect(~%5==0) |
A2查找指定成员的位置序号,如果有多个同值成员,只返回第1个序号。A3和A4分别返回最小与最大成员的序号。A5中,找到第1个满足设定条件的成员的序号,这里查找第1个5的倍数成员所在位置。计算后,A2~A5结果如下:
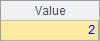
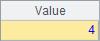
如果无法找到成员,A.pos() 函数将返回null,因此可以用A.pos()函数来判断成员是否属于集合。
| A | |
| 1 | [3,5,1,9,7] |
| 2 | =A1.pos(1)!=null |
| 3 | =A1.pos(2)!=null |
A2与A3计算结果如下:
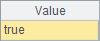
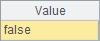
用序号数列作为参数可以访问集合的子集,如:
| A | |
| 1 | [3,5,4,6,1] |
| 2 | =A1([1,3,5]) |
| 3 | =A1([3,5,2]) |
| 4 | =A1([4,1,3,1]) |
| 5 | >A1([1,3,5])=[12,43,28] |
| 6 | >A1([2,4,3])=0 |
A2,A3与A4分别从序列中获取子集,计算后,A2,A3和A4结果如下:


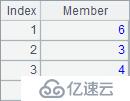
A5与A6修改序列中的成员,使用序数数列作为参数,一次修改多个成员。分步执行时可以看到A1中序列的改变如下:

A.m() 函数也可以使用数列参数获得子集:
| A | |
| 1 | [3,5,4,6,1] |
| 2 | =A1.m([1,-1]) |
| 3 | =A1.m@r([1,6,12]) |
| 4 | =A1.m@0([1,6,3]) |
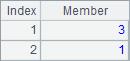
在例子中,参数数列中可以使用负数表示倒数的位置,也可以添加@r选项表示位置越界回转。另外还可以使用@0选项,此时如果参数序列中存在越界的序号,则对应的空值不会出现在结果中。A2,A3和A4结果如下:


如果在位置查找函数中加上@a选项,将找到所有满足条件的成员,并用它们的序号构成数列返回:
| A | |
| 1 | [3,2,1,9,6,9,1,2,8] |
| 2 | =A1.pos@a(2) |
| 3 | =A1.pmin@a() |
| 4 | =A1.pmax@a() |
| 5 | =A1.pselect@a(~%2==0) |
| 6 | =A1.pos@a(8) |
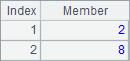
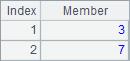
由于添加了@a选项,此时A2会返回序列A1中所有2的位置,A3会返回值最小的所有成员的序号,A4会返回值最大的所有成员的序号,A5会返回所有2的倍数的成员的序号。使用@a选项时,即使只找到一个成员,也将返回序号的序列,而不是序号本身,如A6查找8所在的所有位置。A2~A6计算结果如下:
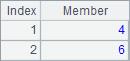

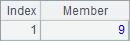
同时返回多个成员的位置需要用A.pos() 函数时,根据需要可能需要添加@i选项,如:
| A | |
| 1 | [3,2,1,9,6,9,1,2,8] |
| 2 | =A1.pos@i([2,9,8]) |
| 3 | =A1.pos@i([3,1,1,1]) |
| 4 | =A1.pos@i([1,2,3]) |
| 5 | =A1.pos([1,2,3]) |
| 6 | =A1.pos([1,1,2,2]) |
| 7 | =A1.pos([1,1,1,2,2,2,3,3]) |
使用A.pos@i() 在查找参数序列中的成员时,会单向顺次进行;而只使用A.pos() 时只会简单判断序列A中是否包含参数序列中的每个成员。A2~A7结果如下:

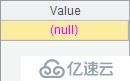


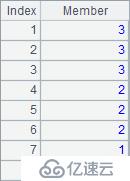
可以看到,A3与A4的结果为空,其中A3计算时找不到序列中的第3个1,A4计算时无法依次找到1,2,3。或者说,A.pos@i() 只会返回递增数列,如果不能找到结果即返回null。
A.pos@i() 在有成员找不到时将返回空,但由于次序和可重复成员的因素,并不能简单地用其判断子集是否被包含,一般要用交运算:
| A | |
| 1 | [3,2,1,9,6,9,1,2,8] |
| 2 | =A1.pos@i([1,9,6])==null |
| 3 | =A1.pos@i([1,2,3])==null |
| 4 | =A1.pos([1,2,3,4])==null |
| 5 | =A1.pos([1,2,3,3])==null |
| 6 | [1,1,2,2] |
| 7 | [1,1,2,2,3,3] |
| 8 | =A6^A1==A6 |
| 9 | =A7^A1==A7 |
A2~A4结果如下:
其中,用A.pos@i(B) 查找判断时,如果结果非空,说明在A中可以依次找到B中的成员,说明A必然包含B。但是如果查找结果是null,只能说明在A中无法依次找到B中的成员,并不能说明A必然不包含B,比如A3中的情况。
用A.pos(B) 查找判断时,如果结果为空,说明B中一定有成员是无法在A中找到的,说明A必然不包含B。但是,如果此时查找的结果不为空,如果B中存在重复的成员,那么是无法保证A包含B的,如A5中的情况。
A8与A9结果如下:
用B^A==B来判断A是否包含B是可行的,根据A8和A9中的结果,可以确定A1包含A6,但A1不包含A7。使用这种方法时需要注意,交运算的操作数不能反过来,否则计算A^B得到的结果中成员的顺序有可能与B不同,就无法正确判断了。
类似符号~,在循环函数的参数中,可以用#表示当前成员的序号。
| A | |
| 1 | [5,4,3,2,1] |
| 2 | =A1.(#) |
| 3 | =A1.(#+~) |
| 4 | =A1.select(#%3==2) |
| 5 | =A1.group(int((#-1)/2)) |
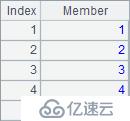
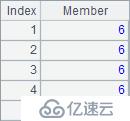
A2获得序号构成的数列,A3获得每个位置成员与序号相加的结果序列。A4用A.select()函数在A1的序列中选出每3个中的第2个成员,即第2,5,8,…位置的成员,并构成序列。A5中将A1每2个成员分为一组。A2~A5结果如下:


在循环函数中,SPL还提供用[ ]符号以相对方式访问成员:
| A | |
| 1 | [1,2,3,4,5] |
| 2 | =A1.(~[0]) |
| 3 | =A1.(~[1]) |
| 4 | =A1.((~-~[-1])/~[-1]) |
| 5 | =demo.query("select * from STOCKRECORDS where STOCKID=000062").sort(DATE) |
| 6 | =A5.((CLOSING-CLOSING[-1])/CLOSING[-1]) |
| 7 | 0 |
| 8 | =A5.max(if(CLOSING>CLOSING[-1],A7=A7+1,A7=0)) |
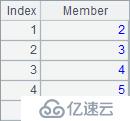
A2就是从序列中取出每个成员本身,A3在每个位置取出后面的1个成员,A4计算出序列中每个成员与前一个成员相比较的增长率。A2,A3和A4计算结果如下:

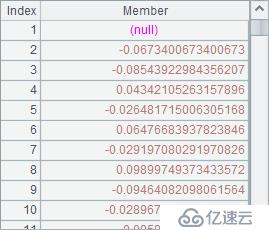
A5查询出指定编号的股票信息。A6计算出每日股价的涨幅,A8进一步计算出这支股票的最大连涨天数。A6和A8的结果如下:

还可以用~[a,b]在循环运算中访问子集:
| A | |
| 1 | [1,2,3,4,5] |
| 2 | =A1.(~[-1,1]) |
| 3 | =A1.(~[-1,1].avg()) |
| 4 | =A1.(~[1-#,0].sum()) |
| 5 | =A1.(~[,0].sum()) |
| 6 | =A1.(~[0,].sum()) |
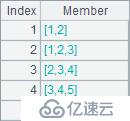
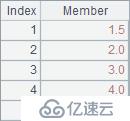
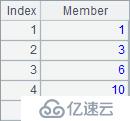
A2在每个位置列出了序列中前后3个位置的成员。A3计算每个位置的移动平均值。A4和A5同样都是累计求和。A6计算反向的累计求和,即剩余成员的总和。A2~A6结果如下:

我们知道,循环函数中的符号#用以表示当前成员的序号,事实上它就是个数,和其它数一样可以参加运算,特别是可以用作序号访问其它序列的成员。利用这个特点,我们可以在计算中对位访问其它序列:
| A | |
| 1 | [1,2,3,4,5] |
| 2 | =A1.(A1(#)) |
| 3 | =A1.(A1.m(#-1)) |
| 4 | [5,4,3,2,1] |
| 5 | =A1.(~+A4(#)) |
| 6 | =A1++A4 |
| 7 | =10.(if(#%2==1,A1((#-1)/2+1),A4(#/2))) |
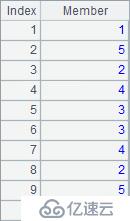
在循环计算中,表达式中的#可以用来表示当前的序号。计算后,A2,A3,A5,A6和A7结果分别如下:

使用多个等长的序列时,利用对位访问可以实现出类似记录字段的效果:
| A | |
| 1 | [Bray,Jacob,Michael,John] |
| 2 | [65,87,98,72] |
| 3 | [76,82,78,88] |
| 4 | =A1.ranks@z(A2(#)+A3(#)) |
| 5 | =A1.new(~:name,A4(#):rank) |
A4计算总分的排名,计算总分时按照位置取得成绩。A5生成姓名与排名的序表,同样根据位置将两个序列中的数据关联起来。A4和A5结果如下:

利用对位访问之前需要确保各序列已经按同一次序排好,但实际应用时序列未必总是这样,这时使用对齐函数A.align() 即可令序列按某个基准序列重新排序:
| A | B | |
| 1 | =demo.query("select * from EMPLOYEE") | /员工表 |
| 2 | =demo.query("select * from ATTENDANCE").align(A1:EID,EMPLOYEEID) | /考勤表按员工编号对齐 |
| 3 | =demo.query("select * from PERFORMANCE").align(A1: EID, EMPLOYEEID) | /绩效表按员工编号对齐 |
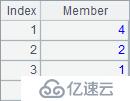
| 4 | =A1.new(NAME,SALARY*(1+A2(#).ABSENCE+A3(#).EVALUATION):salaryPaid) | /新建序表计算工资,A1,A2,A3同序 |
| 5 | =demo.query("select * from GYMSCORE where EVENT='Vault'") | /跳马分数 |
| 6 | =demo.query("select * from GYMSCORE where EVENT='Floor'").align(A5:NAME,NAME) | /自由体操分数,按运动员对齐 |
| 7 | =A5.(round(SCORE*0.6+A6(#).SCORE *0.4,3)) | /计算加权分 |
| 8 | =A7.ranks@z() | /计算加权分名次 |
| 9 | =A5.new(NAME,A7(#):score,A8(#):rank) | /新建序表计算运动员,加权分和排名 |
A2和A3的序表均已按A1中的员工编号对齐,A4计算出员工的工资序表如下:
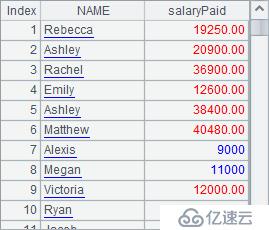
A6将数据按照A5序表中运动员的名字对齐,A7据此计算出加权成绩。A8再计算出加权分的排名后,最终A9整理出结果序表如下:
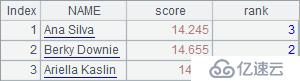
事实上,使用@a选项的对齐函数也会返回一个与基准序列对齐的序列,只是其每个成员都是集合,同样可以应用对位访问。
| A | B | |
| 1 | =demo.query("select * from EMPLOYEE") | /员工表 |
| 2 | [California,Texas,Pennsylvania] | |
| 3 | =A1.align@a(A2,STATE) | /按照A2中的州对齐分组 |
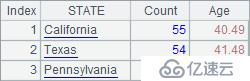
| 4 | =A3.new(A2(#):STATE,~.count():Count,round(~.avg(age(BIRTHDAY)),2):Age) | /用#根据A3中的序号查找A2中的字段值 |
计算后,A4结果如下:
无选项A.align() 函数将对应基准序列的每个成员,在源序列中取出第1个成员再构成集合返回,而不是返回集合的集合,当事先明确知道每个分组子集只有1个成员时,使用A.align()函数即相当于完成了一次按基准序列排序的运算。
类似地,枚举分组也可以对位访问,只是A.enum() 中@1选项是无效的,只能处理分组式问题:
| A | |
| 1 | =demo.query("select * from EMPLOYEE") |
| 2 | [AgeGroup1,AgeGroup2,AgeGroup3] |
| 3 | [?<=35,?>35 && ?<=40,?>40] |
| 4 | =A1.enum(A3,age(BIRTHDAY)) |
| 5 | =A4.new(A2(#):AgeInterval,~.count():Count) |
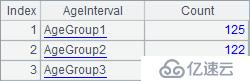
A5计算出3个年龄组中员工总数如下:
数列是一种特殊的集合,它本身是个集合,可以应用各种集合运算,同时,它又可以作为序号用于访问其它序列的子集,灵活运用数列是建立序号思维的重要环节,如:
| A | |
| 1 | =to(10) |
| 2 | =to(3,8) |
| 3 | =A1.step(3,2) |
| 4 | =20.step(4,2,3) |
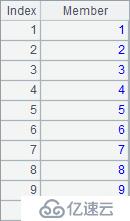
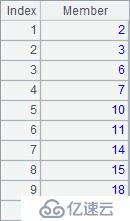
to() 函数可以得到由连续的整数构成的序列,而step() 函数则可以设定数列成员的间隔等参数,A1~A4结果依次如下:


使用子序列在原序列中的位置数列可以用来处理子集,如:
| A | B | |
| 1 | =to(100) | /1到100组成的序列 |
| 2 | =A1(100.step(14,7))=0 | /从14起,7的倍数赋值为0 |
| 3 | =A1.run(if(~>1,A1(100.step(~,~+~))=0,0)) | |
| 4 | =A1.select(~>1) | /生成素数表:将位置为合数的均赋值为0,只留下素数 |
| 5 | =100.(rand()) | /产生100个随机数 |
| 6 | =A5(to(50)) | |
| 7 | =A5(to(51,100)) | |
| 8 | >A5(100.step(2,1))=A6 | |
| 9 | >A5(100.step(2,2))=A7 | /对A5进行洗牌,即将前50个与后50个成员交替排列 |
在上面的例子中,可以用数列来为原序列赋值,也可以获取子序列等。
如果对序列排序,那会丧失成员的原有次序信息,但有时这个信息还要用,比如我们想知道年龄最大的三名员工在全公司的入职次序,某支股票股价最高的三个交易日的涨幅,…。
为此,SPL提供了A.psort() 函数,用以返回排序后成员在排序前的序号。
| A | |
| 1 | [c,b,a,d] |
| 2 | =A1.psort() |
| 3 | =A1(A2) |
| 4 | =A1.sort() |
| 5 | =A3==A4 |
A2~A5结果如下:

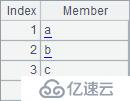
通俗地说,在A.psort() 返回的数列中,第1个数是本次排序应当排在第1位的成员在原序列的序号,第2个数是应当排在第2位的成员在原序列的序号,…。
用序号数列产生的序列,也可以用A.inv() 函数获得序号数列的逆数列,来进行回复操作,如:
| A | |
| 1 | [c,b,d,a] |
| 2 | =A1.sort() |
| 3 | =A1.psort().inv() |
| 4 | =A2(A3) |
| 5 | =A4==A1 |
A2~A5的计算结果如下:
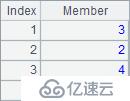

有了A.psort()和A.inv() 两个函数,就可以很方便地解决需要保持原序号的问题:
| A | B | |
| 1 | =demo.query("select * from EMPLOYEE ").sort(HIREDATE) | |
| 2 | =A1.psort(BIRTHDAY:-1) | /返回A1按生日排序的序号数列 |
| 3 | =A2(to(3)) | /最小的3名员工在A1中的序号数列 |
| 4 | =demo.query("select * from STOCKRECORDS where STOCKID=000062").sort(DATE) | |
| 5 | =A4.psort(CLOSING:-1) | /A4按收盘价降序排序后的序号数列 |
| 6 | =A5(to(3)) | /收盘价最高的三天记录在A4中的序号 |
| 7 | =A6.(A4(~).CLOSING/A4.m@0(~-1).CLOSING-1) | /这三天的涨幅,计算涨幅要用A4中顺序 |
| 8 | =A6.(A4.calc(~,(CLOSING-CLOSING[-1])/CLOSING[-1])) | /可以用calc函数简写A7中的表达式 |
在查找数据时,使用二分法能够极大地提高效率,但这种方法要求原序列对于查找的关键字有序,若原序列无序则需要先排序。如果是查找成员本身,先排序没有问题,但要查找成员的序号时,排序则会破坏这个信息,这时又需要使用A.psort() 函数,如:
| A | B | |
| 1 | =demo.query("select * from EMPLOYEE ").sort(HIREDATE) | |
| 2 | =A1.psort(NAME) | /A1按姓名排序后的序号数列 |
| 3 | =A1(A2) | /按姓名排序后的排列 |
| 4 | =A3.pselect@b(NAME:"David") | /用二分法查找David在A3中的序号 |
| 5 | =A2(A4) | /David在A1中的序号 |
这里用A.psort() 相当于为序列建立了一个二分法查找索引,一个序列可以同时按不同关键字建立多个查找索引。
对齐分组函数也可以返回序号构成的数列而不直接返回对齐后的序列,如:
| A | B | |
| 1 | =demo.query("select * from SALES").sort(AMOUNT:-1) | /订单按金额降序排序 |
| 2 | [QUICK,ERNSH,HANAR,SAVEA] | |
| 3 | =A1.align@1p(A2,CLIENT) | /按A2中的客户序列对位分组,返回序号 |
| 4 | =A3.new(A2(#):NAME,A1(~).AMOUNT: Amount,~:Rank) | /用A3中的序号在A1中查找订单金额和总额排名 |
计算出了所需记录的序号,就可以用定位计算A.calc() 来计算所需结果。使用定位计算可以避免不必要的计算,从而提高计算效率。
| A | |
| 1 | =file("VoteRecord") |
| 2 | =A1.import@b() |
| 3 | [Califonia,Ohio,Illinois] |
| 4 | =A2.pselect@a(A3.pos(State)>0) |
| 5 | =A2.calc(A4,Votes[-1]-Votes+1) |
A2,A4和A5中的计算结果如下:


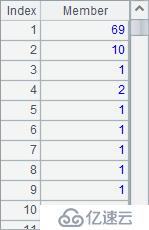
在这个例子中,二进制文件VoteRecord中存储了某次投票的结果,并已经按票数降序排序。A4计算出指定州的员工编号序列。A5根据编号序列,计算出这些员工还需获得多少票,排名就可以上升。如目前排在第3位的Ryan Williams,需要再获得69票,排名就可前进1位。在计算中需要跨行处理,这种计算不能仅根据选出员工的数据完成,还需要原表中的相关数据。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





