这篇文章主要为大家展示了“MergeTree中clickhouse稀疏索引怎么用”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“MergeTree中clickhouse稀疏索引怎么用”这篇文章吧。
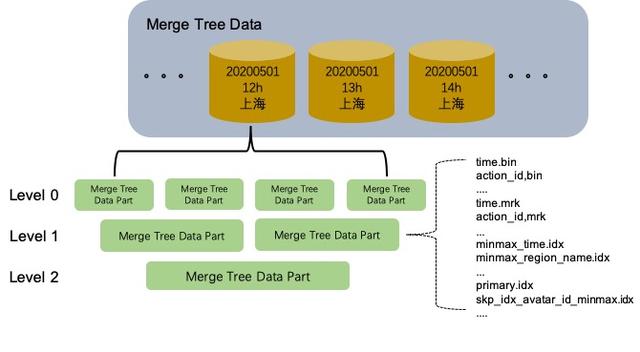
MergeTree表的存储结构中,每个数据分区相互独立,逻辑上没有关联。单个数据分区内部存在着多个MergeTree Data Part。这些Data Part一旦生成就是Immutable的状态,Data Part的生成和销毁主要与写入和异步Merge有关。MergeTree表的写入链路是一个极端的batch load过程,Data Part不支持单条的append insert。每次batch insert都会生成一个新的MergeTree Data Part。如果用户单次insert一条记录,那就会为那一条记录生成一个独立的Data Part,这必然是无法接受的。一般我们使用MergeTree表引擎的时候,需要在客户端做聚合进行batch写入。
part:一次写入生成的一个数据块。
primary.idx文件:存储了稀疏索引,一个part对应一个稀疏索引。
| mark number | value |
|---|---|
| 0 | a |
| 1 | a |
| 2 | b |
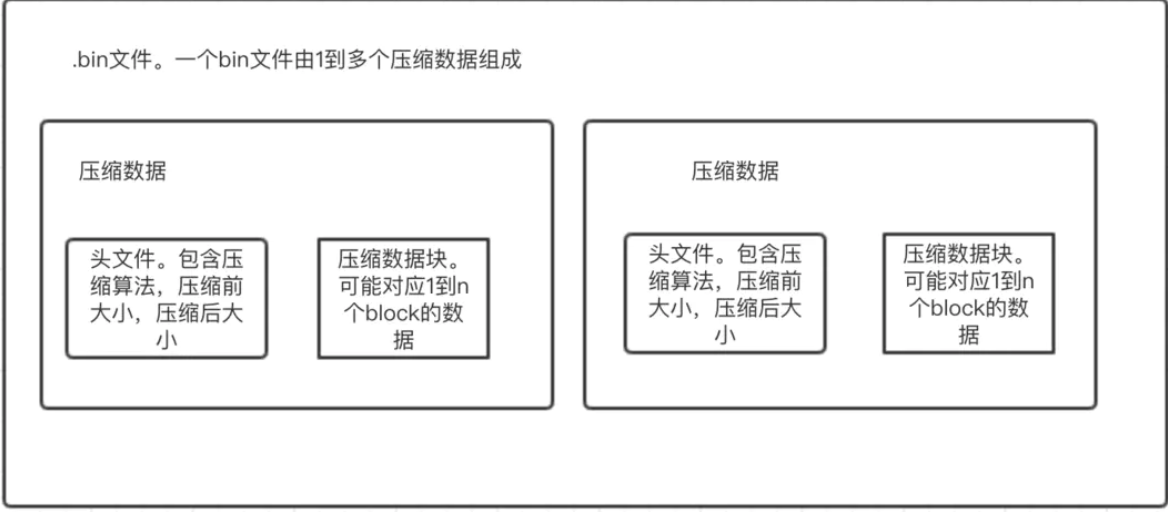
bin文件:真正存储数据的文件,由1到多个压缩数据组成。压缩数据是最小存储单位,由『头文件』和『压缩数据块』组成。头文件由压缩算法、压缩前的字节大小、压缩后的字节大小三部分组成;压缩数据块严格限定在压缩前64K~1M byte大小。(这个大小是ClickHouse认为的压缩与解压性能消耗最小的大小)。即,一个压缩数据块由N个block组成,一个bin文件又由N个压缩数据块组成。
mrk文件:存储了block在bin文件中哪个压缩数据以及这个压缩数据的数据块中的起始偏移量。
| 索引中的mark index | 压缩数据index | 在压缩数据块中起始的字节数(偏移量) |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 12001 |
| 2 | 1 | 0 |
action_id.bin、avatar_id.bin等都是单个列按块压缩后的列存文件
数据以压缩数据为单位,存储在bin文件中。
压缩数据对应的压缩数据块,严格限定按照64K~1M byte的大小来进行存储。
(1)如果一个block对应的大小小于64K,则需要找下一个block来拼凑,直到拼凑出来的大小大于等于64K。
(2)如果一个block的大小在64K到1M的范围内,则直接生成1个压缩数据块。
(3)如果一个block的大小大于了1M,则切割生成多个压缩数据块。
一个part下不同的列分别存储,不同的列存储的行数是一样的。
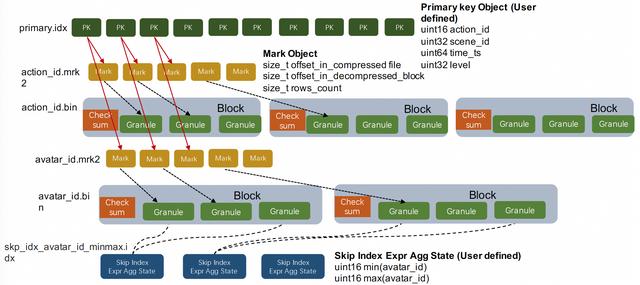
Mark标识文件:action_id.mrk2、avatar_id.mrk2等都是列存文件中的Mark标记,Mark标记和MergeTree列存中的两个重要概念相关:Granule和Block。
Granule是数据按行划分时用到的逻辑概念。关于多少行是一个Granule这个问题,在老版本中这是用参数index_granularity设定的一个常量,也就是每隔确定行就是一个Granule。在当前版本中有另一个参数index_granularity_bytes会影响Granule的行数,它的意义是让每个Granule中所有列的sum size尽量不要超过设定值。老版本中的定长Granule设定主要的问题是MergeTree中的数据是按Granule粒度进行索引的,这种粗糙的索引粒度在分析超级大宽表的场景中,从存储读取的data size会膨胀得非常厉害,需要用户非常谨慎得设定参数。
Block是列存文件中的压缩单元。每个列存文件的Block都会包含若干个Granule,具体多少个Granule是由参数min_compress_block_size控制,每次列的Block中写完一个Granule的数据时,它会检查当前Block Size有没有达到设定值,如果达到则会把当前Block进行压缩然后写磁盘。
从以上两点可以看出MergeTree的Block既不是定data size也不是定行数的,Granule也不是一个定长的逻辑概念。所以我们需要额外信息快速找到某一个Granule。这就是Mark标识文件的作用,它记录了每个Granule的行数,以及它所在的Block在列存压缩文件中的偏移,同时还有Granule在解压后的Block中的偏移位置。
主键索引:primary.idx是表的主键索引。ClickHouse对主键索引的定义和传统数据库的定义稍有不同,它的主键索引没用主键去重的含义,但仍然有快速查找主键行的能力。ClickHouse的主键索引存储的是每一个Granule中起始行的主键值,而MergeTree存储中的数据是按照主键严格排序的。所以当查询给定主键条件时,我们可以根据主键索引确定数据可能存在的 ,再结合上面介绍的Mark标识,我们可以进一步确定数据在列存文件中的位置区间。ClickHoue的主键索引是一种在索引构建成本和索引效率上相对平衡的粗糙索引。MergeTree的主键序列默认是和Order By序列保存一致的,但是用户可以把主键序列定义成Order By序列的部分前缀。
分区键索引:minmax_time.idx、minmax_region_name.idx是表的分区键索引。MergeTree存储会把统计每个Data Part中分区键的最大值和最小值,当用户查询中包含分区键条件时,就可以直接排除掉不相关的Data Part,这是一种OLAP场景下常用的分区裁剪技术。
Skipping索引:skp_idx_avatar_id_minmax.idx是用户在avatar_id列上定义的MinMax索引。Merge Tree中 的Skipping Index是一类局部聚合的粗糙索引。用户在定义skipping index的时候需要设定granularity参数,这里的granularity参数指定的是在多少个Granule的数据上做聚合生成索引信息。用户还需要设定索引对应的聚合函数,常用的有minmax、set、bloom_filter、ngrambf_v1等,聚合函数会统计连续若干个Granule中的列值生成索引信息。Skipping索引的思想和主键索引是类似的,因为数据是按主键排序的,主键索引统计的其实就是每个Granule粒度的主键序列MinMax值,而Skipping索引提供的聚合函数种类更加丰富,是主键索引的一种补充能力。另外这两种索引都是需要用户在理解索引原理的基础上贴合自己的业务场景来进行设计的。
MergeTree存储在收到一个select查询时会先抽取出查询中的分区键和主键条件的KeyCondition,KeyCondition类上实现了以下三个方法,用于判断过滤条件可能满足的Mark Range。上面讲过MergeTree Data Part中的列存数据是以Granule为粒度被Mark标识数组索引起来的,而Mark Range就表示Mark标识数组里满足查询条件的下标区间。
索引检索的过程中首先会用分区键KeyCondition裁剪掉不相关的数据分区,然后用主键索引挑选出粗糙的Mark Range,最后再用Skipping Index过滤主键索引产生的Mark Range。用主键索引挑选出粗糙的Mark Range的算法是一个不断分裂Mark Range的过程,返回结果是一个Mark Range的集合。起始的Mark Range是覆盖整个MergeTree Data Part区间的,每次分裂都会把上次分裂后的Mark Range取出来按一定粒度步长分裂成更细粒度的Mark Range,然后排除掉分裂结果中一定不满足条件的Mark Range,最后Mark Range到一定粒度时停止分裂。这是一个简单高效的粗糙过滤算法。
使用Skipping Index过滤主键索引返回的Mark Range之前,需要构造出每个Skipping Index的IndexCondition,不同的Skipping Index聚合函数有不同的IndexCondition实现,但判断Mark Range是否满足条件的接口和KeyCondition是类似的。
经过上一小节的索引过滤之后,我们已经得到了需要扫描的Mark Range集合,接下来就应该是数据扫描部分了。这一小节插入简单讲一下MergeTree里的数据Sampling是如何实现的。它并不是在数据扫描过程中实现的,而是在索引检索的过程中就已经完成,这种做法是为了极致的sample效率。用户在建表的时候可以指定主键中的某个列或者表达式作为Sampling键,ClickHouse在这里用了简单粗暴的做法:Sampling键的值必须是数值类型的,并且系统假定它的值是随机均匀分布的一个状态。如果Sampling键的值类型是Uint32,当我们设定sample比率是0.1的时候,索引检索过程中会把sample转换成一个filter条件:Sampling键的值 < Uint32::max * 0.1。用户在使用Sampling功能时必须清楚这个细节,不然容易出现采样偏差。一般我们推荐Sampling键是列值加一个Hash函数进行随机打散。
MergeTree的数据扫描部分提供了三种不同的模式:
Final模式:该模式对CollapsingMergeTree、SummingMergeTree等表引擎提供一个最终Merge后的数据视图。前文已经提到过MergeTree基础上的高级MergeTree表引擎都是对MergeTree Data Part采用了特定的Merge逻辑。它带来的问题是由于MergeTree Data Part是异步Merge的过程,在没有最终Merge成一个Data Part的情况下,用户无法看到最终的数据结果。所以ClickHouse在查询是提供了一个final模式,它会在各个Data Part的多条BlockInputStream基础上套上一些高级的Merge Stream,例如DistinctSortedBlockInputStream、SummingSortedBlockInputStream等,这部分逻辑和异步Merge时的逻辑保持一致,这样用户就可以提前看到“最终”的数据结果了。
Sorted模式:sort模式可以认为是一种order by下推存储的查询加速优化手段。因为每个MergeTree Data Part内部的数据是有序的,所以当用户查询中包括排序键order by条件时只需要在各个Data Part的BlockInputStream上套一个做数据有序归并的InputStream就可以实现全局有序的能力。
Normal模式:这是基础MergeTree表最常用的数据扫描模式,多个Data Part之间进行并行数据扫描,对于单查询可以达到非常高吞吐的数据读取。
接下来展开介绍下Normal模式中几个关键的性能优化点:
并行扫描:传统的计算引擎在数据扫描部分的并发度大多和存储文件数绑定在一起,所以MergeTree Data Part并行扫描是一个基础能力。但是MergeTree的存储结构要求数据不断mege,最终合并成一个Data Part,这样对索引和数据压缩才是最高效的。所以ClickHouse在MergeTree Data Part并行的基础上还增加了Mark Range并行。用户可以任意设定数据扫描过程中的并行度,每个扫描线程分配到的是Mark Range In Data Part粒度的任务,同时多个扫描线程之间还共享了Mark Range Task Pool,这样可以避免在存储扫描中的长尾问题。
数据Cache:MergeTree的查询链路中涉及到的数据有不同级别的缓存设计。主键索引和分区键索引在load Data Part的过程中被加载到内存,Mark文件和列存文件有对应的MarkCache和UncompressedCache,MarkCache直接缓存了Mark文件中的binary内容,而UncompressedCache中缓存的是解压后的Block数据。
SIMD反序列化:部分列类型的反序列化过程中采用了手写的sse指令加速,在数据命中UncompressedCache的情况下会有一些效果。
PreWhere过滤:ClickHouse的语法支持了额外的PreWhere过滤条件,它会先于Where条件进行判断。当用户在sql的filter条件中加上PreWhere过滤条件时,存储扫描会分两阶段进行,先读取PreWhere条件中依赖的列值,然后计算每一行是否符合条件。相当于在Mark Range的基础上进一步缩小扫描范围,PreWhere列扫描计算过后,ClickHouse会调整每个Mark对应的Granule中具体要扫描的行数,相当于可以丢弃Granule头尾的一部分行。
以上是“MergeTree中clickhouse稀疏索引怎么用”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/2000675/blog/4655098



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



