这篇文章将为大家详细讲解有关链路追踪工具Zipkin如何安装使用,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
Zipkin 是一个开放源代码分布式的跟踪系统,每个服务向zipkin报告计时数据,zipkin会根据调用关系通过Zipkin UI生成依赖关系图。
Zipkin提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。为了方便在开发环境我直接采用了In-Memory方式进行存储,生产数据量大的情况则推荐使用Elasticsearch。
Zipkin是一个分布式跟踪系统。它有助于收集解决服务体系结构中的延迟问题所需的时序数据。功能包括该数据的收集和查找。
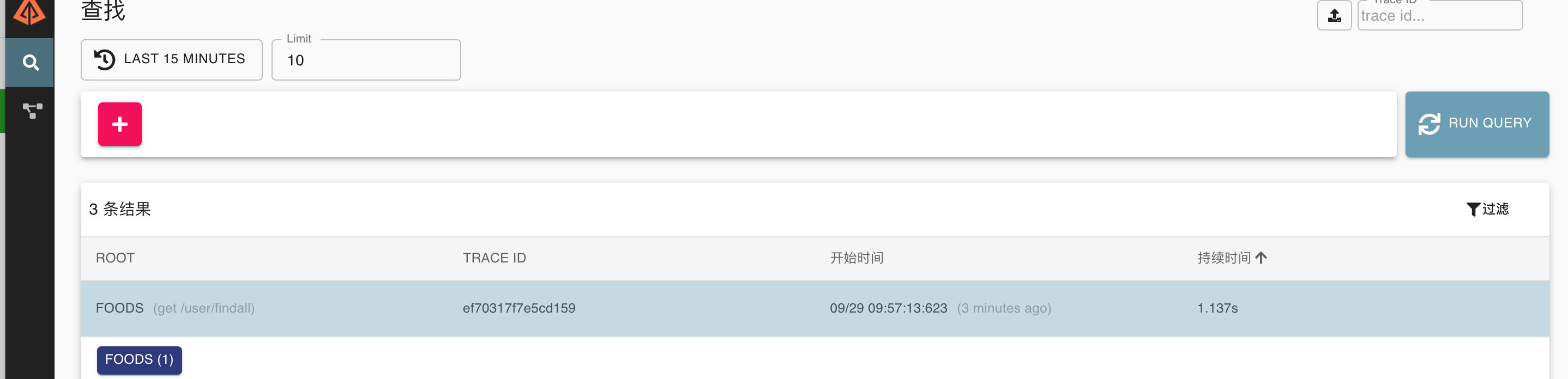
如果日志文件中有跟踪ID,则可以直接跳至该跟踪ID。否则,您可以基于属性进行查询,例如服务,操作名称,标签和持续时间。将为您总结一些有趣的数据,例如在服务中花费的时间百分比以及操作是否失败。
Zipkin UI还提供了一个依赖关系图,该关系图显示了每个应用程序中跟踪了多少个请求。这对于识别包括错误路径或对不赞成使用的服务的调用在内的汇总行为可能会有所帮助。
构建zipkin 服务有三种构建方式,Docker容器是推荐方式、jar安装、源码打包安装;
使用docker容器安装运行
docker run -d -p 9411:9411 openzipkin/zipkin
#或者增加es存储环境
docker run -d -p 9411:9411 \
--env STORAGE_TYPE=elasticsearch \
--env ES_HOSTS=http://192.168.0.100:9200 \
openzipkin/zipkin使用ElasticSearch进行存储,默认启动方式会将日志数据存在内存中,一旦服务重启会清空数据,建议使用es进行持久化存储。启动示例参数如下:
STORAGE_TYPE=elasticsearch ES_HOSTS=http://192.168.0.100:9200
另外还有一些其它可配置参数
* `ES_HOSTS`: A comma separated list of elasticsearch base urls to connect to ex. http://host:9200.
Defaults to "http://localhost:9200".
* `ES_PIPELINE`: Only valid when the destination is Elasticsearch 5+. Indicates the ingest
pipeline used before spans are indexed. No default.
* `ES_TIMEOUT`: Controls the connect, read and write socket timeouts (in milliseconds) for
Elasticsearch Api. Defaults to 10000 (10 seconds)
* `ES_MAX_REQUESTS`: Only valid when the transport is http. Sets maximum in-flight requests from
this process to any Elasticsearch host. Defaults to 64.
* `ES_INDEX`: The index prefix to use when generating daily index names. Defaults to zipkin.
* `ES_DATE_SEPARATOR`: The date separator to use when generating daily index names. Defaults to '-'.
* `ES_INDEX_SHARDS`: The number of shards to split the index into. Each shard and its replicas
are assigned to a machine in the cluster. Increasing the number of shards
and machines in the cluster will improve read and write performance. Number
of shards cannot be changed for existing indices, but new daily indices
will pick up changes to the setting. Defaults to 5.
* `ES_INDEX_REPLICAS`: The number of replica copies of each shard in the index. Each shard and
its replicas are assigned to a machine in the cluster. Increasing the
number of replicas and machines in the cluster will improve read
performance, but not write performance. Number of replicas can be changed
for existing indices. Defaults to 1. It is highly discouraged to set this
to 0 as it would mean a machine failure results in data loss.
* `ES_USERNAME` and `ES_PASSWORD`: Elasticsearch basic authentication, which defaults to empty string.
Use when X-Pack security (formerly Shield) is in place.
* `ES_HTTP_LOGGING`: When set, controls the volume of HTTP logging of the Elasticsearch Api.
Options are BASIC, HEADERS, BODY服务启动后默认可以通过9411端口访问zipkin的监控页面
http://localhost:9411/zipkin/
注:zipkin会在es中创建以zipkin开头日期结尾的index,并且默认以天为单位分割,使用该存储模式时,zipkin中的依赖信息会无法显示,需要通过zipkin-dependencies工具包计算。
使用jar运行
如果您安装了Java 8或更高版本,那么最快速的安装方法是以独立的可执行jar形式获取最新版本:
curl -sSL https://zipkin.io/quickstart.sh | bash -s java -jar zipkin.jar
使用源码安装运行
如果要开发新功能,则可以从源代码运行Zipkin。为此,您需要获取Zipkin的源代码并进行构建。
# 获取最新源码git地址
git clone https://github.com/openzipkin/zipkin
cd zipkin
# mvn编译打包
./mvnw -DskipTests --also-make -pl zipkin-server clean install
# jar包运行
java -jar ./zipkin-server/target/zipkin-server-*exec.jarzipkin-dependencies基于spark job来生成全局的调用链,下载地址:https://github.com/openzipkin/zipkin-dependencies
STORAGE_TYPE=elasticsearch ES_HOSTS=127.0.0.1:9200 java -jar zipkin-dependencies.jar &
下载完成后通过上述命令启动zipkin-dependencies,这里要注意的是程序只会根据当日的zipkin数据实时计算一次依赖关系,并以索引zipkin:dependency-2020-9-28方式存入es中,然后就退出了,因此要做到实时更新依赖的话需要自己想办法实现周期性执行zipkin-dependencies`。
<properties>
<spring.cloud-version>Hoxton.SR8</spring.cloud-version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring.cloud-version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>spring:
zipkin:
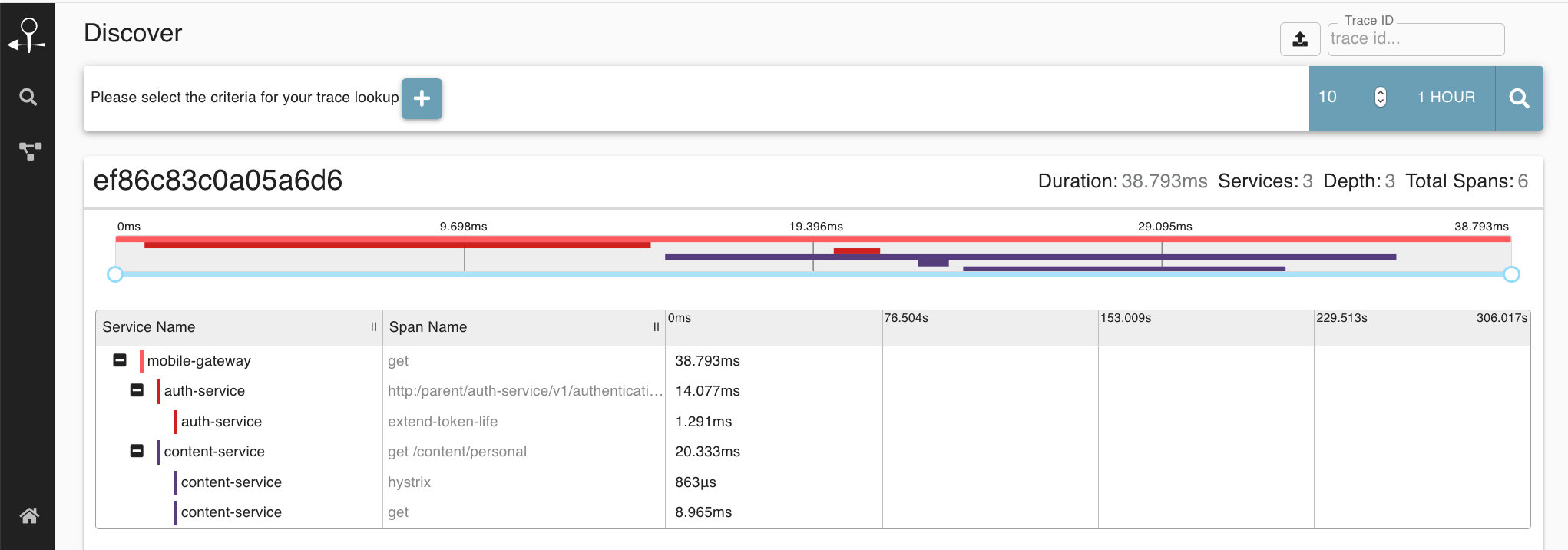
base-url: http://127.0.0.1:9411这里的base-url是zipkin服务端的地址,默认地址也是http://localhost:9411/ ,配置好后,我们访问我们服务的API,点击run query即可有如下图追踪信息。
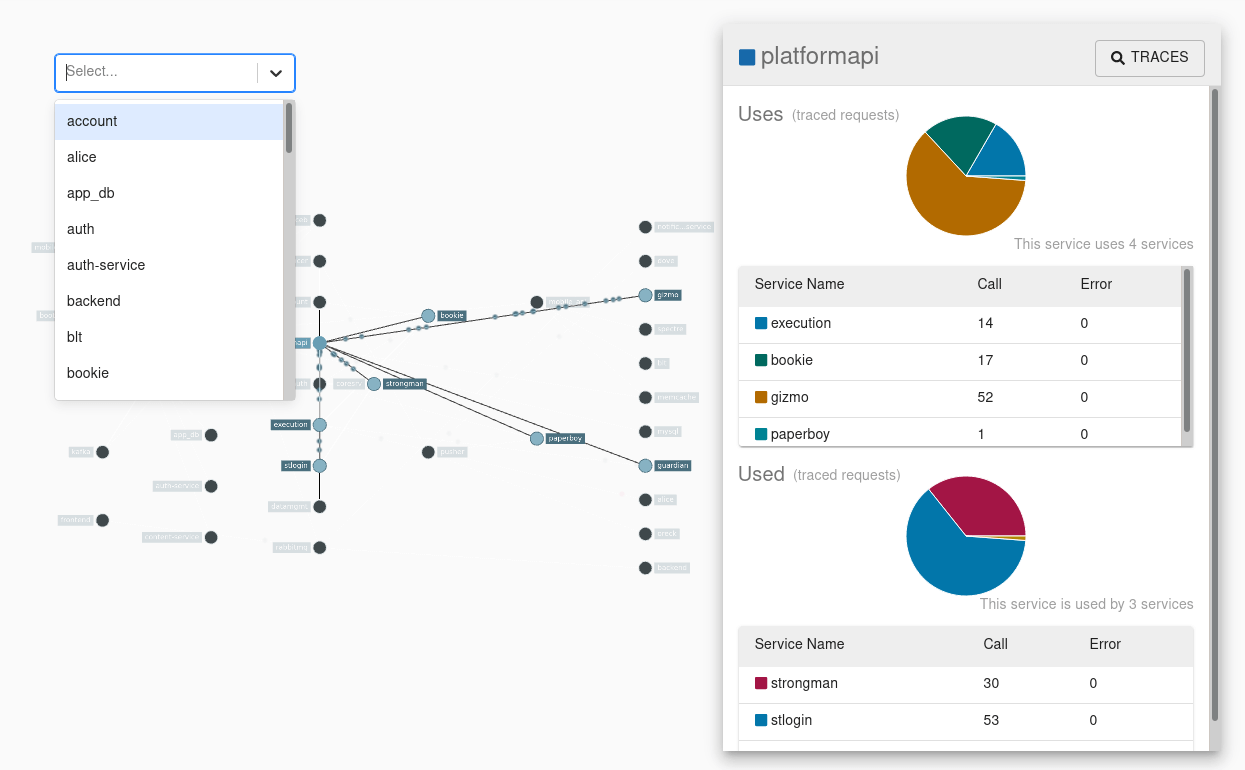
阿里云商业链路追踪(TracingAnalysis)为分布式应用的开发者提供了完整的调用链路还原、调用请求量统计、链路拓扑、应用依赖分析等工具。能够帮助开发者快速分析和诊断分布式应用架构下的性能瓶颈,提高微服务时代下的开发诊断效率。
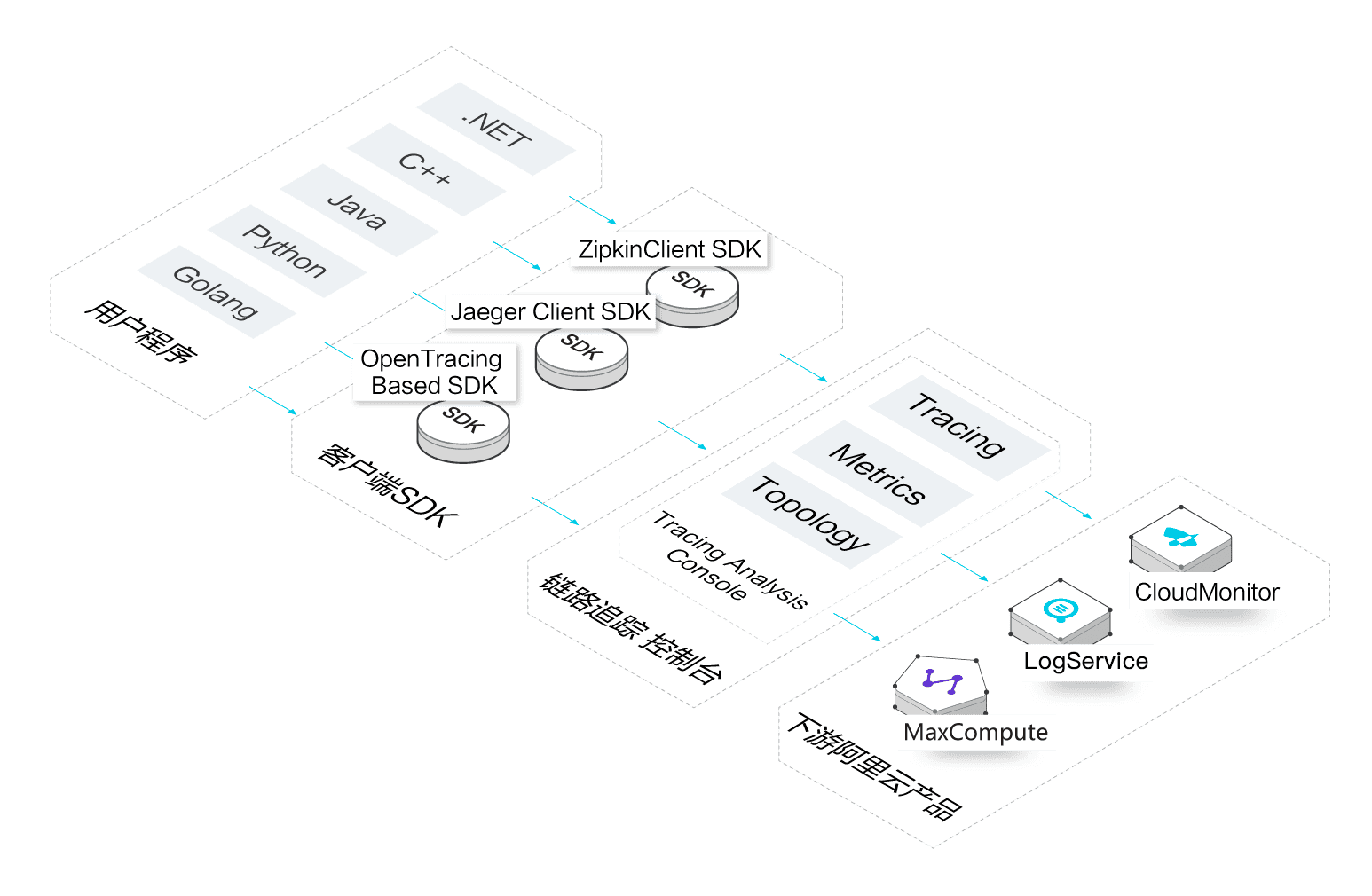
链路追踪的产品架构如图所示。
图 1. 链路追踪产品架构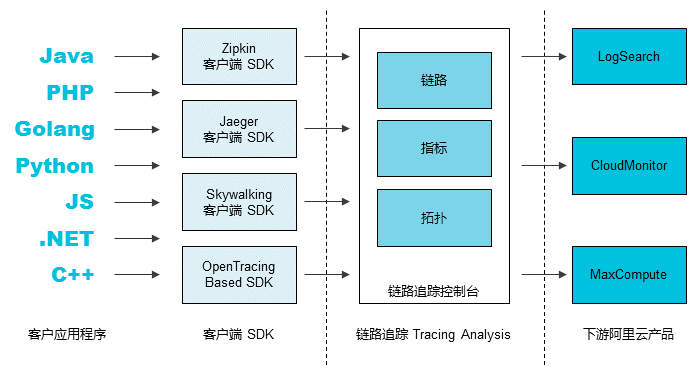
主要工作流程为:
客户侧的应用程序通过集成链路追踪的多语言客户端 SDK 上报服务调用数据。链路追踪支持多种开源社区的 SDK,且支持 OpenTracing 标准。
数据上报至链路追踪控制台后,链路追踪组件进行实时聚合计算和持久化,形成链路明细、性能总览、实时拓扑等监控数据。您可以据此进行问题排查与诊断。
调用链数据可对接下游阿里云产品,例如 LogSearch、CloudMonitor、MaxCompute 等,用于离线分析、报警等场景。
链路追踪的主要功能有:
分布式调用链查询和诊断:追踪分布式架构中的所有微服务用户请求,并将它们汇总成分布式调用链。
应用性能实时汇总:通过追踪整个应用程序的用户请求,来实时汇总组成应用程序的单个服务和资源。
分布式拓扑动态发现:用户的所有分布式微服务应用和相关 PaaS 产品可以通过链路追踪收集到的分布式调用信息。
多语言开发程序接入:基于 OpenTracing 标准,全面兼容开源社区,例如 Jaeger 和 Zipkin。
丰富的下游对接场景:收集的链路可直接用于日志分析,且可对接到 MaxCompute 等下游分析平台。
关于“链路追踪工具Zipkin如何安装使用”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/1041902/blog/4654440



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



