这篇文章主要介绍Flink中有界数据与无界数据的示例分析,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
有界数据集对开发者来说都很熟悉,在常规的处理中我们都会从Mysql,文本等获取数据进行计算分析。我们在处理此类数据时,特点就是数据是静止不动的。也就是说,没有再进行追加。又或者说再处理的当时时刻不考虑追加写入操作。所以有界数据集又或者说是有时间边界。在某个时间内的结果进行计算。那么这种计算称之为批计算,批处理。Batch Processing

例如:计算当前订单量。又或者是把当前mysql的数据读取到文件中等。
对于某些场景,类似于Kafka持续的计算等都被认定为无界数据集,无界数据集是会发生持续变更的、连续追加的。例如:服务器信令、网络传输流、实时日志信息等。对于此类持续变更、追加的数据的计算方式称之为流计算。Streaming Processing
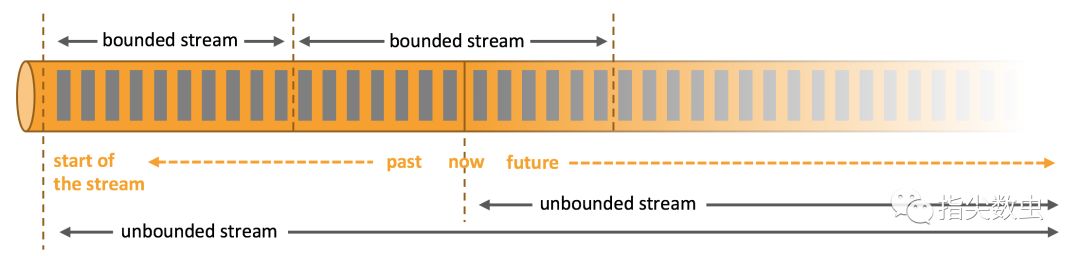
无界数据集与有界数据集有点类似于池塘和江河,我们在计算池塘中的鱼的数量时只需要把池塘中当前所有的鱼都计算一次就可以了。那么当前时刻,池塘中有多少条鱼就是结果。无界数据集类似于江河中的鱼,在奔流到海的过程中每时每刻都会有鱼流过而进入大海。那么计算鱼的数量就像是持续追加的。

有界数据集与无界数据集是一个相对模糊的概念,如果数据一条一条的经过处理引擎那么则可以认为是无界的,那么如果每间隔一分钟、一小时、一天进行一次计算那么则认为这一段时间的数据又相对是有界的。有界的数据又可以把数据一条一条的通过计算引擎,造成无界的数据集。所以,有界数据集与无界数据集可以存在互换的。因此业内也就开始追寻 批流统一 的框架。 
能够同时实现批处理与流处理的框架有Apache Spark和Apache Flink,而Apache Spark的流处理场景是一个微批场景,也就是它会在特定的时间间隔发起一次计算。而不是每条都会触发计算。也就是相当于把无界数据集切分为小量的有界数据。
Apache Flink基于有界数据集与无界数据集的特点,最终将批处理与流处理混合到同一套引擎当中,用户使用Apache Flink引擎能够同时实现批处理与流处理任务。
以上是“Flink中有界数据与无界数据的示例分析”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/CainGao/blog/4425186



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



