这篇文章主要讲解了“Hive的join底层mapreduce是如何实现的”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Hive的join底层mapreduce是如何实现的”吧!
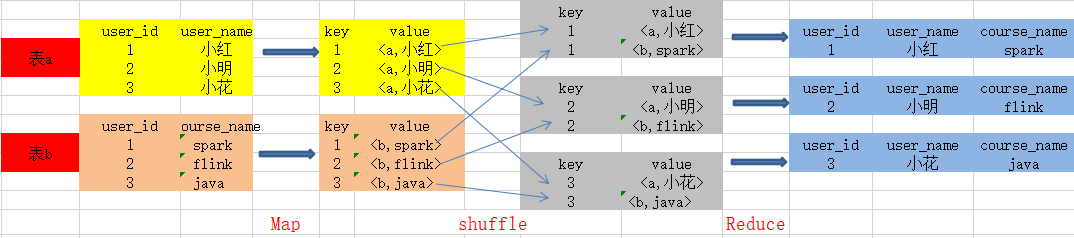
读取表的数据,Map输出时候以 Join on 条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Map输出的 value 为 join 之后需要输出或者作为条件的列;同时在value中还会包含表的 Tag 信息,用于标明此value对应的表;按照key进行排序
根据key取哈希值,并将key/value按照哈希值分发到不同的reduce中
根据key的值完成join操作,并且通过Tag来识别不同表中的数据。在合并过程中,把表编号扔掉
drop table if exists wedw_dwd.user_info_df; CREATE TABLE wedw_dwd.user_info_df( user_id string COMMENT '用户id', user_name string COMMENT '用户姓名' )row format delimited fields terminated by '\t' STORED AS textfile ; +----------+------------+--+| user_id | user_name |+----------+------------+--+| 1 | 小红 || 2 | 小明 || 3 | 小花 |+----------+------------+--+ drop table if exists wedw_dwd.order_info_df; CREATE TABLE wedw_dwd.order_info_df( user_id string COMMENT '用户id', course_name string COMMENT '课程名称' )row format delimited fields terminated by '\t' STORED AS textfile ; +----------+--------------+--+| user_id | course_name |+----------+--------------+--+| 1 | spark || 2 | flink || 3 | java |+----------+--------------+--+select t1.user_id,t1.user_name,t2.course_namefromwedw_dwd.user_info_df t1join wedw_dwd.order_info_df t2on t1.user_id = t2.user_id;+----------+------------+--------------+--+| user_id | user_name | course_name |+----------+------------+--------------+--+| 1 | 小红 | spark || 2 | 小明 | flink || 3 | 小花 | java |+----------+------------+--------------+--+图解:(在合并过程中,把表编号扔掉)
感谢各位的阅读,以上就是“Hive的join底层mapreduce是如何实现的”的内容了,经过本文的学习后,相信大家对Hive的join底层mapreduce是如何实现的这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4631230/blog/4641969



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



