本篇内容主要讲解“Hive动态分区表的作用是什么”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Hive动态分区表的作用是什么”吧!
1.对于分区数量很多的分区表,可以使用动态分区让hive帮你自动创建所需的分区表:

以上两个参数分别表示:
是否开启动态分区插入方式,默认为false;
是否使用严格模式。在严格模式下,必须至少指定一个静态列,以防止用户不小心一次重写了所有分区。
如果使用非严格模式,则插入的时候需要指定一个额外的数据列来表示虚拟分区列的值,如:
set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; create table test1(a int); create table test2(a int) partitioned by (parid int); insert into table test2 partition (parid) select *,par_id from test1;
否则会出现类似如下错误:
Error: Error while processing statement: FAILED: SemanticException [Error 10044]: Line 1:18 Cannot insert into target table because column number/types are different 'parid': Table insclause-0 has 2 columns, but query has 1 columns. (state=42000,code=10044)
最后执行命令:hdfs dfs -ls /user/hive/warehouse/test2,便可查看到hdfs中自动创建好了分区文件夹。
注意:
使用过程中发现hive的insert及alter语法不够灵活,如不支持insert into..values..、不支持alter table test add partition(parid int)等等。另外,关于Load data语法的使用,目前是不支持动态分区的。现在对数据类型的支持也在逐渐完善中,如date及timestamp类型都在最近的版本得到支持。
更多关于hive分区表的介绍参见:hive中简单介绍分区表(partition table),含动态分区(dynamic partition)与静态分区(static partition)
hive1的连接命令是:su -c hive hdfs
hive2添加了新的client:beeline -u jdbc:hive2://localhost/ -n hive
beeline还提供了一些内置命令,使用“!help”或者“?”可以查看。此外,beeline的交互性也更强,比如错误提示和数据展示都更加友好。
2.上面简单介绍了hive动态分区表的使用,接下来的一个小demo是使用Java连接hive。hive不等同于关系型数据库,本身不存储数据也不提供对数据的操作方法,如果要使用jdbc连接hive,必须启动了hive-server,默认连接端口是10000。代码如下所示:
private static void hive() throws Exception {
// Class.forName("org.apache.hadoop.hive.jdbc.HiveDriver");
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection con = DriverManager.getConnection("jdbc:hive2://127.0.0.1:10000/default", "hive", "");
PreparedStatement ps = con.prepareStatement("insert into table test select ? from test2 limit 1");
ps.setString(1, new Timestamp(new java.util.Date().getTime()).toString());
ps.executeUpdate();
ps.setString(1, "2011-11-11 11:11:11");
ps.executeUpdate();
// stmt.execute("set hive.support.concurrency=true");
Statement stmt = con.createStatement();
ResultSet rs = stmt.executeQuery("select * from test");
int columnSize = rs.getMetaData().getColumnCount();
while (rs.next()) {
for (int i = 1; i <= columnSize; i++)
System.out.print(rs.getString(i) + ",");
System.out.println();
}
rs.close();
stmt.close();
con.close();
}注意:
以上代码中注释的部分是在hive1中使用的。hive1不支持并发操作,jdbc驱动也不一致。另外,关于所需的jar包分别如下图所示:
Hiveserver1: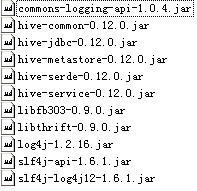
Hiveserver2: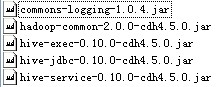 或
或
上面hive2使用的是CDH4的hadoop包,其中的hive-exec-0.10.0-cdh5.5.0.jar是一个整合包,亦可使用最右边的包替换。hive两个版本的jdbc驱动包也不一致。如果使用标准hadoop包的话还需要更多依赖包,否则可能会因为hadoop RPC协议不一致而报如下错误:
Caused by: org.apache.thrift.protocol.TProtocolException: Required field 'serverProtocolVersion' is unset! Struct:TOpenSessionResp(status:TStatus(statusCode:SUCCESS_STATUS), serverProtocolVersion:null, sessionHandle:TSessionHandle(sessionId:THandleIdentifier(guid:A0 3F 2D 35 DD BD 47 6C 80 B6 36 83 1A DB 60 4C, secret:F6 13 B5 E3 20 65 48 F5 9A F4 0F 04 A2 FC 30 B2)), configuration:{})
若不是使用CDH包报错:Could not locate executable null\bin\winutils.exe in the Hadoop binaries。则替换hadoop-common为最新的包,参考:https://issues.cloudera.org/browse/DISTRO-544,Win7 Eclipse调试Centos Hadoop2.2-Mapreduce
目前hive提供的jdbc包功能还比较弱,比如:不支持Statement的批量操作相关的方法,包括addBatch()、batchUpdate()以及其子类Preparestatement的setObject()、setNull()等方法,Connection对象不支持事务相关的操作,如setAutoCommit()、rollback()等,ResultSet的滚动相关操作如getRows()、first()等等,虽然hive支持事务,但是在API中只能通过程序控制来实现。此外,测试发现insert操作数据插入的效率极其低下,当然这也与hive本身的工作模式有关。
到此,相信大家对“Hive动态分区表的作用是什么”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





