这篇文章主要为大家展示了“Hadoop文件读取的示例分析”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“Hadoop文件读取的示例分析”这篇文章吧。
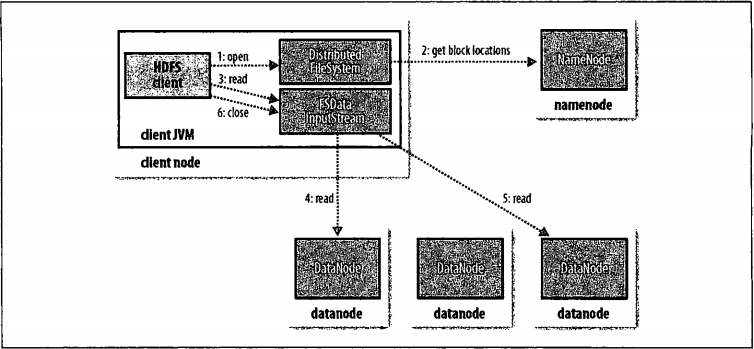
客户端通过调用FileSystem对象的open()方法来打开希望读取的文件,对于HDFS来说,这个对象是分布式系统(步骤1)的一个实例。DistributedFileSystem通过使用RPC来调用namenode,以确定文件起始块的位置(步骤2),对于每一个块,namenode返回存有该块复本的datanode地址,此外,这些datanode(比如,在一个MapReduce任务中),并保存有相应数据库的一个复本时,该节点将本地datanode中读取数据。DistributedFileSystem累返回一个FSDataInputStream对象(一个支持文件定位的输入流)给客户端并读取数据。FSDataInputStream类转而封装DFSInputStream对象,该对象管理着datanode和namenode的I/O,接着,客户端对这个输入流调用read()方法(步骤3)。存储着文件起始块的datanode地址的DFSInputStream随机连接距离最近的datanode。通过对数据流反复调用read()方法,可以将数据从datanode传输到客户端(步骤4).到达块的末端时,DFSInputStream会关闭与该datanode的连接,然后需找下一个块的最近datanode(步骤5)。客户端只需要读取连续的流,并且操作对于客户端都是透明的。客户端从流中读取数据时,块是按照打开DFSInputStream与datanode新建连接的顺序读取的,它也需要询问namenode来检索下一批所需快的datanode的位置,一旦客户端完成读取,就对FSDataInputStream调用close()方法(步骤6)。在读取数据的时候,如果DFSInputStream在与datanode通信时遇到错误,它便会尝试从这个快的另外一个最领近datanode读取数据。它也会机主那个故障datanode,以保证以后不会反复读取该节点上后续的块。DFSInputStream也会通过校验和确认从datanode发来的数据是否完整。如果发现一个损坏的块,它就会在DFSInputStream视图从其他datanode读取一个块的复本之前通知namenode。这个设计的一个重点是:namenode告知客户端每个块中最近的datanode,并让客户端直接联系该datanode且检索锁具。由于数据流分散在该集群中的所有datanode,所以这种设计能使HDFS可扩展到大量的并发客户端。同时,namenode仅需要相应块位置的请求(这些信息存储在内存中,因而非常高效),而无需相应数据请求,否则随着客户端数据的增长,namenode很快会变为一个瓶颈。
以上是“Hadoop文件读取的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





