Kafka是大数据领域无处不在的消息中间件,目前广泛使用在企业内部的实时数据管道,并帮助企业构建自己的流计算应用程序。Kafka虽然是基于磁盘做的数据存储,但却具有高性能、高吞吐、低延时的特点,其吞吐量动辄几万、几十上百万。但是很多使用过Kafka的人,经常会被问到这样一个问题,Kafka为什么速度快,吞吐量大;大部分被问的人都是一下子就懵了,或者是只知道一些简单的点,本文就简单的介绍一下Kafka为什么速度快,吞吐量大。
众所周知Kafka是将消息记录持久化到本地磁盘中的,一般人会认为磁盘读写性能差,可能会对Kafka性能如何保证提出质疑。实际上不管是内存还是磁盘,快或慢关键在于寻址的方式,磁盘分为顺序读写与随机读写,内存也一样分为顺序读写与随机读写。基于磁盘的随机读写确实很慢,但磁盘的顺序读写性能却很高,一般而言要高出磁盘随机读写三个数量级,一些情况下磁盘顺序读写性能甚至要高于内存随机读写,这里给出著名学术期刊 ACM Queue 上的一张性能对比图: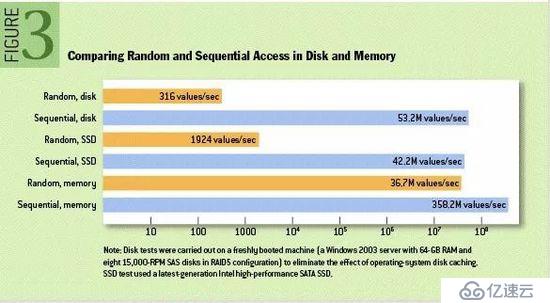
磁盘的顺序读写是磁盘使用模式中最有规律的,并且操作系统也对这种模式做了大量优化,Kafka就是使用了磁盘顺序读写来提升的性能。Kafka的message是不断追加到本地磁盘文件末尾的,而不是随机的写入,这使得Kafka写入吞吐量得到了显著提升 。
为了优化读写性能,Kafka利用了操作系统本身的Page Cache,就是利用操作系统自身的内存而不是JVM空间内存。这样做的好处有:
相比于使用JVM或in-memory cache等数据结构,利用操作系统的Page Cache更加简单可靠。首先,操作系统层面的缓存利用率会更高,因为存储的都是紧凑的字节结构而不是独立的对象。其次,操作系统本身也对于Page Cache做了大量优化,提供了 write-behind、read-ahead以及flush等多种机制。再者,即使服务进程重启,系统缓存依然不会消失,避免了in-process cache重建缓存的过程。
通过操作系统的Page Cache,Kafka的读写操作基本上是基于内存的,读写速度得到了极大的提升。
这里主要讲的是Kafka利用 linux 操作系统的 “零拷贝(zero-copy)” 机制在消费端做的优化。首先来了解下数据从文件发送到socket网络连接中的常规传输路径:
这个过程包含4次copy操作和2次系统上下文切换,性能其实非常低效。linux操作系统 “零拷贝” 机制使用了sendfile方法, 允许操作系统将数据从Page Cache 直接发送到网络,只需要最后一步的copy操作将数据复制到 NIC 缓冲区, 这样避免重新复制数据 。示意图如下:
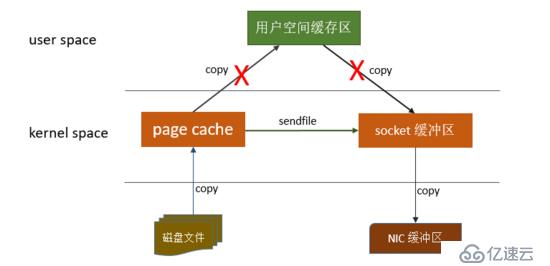
通过这种 “零拷贝” 的机制,Page Cache 结合 sendfile 方法,Kafka消费端的性能也大幅提升。这也是为什么有时候消费端在不断消费数据时,我们并没有看到磁盘io比较高,此刻正是操作系统缓存在提供数据。
Kafka的message是按topic分类存储的,topic中的数据又是按照一个一个的partition即分区存储到不同broker节点。每个partition对应了操作系统上的一个文件夹,partition实际上又是按照segment分段存储的。这也非常符合分布式系统分区分桶的设计思想。
通过这种分区分段的设计,Kafka的message消息实际上是分布式存储在一个一个小的segment中的,每次文件操作也是直接操作的segment。为了进一步的查询优化,Kafka又默认为分段后的数据文件建立了索引文件,就是文件系统上的.index文件。这种分区分段+索引的设计,不仅提升了数据读取的效率,同时也提高了数据操作的并行度。
Kafka采用顺序读写、Page Cache、零拷贝以及分区分段等这些设计,再加上在索引方面做的优化,另外Kafka数据读写也是批量的而不是单条的,使得Kafka具有了高性能、高吞吐、低延时的特点。这样,Kafka提供大容量的磁盘存储也变成了一种优点。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





