SplunkжҳҜд»Җд№Ҳ
иҝҷзҜҮвҖңSplunkжҳҜд»Җд№ҲвҖқж–Үз« зҡ„зҹҘиҜҶзӮ№еӨ§йғЁеҲҶдәәйғҪдёҚеӨӘзҗҶи§ЈпјҢжүҖд»Ҙе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеҶ…е®№иҜҰз»ҶпјҢжӯҘйӘӨжё…жҷ°пјҢе…·жңүдёҖе®ҡзҡ„еҖҹйүҙд»·еҖјпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« иғҪжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘзңӢзңӢиҝҷзҜҮвҖңSplunkжҳҜд»Җд№ҲвҖқж–Үз« еҗ§гҖӮ
SplunkжҳҜе•Ҙпјҹ
SplunkжҳҜж—Ҙеҝ—/жөҒејҸж•°жҚ®йўҶеҹҹдёӯеҒҡзҡ„жңҖеҘҪзҡ„е•ҶдёҡиҪҜ件е®һзҺ°пјҢе®ғзҡ„ж ёеҝғиғҪеҠӣеҸӘжңүдёҖдёӘпјҡ
еғҸGoogleйӮЈж ·жҗңзҙўдјҒдёҡеҶ…йғЁжүҖжңүдә§з”ҹзҡ„ж—Ҙеҝ—
иҝҷдёӘзҡ„еЁҒеҠӣйқһеёёеӨ§пјҢзҺ°еңЁзҡ„дјҒдёҡдёҚзјәж•°жҚ®пјҢзјәзҡ„жҳҜжңүж•ҲжҢ–жҺҳж•°жҚ®зҡ„иғҪеҠӣгҖӮиҖҢжҳҫ然еӨ§йғЁеҲҶдјҒдёҡжІЎжңүGoogleзҡ„иғҪеҠӣеҺ»еҒҡжҗңзҙўпјҢдәҺжҳҜSplunkжҸҗдҫӣиҝҷж ·зҡ„иғҪеҠӣгҖӮдёҺд№Ӣзӣёз«һдәүзҡ„ејҖжәҗе®һзҺ°жңүLogstashгҖӮ
Splunk вүҲ Logstash
Logstash = Redis(дј иҫ“) + ElasticSearch(жҗңзҙў) + Kibana(еұ•зҺ°)
ElasticSearch = Lucene + Search
йӮЈд№ҲпјҢе“ӘйҮҢеҸҜд»Ҙд№°еҲ°е‘ўпјҹ##
Splunkе®ҳзҪ‘дёҠжңүпјҢжҲ‘е°ұдёҚжӣҝ他们еҒҡе№ҝе‘ҠдәҶпјҢжҖ»д№ӢпјҢеҫҲиҙөпјҢдёҖдёҮзҫҺе…ғиғҪд№°1Gзҡ„жөҒйҮҸжҜҸеӨ©гҖӮиЁҖеҪ’жӯЈдј пјҢжҲ‘иҝҳжҳҜеҲҶжһҗдёҖдёӢиҝҷдёӘзҺ©ж„Ҹе„ҝзҡ„дёҖдәӣеҠҹиғҪзү№жҖ§еҗ§гҖӮ
йҰ–е…ҲпјҢSplunkжңүдёҖдёӘеҫҲзӮ«й…·зҡ„з•Ңйқў
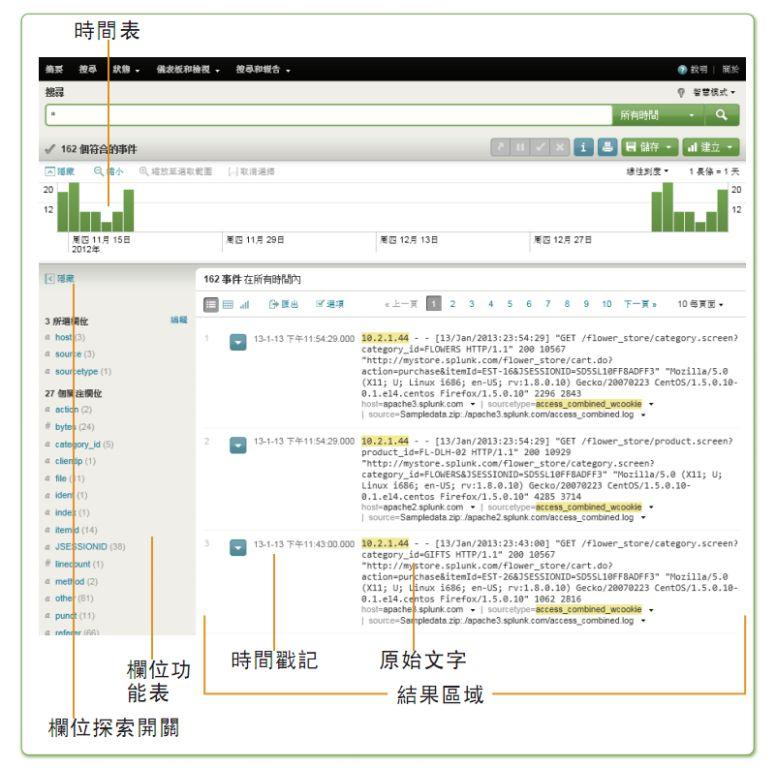
еҸҜд»ҘзңӢеҲ°пјҢSplunkзҡ„дё»иҰҒдҪҝз”Ёж–№ејҸе°ұжҳҜйӮЈдёӘжҗңзҙўжЎҶпјҢеңЁйҮҢйқўиҫ“е…ҘдёҖз§ҚеҸ«еҒҡSPLзҡ„жҗңзҙўиҜӯиЁҖпјҢе°ұиғҪиҺ·еҸ–еҲ°дҪ жғіиҰҒзҡ„еҗ„з§ҚдҝЎжҒҜдәҶгҖӮSplunkиғҪеңЁеҗҺеҸ°еҜ№ж•°жҚ®иҝӣиЎҢиҝҮж»ӨгҖҒиҒҡеҗҲгҖҒз»ҹи®ЎпјҢжңҖеҗҺеҫ—еҲ°еҗ„з§ҚжҠҘиЎЁгҖҒеӣҫеғҸ
SPLжҳҜдёҖз§Қеҗ‘SQLиҮҙ(chao)敬(xi)зҡ„иҜӯиЁҖпјҢиҜӯжі•йқһеёёзҡ„зұ»дјјпјҢдёҚеҗҢзҡ„жҳҜпјҢSPLжҗңзҙўзҡ„дёҚжҳҜе…ізі»ж•°жҚ®еә“пјҢиҖҢжҳҜиҫ“е…ҘеҲ°Splunkзі»з»ҹдёӯжүҖжңүзҡ„ж—Ҙеҝ—ж•°жҚ®пјҢд»ҘдёӢжҳҜеҮ дёӘе…·дҪ“зҡ„жЎҲдҫӢпјҡ
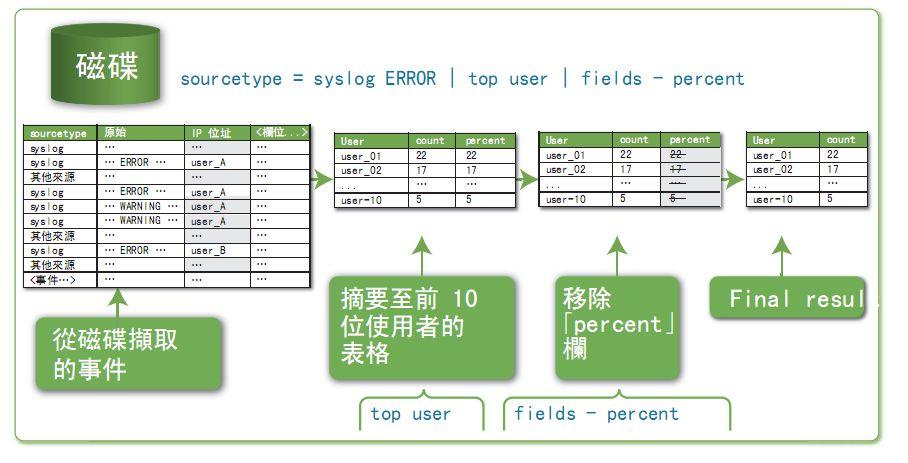
еҸҜд»ҘзңӢеҲ°пјҢеҜ№дәҺдёҖиЎҢSPLжҗңзҙўиҜӯеҸҘ
sourcetype = syslog ERROR | top user | fields - precent
SplunkжҳҜиҝҷд№Ҳе№Ізҡ„пјҢ
йҰ–е…Ҳд»ҺзЎ¬зӣҳдёҠжҗңзҙўеӯ—ж®өsourcetypeпјҲжқҘжәҗзұ»еһӢпјүдёәsyslogзҡ„ж—Ҙеҝ—пјҢеҗҢж—¶пјҢеңЁж—Ҙеҝ—дёӯеҗ«жңүERRORиҝҷдёӘе…ій”®еӯ—зҡ„гҖӮ
йҖҡиҝҮз®ЎйҒ“з¬ҰпјҢжҠҠдёҠйқўзҡ„жҗңзҙўз»“жһңж №жҚ®userеӯ—ж®өеҒҡиҒҡеҗҲпјҢеҸ–еҮәе…¶дёӯеҮәзҺ°ж¬Ўж•°жңҖеӨҡзҡ„еүҚ10дёӘ
еҶҚйҖҡиҝҮз®ЎйҒ“з¬ҰпјҢеҺ»жҺүзҷҫеҲҶжҜ”еӯ—ж®өпјҢжңҖеҗҺеҫ—еҮәз»“жһң
жңҖеҗҺзңӢеҲ°пјҢиҝҷдёӘжҗңзҙўе№ІдәҶд»Җд№ҲдәӢжғ…е‘ўпјҹе®ғдёҖдёӢеӯҗе°ұжҠҠж—Ҙеҝ—дёӯеҮәй”ҷжңҖеӨҡзҡ„еүҚеҚҒдёӘз”ЁжҲ·з»ҷз»ҹи®ЎеҮәжқҘдәҶпјҢиҝҷж ·еҗҺз»ӯзЁӢеәҸе‘ҳе°ұиғҪи·ҹиёӘиҝҷдәӣй”ҷиҜҜдёәд»Җд№Ҳдә§з”ҹпјҢ然еҗҺзқҖжүӢеҺ»и§ЈеҶігҖӮ

| where distance/time > 100
дҪҝз”ЁwhereпјҢеҜ№ж—Ҙеҝ—дёӯдёӨдёӘеӯ—ж®өиҝӣиЎҢзӣёйҷӨеҗҺжҜ”иҫғгҖӮ
еүҚеӣ еҗҺжһңжһ¶жһ„еӣҫ

Splunkдё»иҰҒеҒҡдәҶ3件дәӢ
и§ЈжһҗеҺҹе§Ӣж—Ҙеҝ—ж јејҸпјҢеҲҶи§ЈжҲҗжңүж„Ҹд№үзҡ„еӯ—ж®өпјҢжңүзҡ„ log 收йӣҶж–№жЎҲеңЁз¬¬дёҖйҳ¶ж®өе°ұи§Јжһҗж—Ҙеҝ—еҸӘеҸ‘йҖҒе…іеҝғзҡ„еӯ—ж®өпјҢд»ҘиҠӮзңҒеёҰе®ҪгҖӮ
ж №жҚ®ж—¶й—ҙжҲіпјҢrequest IDпјҢsession IDпјҢuser ID зӯүе…іиҒ”ж—Ҙеҝ—жқЎзӣ®пјҢд»Ҙе°ҪйҮҸжё…жҷ°еҪ“ж—¶еҗ„дёӘеӯҗзі»з»ҹзҡ„зҠ¶жҖҒпјӣ
ж №жҚ®еҲҶжһҗзҡ„зӣ®зҡ„еҒҡиҝҮж»ӨгҖҒиҒҡеҗҲгҖҒз»ҹи®ЎзӯүзӯүпјҢжңҖеҗҺж•ҙдёҖд»ҪжјӮдә®зҡ„жҠҘиЎЁеҮәжқҘгҖӮ
SplunkеҮәеҪ©зҡ„зү№жҖ§жҳҜвҖҰвҖҰ
WEBзҡ„UIеҫҲеҮәиүІпјҢжҸ’件ејҸзҡ„пјҢжҠҠиҝҷдёӘеҒҡжҲҗдәҶдёҖдёӘе№іеҸ°пјҢе…Ғи®ёеҫҲеӨҡ第дёүж–№зҡ„е…¬еҸёеңЁдёҠйқўеҸ‘еёғеә”з”ЁгҖӮ
жҗңзҙўиҜӯжі•ејәеӨ§пјҢдҫӢеҰӮжҹҘжүҫHTTP 503й”ҷиҜҜиҝ‘жңҹзҡ„еҮәзҺ°йў‘зҺҮпјҢдҫӢеҰӮжҹҗдёҖдёӘең°еҢәз”ЁжҲ·и®ҝй—®жңҖеӨҡзҡ„е•Ҷе“ҒеҲ—иЎЁпјҢдҫӢеҰӮйЎөйқўи®ҝй—®йҮҸжҺ’еҗҚгҖӮеҹәжң¬дёҠпјҢдҪ иғҪжғіеҲ°зҡ„еҸҜд»Ҙз”ұSQLе®ҢжҲҗзҡ„жҗңзҙўпјҢSPLйғҪиғҪеӨҹеҒҡеҮәжқҘгҖӮ
иҮӘеҠЁзҢңжөӢдёҖдәӣж—Ҙеҝ—зҡ„еӯ—ж®өпјҢеҗҢж—¶еҸҜд»ҘеңЁWebдёҠжүӢеҠЁи°ғж•ҙжҖҺд№Ҳи§ЈжһҗжәҗеӨҙж—Ҙеҝ—гҖӮ
д»ҘдёҠжүҖжңүж“ҚдҪңпјҢйғҪиғҪз”ұжҺҢжҸЎSPLиҜӯиЁҖзҡ„йқһзЁӢеәҸе‘ҳжқҘе®ҢжҲҗпјҢд№ҹе°ұжҳҜиҜҙSplunkеҸҜд»Ҙз”ұдә§е“Ғз»ҸзҗҶжҲ–иҖ…иҝҗиҗҘеӣўйҳҹжқҘж“ҚжҺ§гҖӮиҖҢдё”иҝҳиғҪжҠҠж•°жҚ®еҸҜи§ҶеҢ–еҒҡеҮәжқҘгҖӮ
жөҒејҸжҗңзҙўпјҢе®һж—¶иҝҮж»Өж—Ҙеҝ—然еҗҺжҠҘиӯҰпјҢиҝҷдёӘеҜ№иҝҗз»ҙеӣўйҳҹеҫҲжңүз”ЁгҖӮ
д»ҘдёҠеҮ зӮ№пјҢе°ұеҶіе®ҡдәҶSplunkзҡ„еёӮеңәйқһеёёзҡ„еӨ§пјҢиҝҷ家公еҸёзҡ„жҰӮеҝөжҳҜжөҒејҸж•°жҚ®йўҶеҹҹзҡ„ж•°жҚ®д»“еә“пјҢ2012еңЁзәіж–Ҝиҫҫе…ӢдёҠеёӮпјҢдёҚиҝҮиҝҷдёӨе№ҙиў«дәәеҒҡз©әпјҢиӮЎзҘЁеӨ§и·ҢгҖӮеӣ дёәеҫҲеӨҡдә‘и®Ўз®—еҺӮе•ҶйғҪиғҪжҸҗдҫӣиҝҷз§ҚжңҚеҠЎпјҢдҫӢеҰӮйҳҝйҮҢдә‘1MB/SйғҪжҳҜе…Қиҙ№зҡ„гҖӮ
з«һе“ҒеҲҶжһҗ вҖ”вҖ” Logstash, Kafka##
###Splunk vs Logstash###
LogstashжҳҜдёӘејҖжәҗзҡ„ж—Ҙеҝ—жҗңзҙўе·Ҙе…·пјҢд№ҹжҳҜдёҖдҪ“еҢ–зҡ„ејҖз®ұеҚіз”Ёзҡ„дә§е“ҒгҖӮеҹәжң¬дёҠпјҢиғҪе®һзҺ°Splunkе…ӯжҲҗзҡ„еҠҹеҠӣгҖӮWebжІЎжңүйӮЈд№ҲејәпјҢд№ҹжІЎжңүSPLиҝҷж ·з®ҖеҚ•зҡ„иҜӯиЁҖпјҢElasticSearchйңҖиҰҒйҖҡиҝҮJsonжқҘжҹҘиҜўпјҢKibanaзҡ„жҗңзҙўиҜӯеҸҘиғҪеҠӣжңүйҷҗгҖӮзӣ®еүҚеҸҜд»ҘиҜҙLogstashиҝҷдёӘйЎ№зӣ®иҝҳеңЁжҲҗзҶҹжңҹгҖӮйңҖиҰҒеҗҺз»ӯеҫҲеӨҡзҡ„е·ҘдҪңжүҚиғҪеҒҡеҘҪгҖӮ
###Splunk vs Kafka ###
иҝҷд№ҲжҜ”иҫғе…¶е®һдёҚжҳҜеҫҲе…¬е№ігҖӮ
KafkaеҸӘи§ЈеҶідәҶж—Ҙеҝ—зҡ„з»ҹдёҖжҗңйӣҶгҖҒдј иҫ“гҖҒеәҸеҲ—еҢ–еӯҳеӮЁй—®йўҳгҖӮSplunkеҒҡзҡ„жӣҙеӨҡдәӣпјҢиҝҳеҒҡдәҶж•°жҚ®зҙўеј•зҡ„ж·ұеҠ е·ҘгҖӮ
еҗҢж—¶пјҢKafkaйңҖиҰҒеңЁжәҗеӨҙдҪҝз”ЁschemaжқҘе®ҡд№үж•°жҚ®ж јејҸпјҢдёҘж јпјҢжңүеҲ©дәҺеҗҺжңҹзҡ„ж¶Ҳиҙ№зЁӢеәҸдҪҝз”ЁгҖӮ
SplunkеҚҙеҜ№жәҗеӨҙж•°жҚ®иҰҒжұӮжІЎжңүйӮЈд№Ҳй«ҳпјҢеҜ№зҺ°жңүзі»з»ҹж”№еҠЁе°ҸпјҢеӣ дёәжҳҜдёӘдјҒдёҡиҪҜ件пјҢйңҖиҰҒиҝҪжұӮе…је®№жҖ§гҖӮ
д»Һй«ҳеҸҜз”Ёж–№йқўжқҘзңӢпјҢSplunkзӣ®еүҚиҝҳжІЎжңүдёҖеӨ©жҗңйӣҶеҮ дёӘTзҡ„ж•°жҚ®зҡ„жЎҲдҫӢпјҢKafkaеңЁиҝҷж–№йқўзҡ„иғҪеҠӣз»қеҜ№жІЎжңүй—®йўҳгҖӮ
KafkaжҳҜдёӘжҜ”иҫғеҘҪзҡ„иҪҰиә«жЎҶжһ¶пјҢдҪҶиҝҳзјәдёҖдёӘејәеӨ§зҡ„еҸ‘еҠЁжңәе’ҢдёҚе°‘еҶ…йҘ°пјӣSplunkжҳҜдёҖиҫҶеҠҹиғҪе®Ңе–„зҡ„иҪҰеӯҗпјҢе°ұжҳҜд»·ж јеҫҲиҙөпјҢиҖҢдё”жІЎжңүеңЁ150з Ғд»ҘдёҠејҖиҝҮзҡ„жЎҲдҫӢгҖӮ
жүҖд»ҘпјҢеҜ№дәҺKafkaпјҢеҸҜиғҪзҡ„жҖ»дҪ“и§ЈеҶіж–№жЎҲжңүпјҡ
Kafka + YARN + Hadoop = Samza(Linkin)
Kafka + Strom + MySQL
Kafka + ElasticSearch + Kibana
д»ҘдёҠе°ұжҳҜе…ідәҺвҖңSplunkжҳҜд»Җд№ҲвҖқиҝҷзҜҮж–Үз« зҡ„еҶ…е®№пјҢзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢиӢҘжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҡ„зҹҘиҜҶеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





