本篇内容介绍了“大数据体系概念有哪些”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
这个不同于分布式数据库,大多数的NoSQL系统采用了更加简单的数据模型,不管是MongoDB,Hbase,Redis,Memcache,还是其他的Nosql,都采取了【简单数据模型】,怎么简单? 通常而言,每一个记录都拥有唯一的Key,查询的结果也就是Value,而且系统对于查询的支持也紧紧只到了记录级别的原子级,很少有Nosql支持外键和跨记录,跨segment的关系维护,这种一次操作获取单个记录的约定极大的增强了系统的可扩展性,消除了分布式事务的开销
通常而言,Nosql需要维护两种数据: 元数据和应用数据,元数据是用于系统管理的,用来描述整个集群中间的状态的信息,如整个Nsql 机群的节点数和数据映射。而应用数据,就是通常你的业务系统,实际需求使用的数据,看场合不同而不同。
弱一致性? 为什么一致性还需要分强弱?究竟一致性分几种,Nosql 是如何实现的?
有效的降低成本,扩大的集群整体能力。
构图如下:
用简单的话语来解析一致性,就是系统在执行某项的操作以后还处于一致
的状态,比如:你更新以后,所有的用户都该读取到最新的值,这样的系统被认为具有强一致性。
可用性:这个更简单了,什么是可用?我找你NoSQL取一个值,你不能三分钟转圈圈还不给我吧
,这个就叫不可用,可不可用有两个最基本的判定:
在“一定时间”,“返回一定的结果”。
在“一定的时间之内”这个是相当的有必要好的,要不然任何支付啊,交易啊,数据信息传递都是超时的存在。
“返回结果”,这个更加重要了,你不可能告诉前端,嘿,底层肯定会在一定时间内有动作的,但是这个动作
不给你数据,给你“excetpion...”
分区这个功能你可以完全的理解为一张大饼,被划分为多块,对数据的读取仿佛就是在吃这张大饼,本质上是若干个独立的分区,而分区之间互相连通但是没有依赖,可以动态的加入和离开。
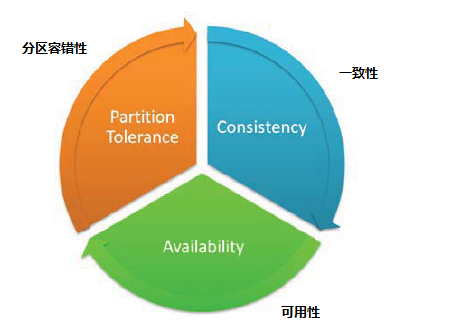
CAP这三大性质,是在分布式系统环境之中设计和部署时所需要考虑的单个重要的系统需求,通常而言,不能够同时的满足这三大性,举一个小小的例子:来说明,看图说话:
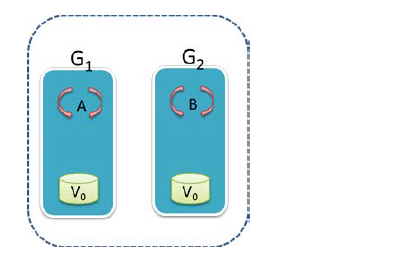
A,B就是两Client,真个系统目前只有2台机器,V0为数据,2台机器上都有V0,是一个副本存在。
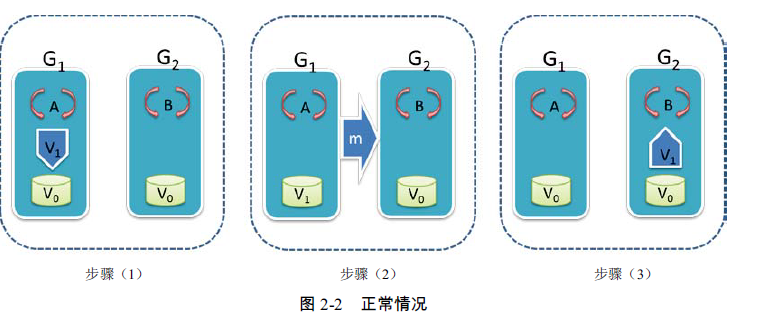
1:首先 A 更新了一下VO的值,比如更新为字符串:newString
2:既然V0跟新了,那么作为一个副本的存在,在G2上的V0也需要更新
3:正式更新:G1开始不断的发射消息到G2
4:G2中的值被改变,并且B开始读取到最新的一个值:newString. 图中表示为 v1:代表 value1
ok,一切顺利。如下图所示
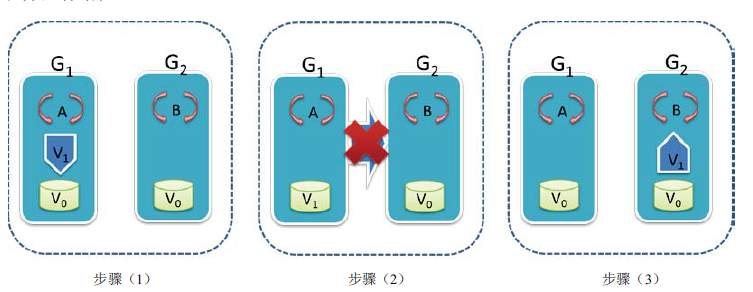
而现实总是太残酷,你在更新的过程之中,过程3被中断了。也就是数据没有正确的被发射过去 ,此时数据就处于了一个不一致的状态。B读取到的数据就不是一个最新版的数据。
CAP的模型告诉了我们一个事实,要想保证容错性质,那么就很有可能不能保证一致性。有的人会说,解决这个问题很简单,我们对于这个传递更新的操作做一个 同步操作不就好了?
事实上来说,如果不加同步,G1-》G2的更新是不可知的。完全可能处于延迟,中断的状态。能保证“A“,”P”
当是是不能保证一直性“C">
大的情况之下,当节点的数量成百上千的时候,这个开销被放大了,以至于服务是可用,但是没有使用的价值了。也就是说
“A“可用性不能保证了。
三个不能同时满足,那么我们就看看是否能够保证简单的满足2个:

如果你想避免容错性问题,最简单的方式,当然是将所有的数据都放置在一台机器之上,虽然无法保证
100%系统都可用,但是至少不会出现由分区带来的效果。
放弃可用性是指在遇到了容错性的问题的过程之中,好不犹豫的以保证容错,一致性为先,即便服务不 能提供,即便服务肯定会超时。
放弃一致性在这里并不是指不再保证我们的多个副本之间的一致,而是指只是暂时允许不一致的状态,在 供服务使用之前来保证最终的一致性就可以了。
“大数据体系概念有哪些”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/infiniteSpace/blog/333459



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



