hadoop2.4жәҗз ҒеҲҶжһҗ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңhadoop2.4жәҗз ҒеҲҶжһҗвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
ZKFailoverControllerжҳҜж•ҙдёӘHAзҡ„еҚҸи°ғиҖ…гҖӮдёӢйқўжҲ‘们е°ҶеҲҶжһҗеҮ дёӘе®һйҷ…зҡ„й—®йўҳгҖӮ
1.жҖҺд№ҲеҚҸи°ғйҖүдёҫзҡ„пјҹжҖҺд№ҲйҖүдёҫеҮәжқҘactiveзҡ„пјҹ
2.activeе®•жңәеҗҺпјҢеҒҡдәҶд»Җд№ҲдәӢжғ…пјҢеҰӮдҪ•еҲҮжҚўзҡ„пјҹ
дёӢйқўпјҢжҲ‘们жқҘеҲҶжһҗ第дёҖдёӘй—®йўҳ
жҖҺд№ҲеҚҸи°ғйҖүдёҫзҡ„пјҹжҖҺд№ҲйҖүдёҫеҮәжқҘactiveзҡ„пјҹ
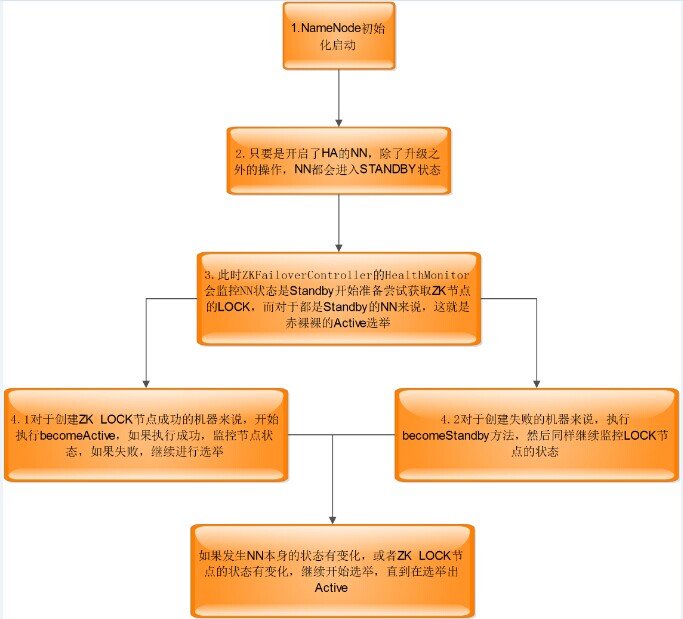
жӯҘйӘӨ1пјҡеҸӮзңӢNameNodeжәҗз ҒпјҢеҸҜд»ҘзңӢеҮәпјҢеҜ№дәҺдҪҝз”ЁHAзҡ„NNжқҘиҜҙпјҢиҝӣе…ҘStandbyжҳҜеҝ…йЎ»зҡ„гҖӮ
еҚҮзә§йҷӨеӨ–
protected HAState createHAState(StartupOption startOpt) {
if (!haEnabled || startOpt == StartupOption.UPGRADE) {
return ACTIVE_STATE;
} else {
return STANDBY_STATE; //standbyзҠ¶жҖҒ
}
}
жӯҘйӘӨ2пјҡжӯӨж—¶зҡ„HealthMonitorзӣ‘жҺ§NNпјҢеҸ‘зҺ°жҳҜHEALTHзҡ„зҠ¶жҖҒпјҢдјҡжү§иЎҢпјҡ
if (healthy) {
//и®ҫзҪ®зҠ¶жҖҒпјҢз”ЁдәҺйҖҡзҹҘеӣһи°ғеҮҪж•°
enterState(State.SERVICE_HEALTHY);
}
enterStateдјҡйҖҡзҹҘеӣһи°ғеҮҪж•°пјҢиҝӣиЎҢеӨ„зҗҶгҖӮеҜ№дәҺHEALTHзҠ¶жҖҒзҡ„ејҖе§Ӣжү§иЎҢйҖүдёҫж–№жі•гҖӮ
elector.joinElection(targetToData(localTarget));
йҖҡиҝҮеҲӣе»әйӣ¶ж—¶иҠӮзӮ№пјҢжқҘжҠўеҚ иҠӮзӮ№пјҢиҺ·еҸ–Active
createLockNodeAsync();
еҜ№дәҺеҲӣе»әиҠӮзӮ№пјҢдјҡи§ҰеҸ‘ZKзҡ„EVENTж—¶й—ҙгҖӮ
еҜ№дәҺдәӢ件зҡ„еӨ„зҗҶпјҢи§Ғжәҗз ҒйғЁеҲҶпјҡ
public synchronized void processResult(int rc, String path, Object ctx,
String name) {
if (isStaleClient(ctx)) return;
LOG.debug("CreateNode result: " + rc + " for path: " + path
+ " connectionState: " + zkConnectionState +
" for " + this);
Code code = Code.get(rc);//дёәдәҶж–№дҫҝдҪҝз”ЁпјҢиҝҷйҮҢиҮӘе®ҡд№үдәҶдёҖз»„зҠ¶жҖҒ
if (isSuccess(code)) {//жҲҗеҠҹиҝ”еӣһ,жҲҗеҠҹеҲӣе»әzklocakpathиҠӮзӮ№
// we successfully created the znode. we are the leader. start monitoring
if (becomeActive()) {//иҰҒе°Ҷжң¬иҠӮзӮ№дёҠзҡ„NNеҸҳжҲҗactive
monitorActiveStatus();//继з»ӯзӣ‘жҺ§иҠӮзӮ№зҠ¶жҖҒ
} else {
reJoinElectionAfterFailureToBecomeActive();//еӨұиҙҘпјҢ继з»ӯйҖүдёҫе°қиҜ•
}
return;
}
if (isNodeExists(code)) {//иҠӮзӮ№еӯҳеңЁпјҢиҜҙжҳҺе·Із»ҸжңүactiveпјҢwaitеҚіеҸҜ
if (createRetryCount == 0) {
// znode exists and we did not retry the operation. so a different
// instance has created it. become standby and monitor lock.
becomeStandby();
}
// if we had retried then the znode could have been created by our first
// attempt to the server (that we lost) and this node exists response is
// for the second attempt. verify this case via ephemeral node owner. this
// will happen on the callback for monitoring the lock.
monitorActiveStatus();//дёҚиҝҮеҠӘеҠӣжҲҗдёәactiveзҡ„еҠЁдҪңдёҚиғҪеҒң
return;
}
String errorMessage = "Received create error from Zookeeper. code:"
+ code.toString() + " for path " + path;
LOG.debug(errorMessage);
if (shouldRetry(code)) {
if (createRetryCount < maxRetryNum) {
LOG.debug("Retrying createNode createRetryCount: " + createRetryCount);
++createRetryCount;
createLockNodeAsync();
return;
}
errorMessage = errorMessage
+ ". Not retrying further znode create connection errors.";
} else if (isSessionExpired(code)) {
// This isn't fatal - the client Watcher will re-join the election
LOG.warn("Lock acquisition failed because session was lost");
return;
}
fatalError(errorMessage);
}
еҜ№дәҺиҺ·еҸ–Activeзҡ„жңәеҷЁпјҢи°ғз”ЁbecomeActive()ж–№жі•
private synchronized void becomeActive() throws ServiceFailedException {
LOG.info("Trying to make " + localTarget + " active...");
try {
HAServiceProtocolHelper.transitionToActive(localTarget.getProxy(
conf, FailoverController.getRpcTimeoutToNewActive(conf)),
createReqInfo());
String msg = "Successfully transitioned " + localTarget +
" to active state";
LOG.info(msg);
serviceState = HAServiceState.ACTIVE;
recordActiveAttempt(new ActiveAttemptRecord(true, msg));
} catch (Throwable t) {
String msg = "Couldn't make " + localTarget + " active";
LOG.fatal(msg, t);
recordActiveAttempt(new ActiveAttemptRecord(false, msg + "\n" +
StringUtils.stringifyException(t)));
if (t instanceof ServiceFailedException) {
throw (ServiceFailedException)t;
} else {
throw new ServiceFailedException("Couldn't transition to active",
t);
}
йҖҡиҝҮеҜ№RPCиҝӣиҝҮдёҖзі»еҲ—зҡ„и°ғз”ЁпјҢжңҖз»Ҳжү§иЎҢNameNodeзҡ„
synchronized void transitionToActive()
throws ServiceFailedException, AccessControlException {
namesystem.checkSuperuserPrivilege();
if (!haEnabled) {
throw new ServiceFailedException("HA for namenode is not enabled");
}
state.setState(haContext, ACTIVE_STATE);
}
OVER
2.activeе®•жңәеҗҺпјҢеҒҡдәҶд»Җд№ҲдәӢжғ…пјҢеҰӮдҪ•еҲҮжҚўзҡ„пјҹ
activeе®•жңәеҗҺжҲ–иҖ…ејӮеёёдјҡеҜјиҮҙZKиҠӮзӮ№зҡ„ж¶ҲеӨұжҲ–зӣ‘жҺ§зҠ¶жҖҒзҡ„UNHEALTHпјҢиҝҷдәӣйғҪдјҡеҜјиҮҙж–°дёҖиҪ®зҡ„йҖүдёҫпјҢеҺҹзҗҶеҗҢдёҠгҖӮ
вҖңhadoop2.4жәҗз ҒеҲҶжһҗвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ





