本篇内容介绍了“如何编写MapReudce程序”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
Combiner实质上就是不同上下文的Reducer的功能是差不多的.所以说它本质上就是一个Reducer.每一个map可能会产生大量的输出,combiner的作用就是在map端对输出先做一次合并,以减少传输到reducer的数据量。combiner最基本是实现本地key的归并,combiner具有类似本地的reduce功能。如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下(会消耗较多的网络IO)。使用combiner,先完成的map会在本地聚合,提升速度.
|
案例3:在wordcount的基础上,实现Combiner编程
package cn.itcast.yun10;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountCombiner extends
Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values,
Context context) throws IOException, InterruptedException {
// accept
// the same as reduce
String word = key.toString();
long count = 0L;
for (LongWritable v : values) {
count += v.get();
}
context.write(new Text(word), new LongWritable(count));
}
} 2.指定Combiner |
使用Combiner编程的两点注意:
a.不要以为在写MapReduce程序时设置了Combiner就认为Combiner一定会起作用,实际情况是这样的吗?答案是否定的。hadoop文档中也有说明Combiner可能被执行也可能不被执行。那么在什么情况下不执行呢?如果当前集群在很繁忙的情况下job就是设置了也不会执行Combiner.
b.Combiner的输出是Reducer的输入,所以添加Combiner绝不能改变最终的计算结果。所以Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。但是并不适用于求平均值类似的操作.
至于Combiner的执行时机,待分析完Shuffle之后再来说...?????
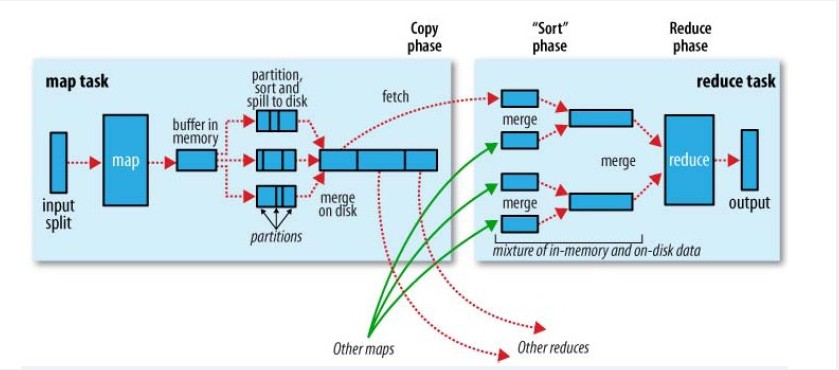
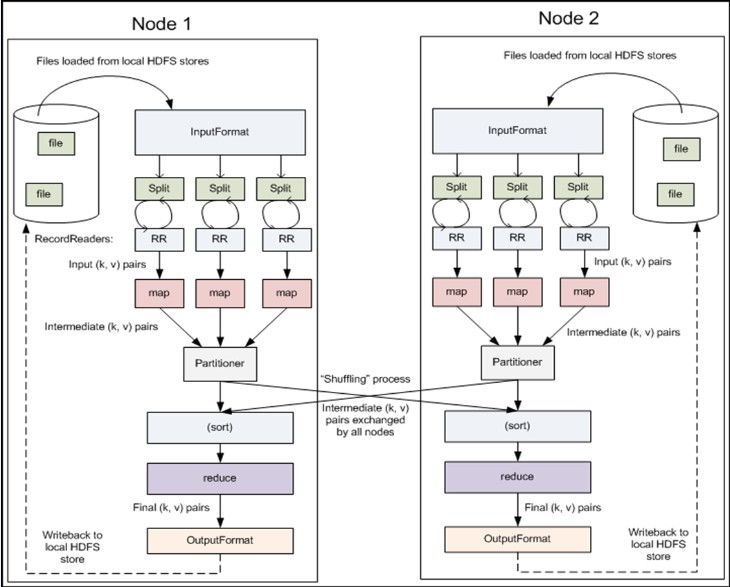
MapReduce确保每个Reducer的输入都按键排序.系统执行排序的过程在map输出之后,而在reducer输入之前完成。称为Shuffle---洗牌.观察shuffle如何工作的,有助于我们理解工作机制例如(优化MapReduce程序).shuffle属于不断被优化和改进的代码库的一部分.它会随着版本的不同而随时改变.在Hadoop里有这么一句话,说shuffle是MapReduce的心脏,是奇迹发生的地方.
Map端:map函数之后.
map函数开始产生输出时,并不是简单地将它写到磁盘中。这个过程是很复杂的。它会利用缓冲区的方式写到内存。而且处于效率会考虑进行预先排序.
每个map任务都有一个环形内存缓冲区,用于存储任务的输出。默认的情况下,缓冲区的大小为100MB,可以通过io.sort.mb的属性来指定。一旦缓冲区达到阀值(io.sort.spill.percent,默认情况下是80%),就有一个后台线程开始把内容写到spill磁盘中。在写磁盘过程中,map输出继续被写到缓冲区,但如果在此期间缓冲区被填满,map输出就会被阻塞直到写磁盘过程完成。而写磁盘将按轮询方式写到 mapred.local.dir 属性指定的作业特定子目录中的目录中.在这个目录下新建一个溢出写文件。
在写磁盘之前,要partition,sort(数据先分区,然后再排序)。如果有combiner,combiner排序后数据。combiner待榷商。
在写磁盘的时候会采用压缩格式。Hadoop中的压缩库由 mapred.map.output.compression.codec指定.以后会做详细的说明.
等最后记录写完,合并全部溢出写文件为一个分区且排序的文件.配置属性 io.sort.factor控制着一次最多能合并多少流,默认大小为10.这就是merge合并了.
实际上,Conbiner函数的执行时机可能会在map的merge操作完成之前,也可能在merge之后执行,这个时机由配置参数min.num.spill.for.combine(该值默认为3),也就是说在map端产生的spill溢出文件最少有min.num.spill.for.combine的时候,Conbiner函数会在(merge操作合并最终的本机结果文件之前)执行,否则在merge之后执行。通过这种方式,就可以在spill文件很多并且需要做conbiner的时候,减少写入本地磁盘的数据量,同样也减少了对磁盘的读写频率,可以起到优化作业的目的。--------也就是说spill出的而文件个数达到三,就可以执行Combiner函数.然后再meger.
reducer会通过HTTP方式得到上述执行的结果(输出文件的分区) (map中),用于文件分区的工作线程的数量由任务的tracker.http.threads属性控制.默认值是40.
Reducer端:reduce函数之前
在运行reduce任务之前,需要集群中多个map任务的输出作为分区材料。但是每个map任务的完成时间很有可能是不同的。所以只要有个map任务完成,reduce就会复制COPY它的输出。这就是复制阶段。在reduce端会开启几个复制的线程去COPY。该数字有mapred.reduce.parallel.copies属性决定。默认值为5.
复制到reduce的话,是有可能到内存,也有可能到磁盘上.这是内存缓冲区大小有mapred.job.shuffle.input.buffer.percenet属性控制。占堆空间的百分比。一旦缓冲区达到阀值的大小,则会合并后溢出到磁盘。随着磁盘文件复制文件越来越多。就会合并更大的文件。
然后进入排序阶段。准确来说是合并阶段,因为排序在map端已经完成。合并时循环进行的。这个合并也是比较复杂的。
最后将得到的数据输入reduce函数.最后合并可能来自内存也有可能来自磁盘.最后来几个图吧。
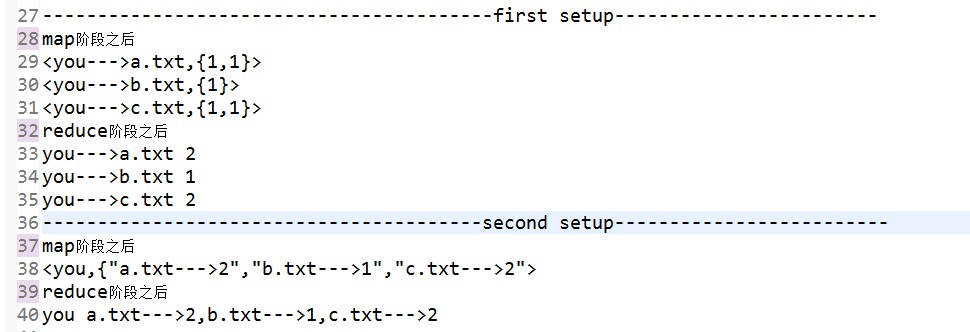
案例4:存在两个文件a.txt,b.txt.两者里面的内容如下:
a.txt文件 -------------------------------- hello world hello tom how are you how do you do ----------------------------------- b.txt文件 hello is fool i say hi how do you think --------------------------------------- c.txt文件 you are all handsome i am the superman how do you think --------------------------------------- 在上述文件中建立倒排索引,就像如下格式: hello --> a.txt,2 b.txt,1 how --->a.txt,2 b.txt,1 c.txt,1 思路如下:通过两次MapReduce执行出想要的结果.
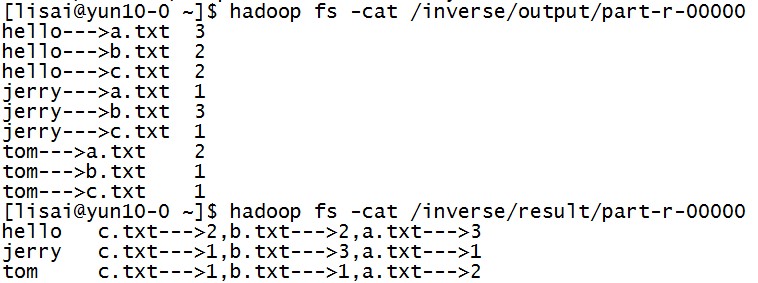
代码省略..... 实验结果:
|
单词计数,数据去重,排序,Top K,选择,投影,分组,多表连接,单表关联.都可以通过MapReduce完成。熟悉这些的话,对于后面的Hive学习有很大的用处.
在这里就拿多表连接来做一个案例.
案例5:存在两个表A,B.两表之间存在关系。假设两个表都是以文本文件的形式存储,SQL语句:select a.id,b.name from a,b where a.id = b.id,得到结果输出到文件.
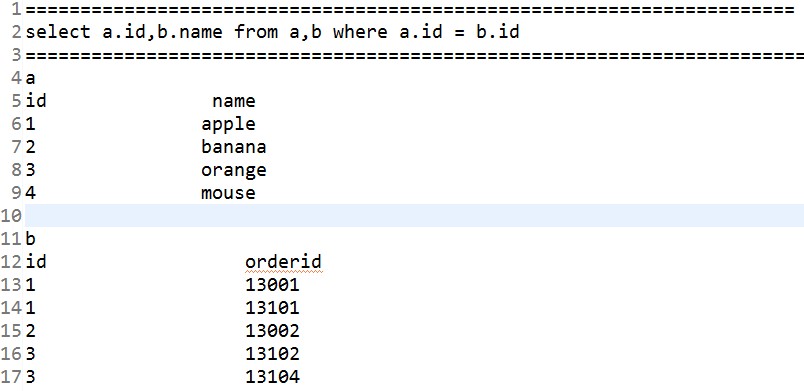
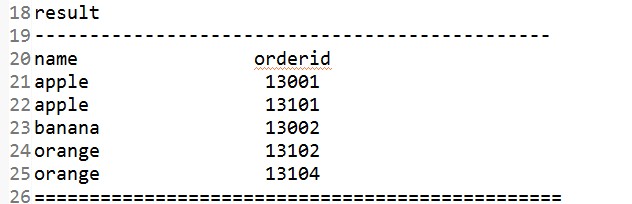
思路如下:
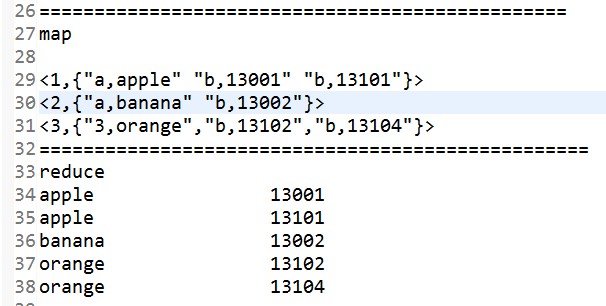
代码省略.
split的作用就是决定mapper的数量,hadoop将mapreduce的输入数据划分成等长的小数据块。称为输入分片(input split).在前面的mapreduce输入类InputFormat中有讲到过.这些小数据块称为分片。一个分片对应着一个map任务.关于分片的大小,经验来说,趋向于一个HDFS的默认块大小.
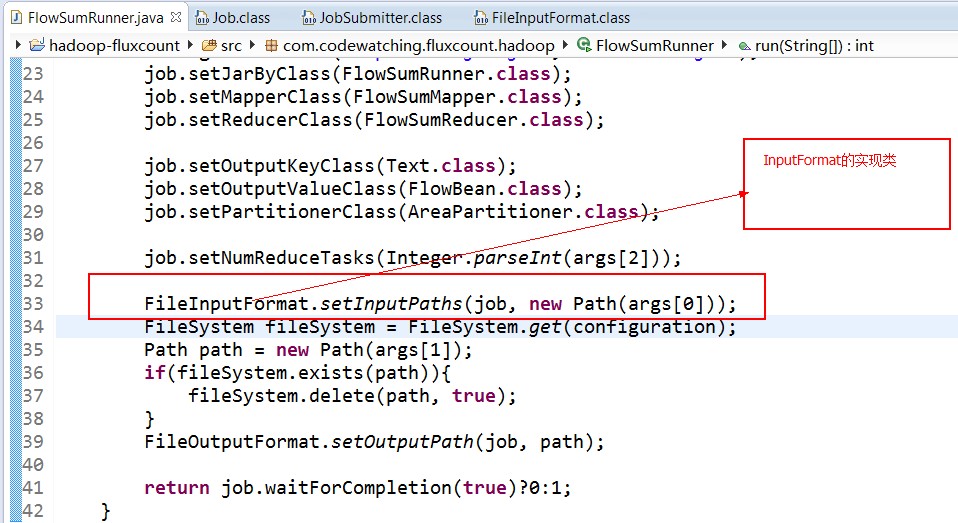
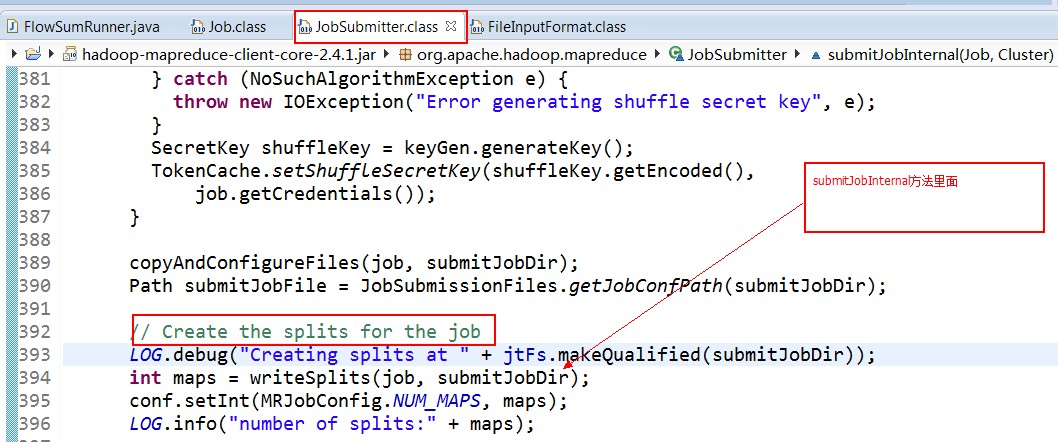
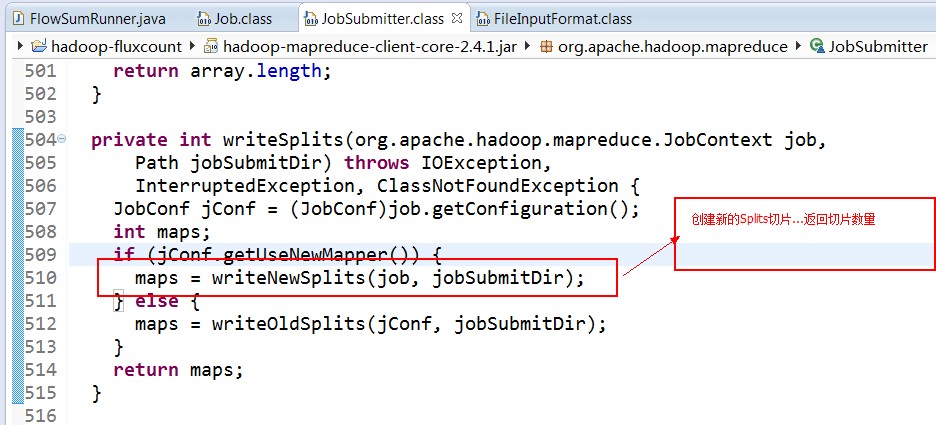
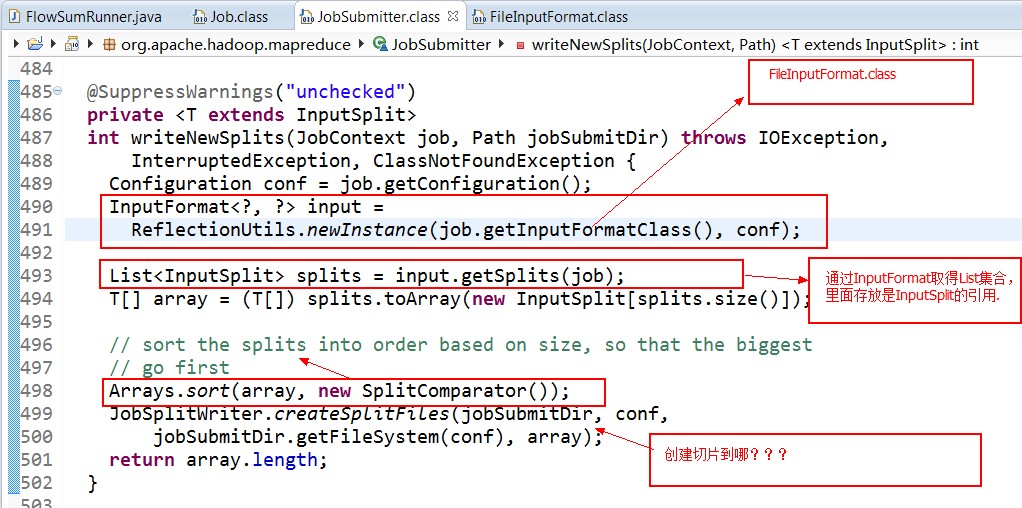
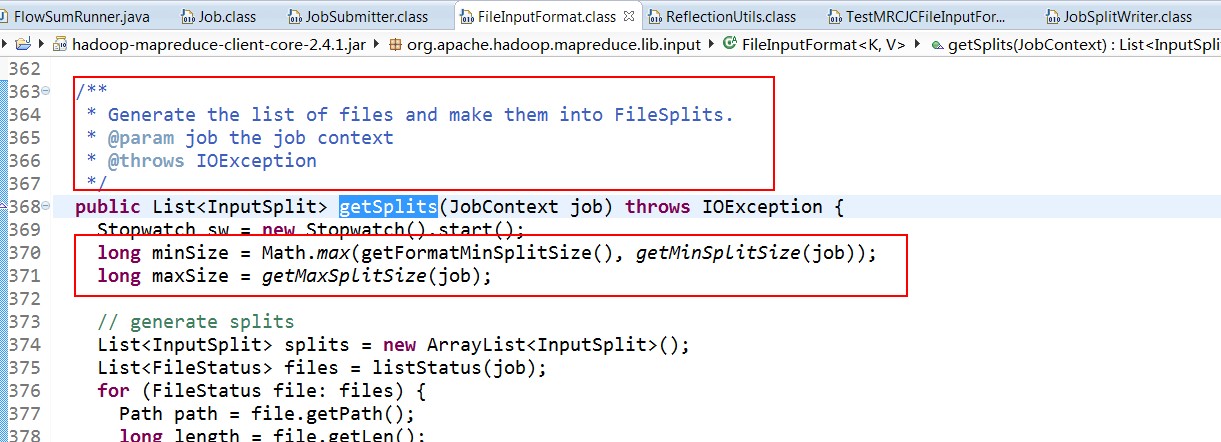
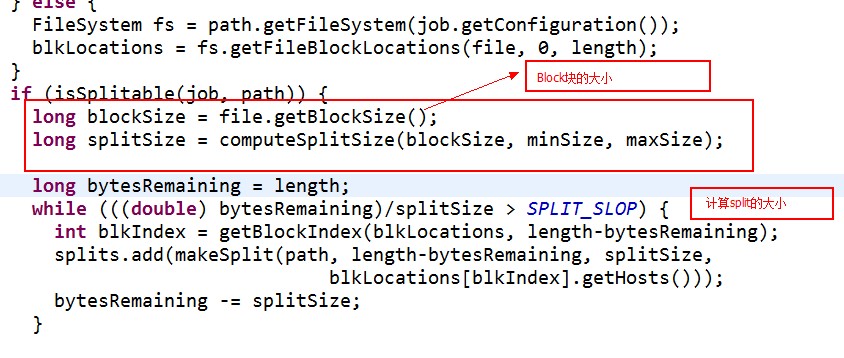
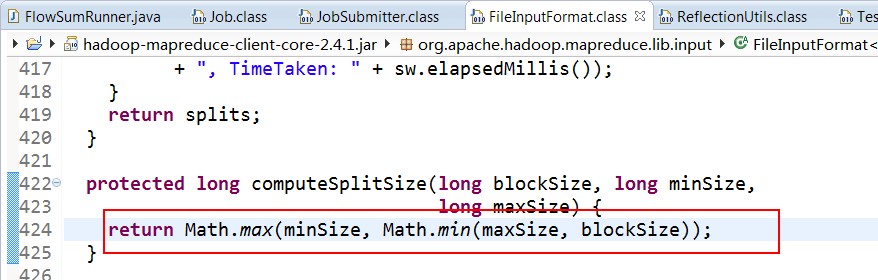
这样的话,就可以获取分片的大小啦......
“如何编写MapReudce程序”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。