本篇文章给大家分享的是有关Spark API编程中如何在Spark 1.2版本实现对union、groupByKe的分析,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
下面看下union的使用:
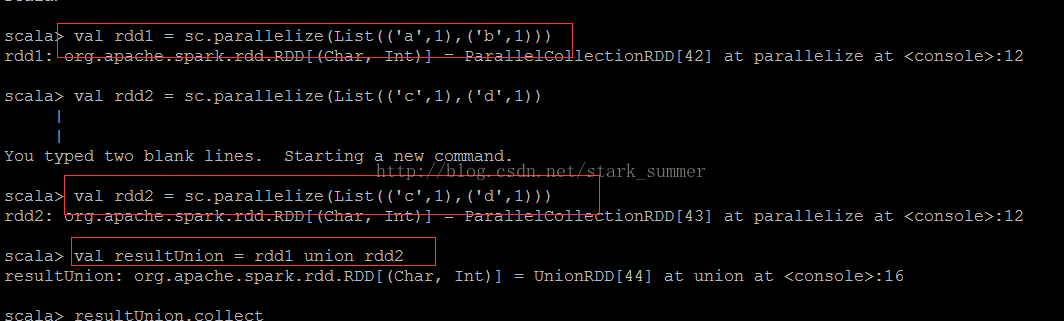
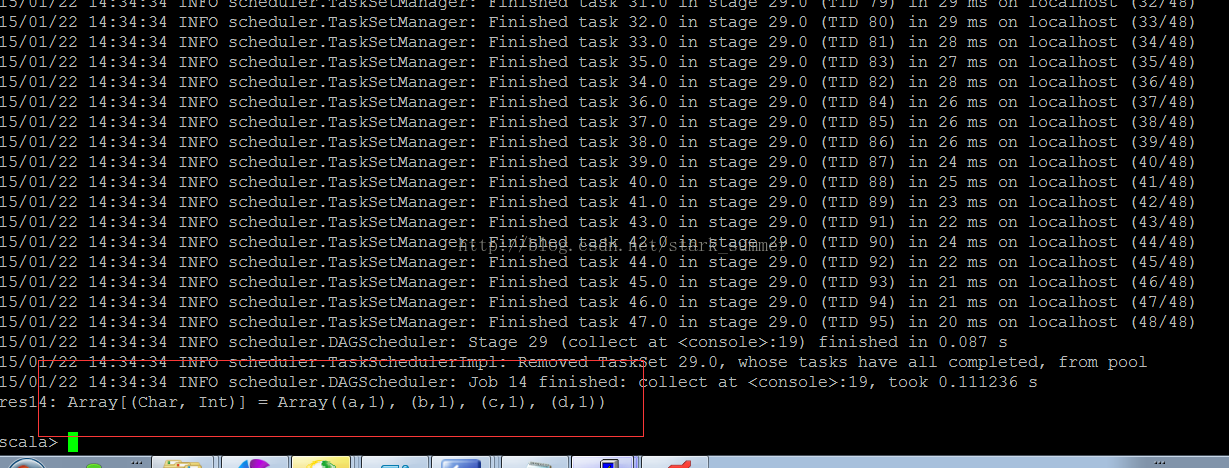
使用collect操作查看一下执行结果:
再看下groupByKey的使用:

join操作就是一个笛卡尔积操作的过程,如下示例:

使用collect查看执行结果:

可以看出join操作完全就是一个笛卡尔积的操作;
reduce本身在RDD操作中属于一个action类型的操作,会导致job的提交和执行:

下面我们看下lookup的使用:

以上就是Spark API编程中如何在Spark 1.2版本实现对union、groupByKe的分析,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





