这篇文章主要讲解了“Hadoop中怎么实现MapReduce的数据输入”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Hadoop中怎么实现MapReduce的数据输入”吧!
接下来我们按照MapReduce过程中数据流动的顺序,来分解org.apache.hadoop.mapreduce.lib.*的相关内容,并介绍对应的基类的功能。首先是input部分,它实现了MapReduce的数据输入部分。类图如下: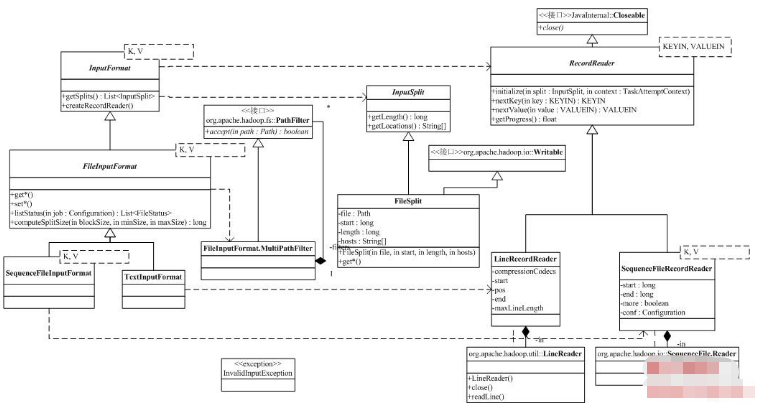
类图的右上角是InputFormat,它描述了一个MapReduceJob的输入,通过InputFormat,Hadoop可以:
l 检查MapReduce输入数据的正确性;
l 将输入数据切分为逻辑块InputSplit,这些块会分配给Mapper;
l 提供一个RecordReader实现,Mapper用该实现从InputSplit中读取输入的<K,V>对。
在org.apache.hadoop.mapreduce.lib.input中,Hadoop为所有基于文件的InputFormat提供了一个虚基类FileInputFormat。下面几个参数可以用于配置FileInputFormat:
l mapred.input.pathFilter.class:输入文件过滤器,通过过滤器的文件才会加入InputFormat;
l mapred.min.split.size:最小的划分大小;
l mapred.max.split.size:最大的划分大小;
l mapred.input.dir:输入路径,用逗号做分割。
类中比较重要的方法有:
protectedList<FileStatus> listStatus(Configuration job)
递归获取输入数据目录中的所有文件(包括文件信息),输入的job是系统运行的配置Configuration,包含了上面我们提到的参数。
publicList<InputSplit> getSplits(JobContext context)
将输入划分为InputSplit,包含两个循环,第一个循环处理所有的文件,对于每一个文件,根据输入的划分最大/最小值,循环得到文件上的划分。注意,划分不会跨越文件。
FileInputFormat没有实现InputFormat的createRecordReader方法。
FileInputFormat有两个子类,SequenceFileInputFormat是Hadoop定义的一种二进制形式存放的键/值文件(参考http://hadoop.apache.org/core/do ... o/SequenceFile.html),它有自己定义的文件布局。由于它有特殊的扩展名,所以SequenceFileInputFormat重载了listStatus,同时,它实现了createRecordReader,返回一个SequenceFileRecordReader对象。TextInputFormat处理的是文本文件,createRecordReader返回的是LineRecordReader的实例。这两个类都没有重载FileInputFormat的getSplits方法,那么,在他们对于的RecordReader中,必须考虑FileInputFormat对输入的划分方式。
FileInputFormat的getSplits,返回的是FileSplit。这是一个很简单的类,包含的属性(文件名,起始偏移量,划分的长度和可能的目标机器)已经足以说明这个类的功能。
RecordReader用于在划分中读取<Key,Value>对。RecordReader有五个虚方法,分别是:
l initialize:初始化,输入参数包括该Reader工作的数据划分InputSplit和Job的上下文context;
l nextKey:得到输入的下一个Key,如果数据划分已经没有新的记录,返回空;
l nextValue:得到Key对应的Value,必须在调用nextKey后调用;
l getProgress:得到现在的进度;
l close,来自java.io的Closeable接口,用于清理RecordReader。
我们以LineRecordReader为例,来分析RecordReader的构成。前面我们已经分析过FileInputFormat对文件的划分了,划分完的Split包括了文件名,起始偏移量,划分的长度。由于文件是文本文件,LineRecordReader的初始化方法initialize会创建一个基于行的读取对象LineReader(定义在org.apache.hadoop.util中,我们就不分析啦),然后跳过输入的最开始的部分(只在Split的起始偏移量不为0的情况下进行,这时最开始的部分可能是上一个Split的最后一行的一部分)。nextKey的处理很简单,它使用当前的偏移量作为Key,nextValue当然就是偏移量开始的那一行了(如果行很长,可能出现截断)。进度getProgress和close都很简单。
感谢各位的阅读,以上就是“Hadoop中怎么实现MapReduce的数据输入”的内容了,经过本文的学习后,相信大家对Hadoop中怎么实现MapReduce的数据输入这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





