这篇文章给大家介绍 怎么进行Hadoop源代码分析,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
大家都熟悉文件系统,在对HDFS进行分析前,我们并没有花很多的时间去介绍HDFS的背景,毕竟大家对文件系统的还是有一定的理解的,而且也有很好的文档。在分析Hadoop的MapReduce部分前,我们还是先了解系统是如何工作的,然后再进入我们的分析部分。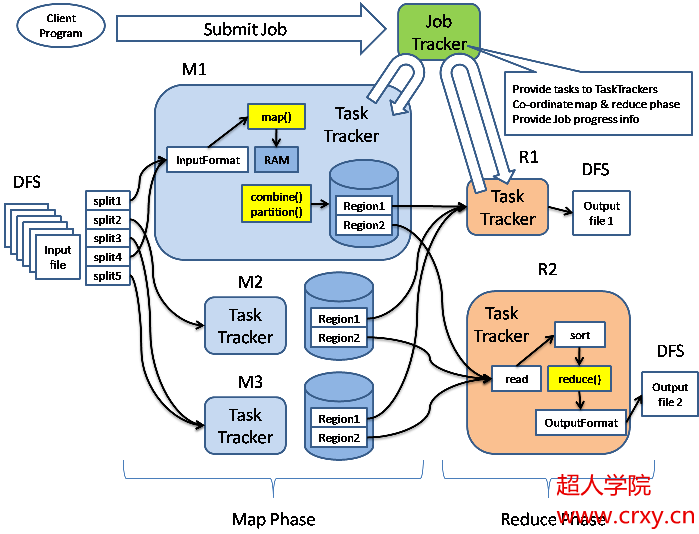
以Hadoop带的wordcount为例子(下面是启动行):
hadoop jar hadoop-0.19.0-examples.jar wordcount /usr/input/usr/output
用户提交一个任务以后,该任务由JobTracker协调,先执行Map阶段(图中M1,M2和M3),然后执行Reduce阶段(图中R1和R2)。Map阶段和Reduce阶段动作都受TaskTracker监控,并运行在独立于TaskTracker的Java虚拟机中。
我们的输入和输出都是HDFS上的目录(如上图所示)。输入由InputFormat接口描述,它的实现如ASCII文件,JDBC数据库等,分别处理对于的数据源,并提供了数据的一些特征。通过InputFormat实现,可以获取InputSplit接口的实现,这个实现用于对数据进行划分(图中的splite1到splite5,就是划分以后的结果),同时从InputFormat也可以获取RecordReader接口的实现,并从输入中生成<k,v>对。有了<k,v>,就可以开始做map操作了。
map操作通过context.collect(最终通过OutputCollector. collect)将结果写到context中。当Mapper的输出被收集后,它们会被Partitioner类以指定的方式区分地写出到输出文件里。我们可以为Mapper提供Combiner,在Mapper输出它的<k,v>时,键值对不会被马上写到输出里,他们会被收集在list里(一个key值一个list),当写入一定数量的键值对时,这部分缓冲会被Combiner中进行合并,然后再输出到Partitioner中(图中M1的黄颜色部分对应着Combiner和Partitioner)。
Map的动作做完以后,进入Reduce阶段。这个阶段分3个步骤:混洗(Shuffle),排序(sort)和reduce。
混洗阶段,Hadoop的MapReduce框架会根据Map结果中的key,将相关的结果传输到某一个Reducer上(多个Mapper产生的同一个key的中间结果分布在不同的机器上,这一步结束后,他们传输都到了处理这个key的Reducer的机器上)。这个步骤中的文件传输使用了HTTP协议。
排序和混洗是一块进行的,这个阶段将来自不同Mapper具有相同key值的<key,value>对合并到一起。
Reduce阶段,上面通过Shuffle和sort后得到的<key, (list of values)>会送到Reducer. reduce方法中处理,输出的结果通过OutputFormat,输出到DFS中。
关于 怎么进行Hadoop源代码分析就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





