今天就跟大家聊聊有关如何在window上使用VirtualBox搭建Ubuntu15.04全分布Hadoop2.7.1集群,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
先给大家看看配置好的集群截图:
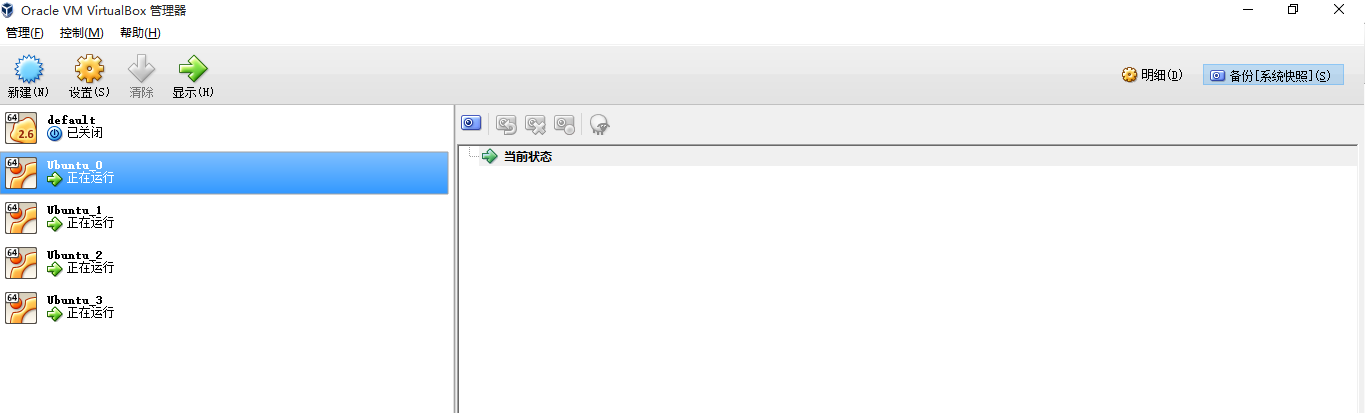
注意(default是docker的,大家不用管,下面四台才是,其中Ubuntu_0是master,Ubuntu_1,2,3是slave节点)
一.新建虚拟机,配置基础java环境,配置网络访问
下载Ubuntu15.04,打开VirtualBox,新建Ubuntu虚拟机,用户名linux1,不截图了,内存选1G就够了
接下来,下载并安装JDK:
下载:去官网下载对应版本的JDK,我这里是jdk-8u60-linux-x64.tar.gz
新建安装目录:
sudo mkdir /usr/local/java解压JDK:
sudo tar xvf ~/Downloads/jdk-8u60-linux-x64.tar.gz -C /usr/local/java
设置全局环境变量:
sudo gedit ~/.bashrc
文件末尾添加:
export JAVA_HOME=/usr/local/java/jdk1.8.0_60
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH验证:新开终端,输入java验证(当前终端内不生效)
接下来,配置网络(为啥要配置:因为你搭的是集群,用的是集群的服务,肯定想除了集群以外的机器能访问,而不是像网上那些人省事,直接在master上安装Eclipse,进行开发,这样是不对的,举个例子,我的宿主机是Windows,用VirtualBox搭的集群,我想在windows上使用Eclipse进行编程,使用集群的Hadoop服务,我可不想在master上安装Eclipse开发,虽然会省掉不少错误解决的麻烦事,但是是不对的!服务就是要远程调用的)
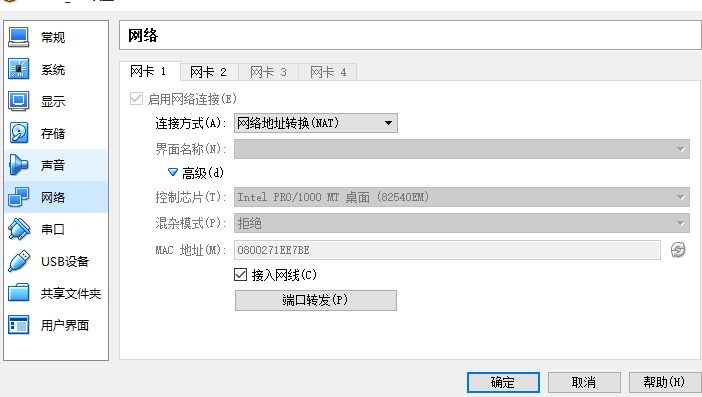
设置第一个网卡:NAT可以使虚拟机使用宿主机的IP上网,这样,你的虚拟机就可以缺什么软件就安什么了,方便!
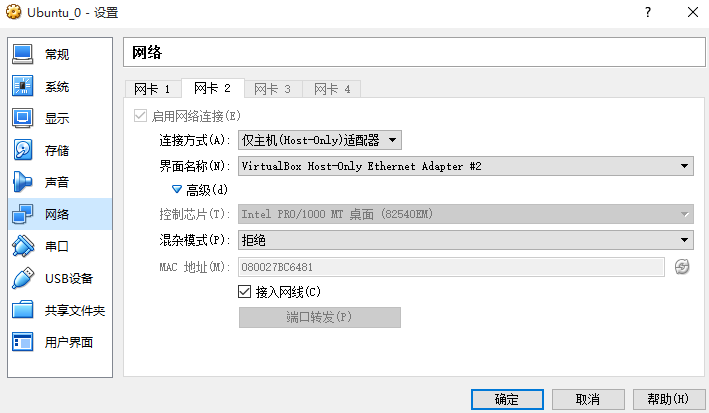
接下来设置第二个网卡:这使得宿主机能够ping通虚拟机
二.克隆虚拟机
选中第一台ubuntu_0(一定要关闭它),你会发现右侧的绵羊 (你应该知道为啥是绵羊吧)图标是可以点击的,我现在用着集群呢,懒得关,索性找张别人的图,点开后的样子是这样的:
(你应该知道为啥是绵羊吧)图标是可以点击的,我现在用着集群呢,懒得关,索性找张别人的图,点开后的样子是这样的:
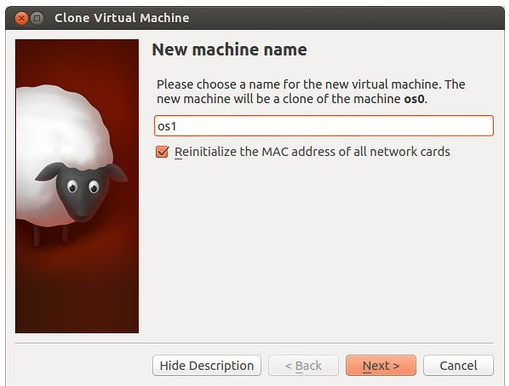
注意要重置网卡设置,命名随便了。我一共clone了3个虚拟机,名字分别是Ubuntu_1,Ubuntu_2,Ubuntu_3,“完全复制”,一直点确定。
三.设置虚拟机静态IP
为啥要设置呢?虚拟机默认是DHCP的,如果你搭建Hadoop集群,不能总是让Hadoop集群所在的机器启动一次就换一次IP吧,那麻烦了。所以,设置静态IP很有必要。
我对网络这块迷糊,我就说我的方法了。
下面的操作适用于所有4个虚拟机。
sudo gedit /etc/network/interfaces
在
auto lo
iface lo inet loopback下加入:
auto eth2 #这是第二块网卡
iface eth2 inet staticaddress 192.168.99.101 #在终端输入ifconfig查看下,然后每台机器这个地址最后一段(共四段)自增1(这四台机器是101(用作master),100,102,103(这三个用作slave))
netmask 255.255.255.0 #ifconfig
gateway 10.0.2.2 # route查看,第一行就是静态IP弄好了,接下来,就是设置主机名了。
命令:
sudo gedit /etc/hostname
命令:
sudo gedit /etc/hosts
修改成需要的主机名(我这里是linux0-cloud,linux1-cloud,linux2-cloud,linux3-cloud),重启?等下,还没完事呢。
接下来修改hosts文件:
为什么要设置hosts,hosts是干嘛的,我的理解是,根据主机名找IP,所以呢,
修改所有虚拟机的hosts文件, 命令:sudo gedit /etc/hosts。设置为如图所示:
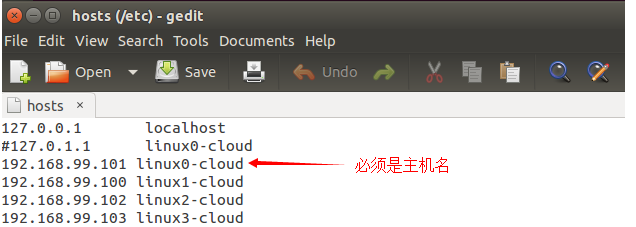
以上操作四台机器必须都应用!好了,重启吧!
四.安装SSH,使得master可以无密码登录所有slave节点(不解释原因)
所有主机安装ssh
命令:
sudo apt-get install ssh在master节点上,
命令:
ssh-keygen -t rsa -P ""
cat .ssh/id_rsa.pub >>.ssh/authorized_keys,使用ssh localhost查看是否能够无密码登录
下面会进行master在无密码情况下ssh连接到slave节点
其他所有节点执行命令:
ssh-keygen -t rsa -P ""接下来,只要将master的公钥放到其它slave节点即可使用无密码登录ssh节点
将master .ssh/authorized_keys使用scp命令拷贝到其它slave节点上,做到master访问slave不需要密码(如果slave访问master,那么过程相反)
在master上执行命令:
scp .ssh/authorized_keys linux1@linux1-cloud:~/.ssh/authorized_keys scp .ssh/authorized_keys linux1@linux2-cloud:~/.ssh/authorized_keys scp .ssh/authorized_keys linux1@linux3-cloud:~/.ssh/authorized_keys
五.安装Hadoop2.7.1
下面先对master节点进行配置,然后将配置好的文件复制到其余机器上
在master上
新建目录,命令:mkdir ~/hadoop
解压hadoop,命令:tar xvf ~/Downloads/hadoop-2.7.1.tar.gz -C ~/hadoop
新建hdfs文件夹(不能使用sudo创建,权限问题):
mkdir ~/dfs
mkdir ~/dfs/name
mkdir ~/dfs/data
mkdir ~/tmp修改hadoop/hadoop-2.7.1/etc/hadoop/hadoop-env.sh配置文件 ,
export JAVA_HOME=/usr/local/java/jdk1.8.0_60修改/etc/hadoop/slaves文件:
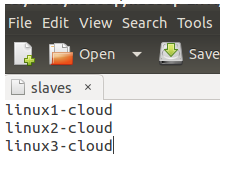
修改/etc/hadoop/core-site.xml文件,
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://linux0-cloud:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/linux1/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>修改/etc/hadoop/hdfs-site.xml文件,
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>linux0-cloud:9001</value>
<description>
这里使namenode同时作为secondary namenode,实际应该设置其他机器的比如linux1-cloud:9001
你可以访问linux0-cloud:50070也可以访问linux0-cloud:9001(或者其他比如:linux1-cloud:8001)查看hadoop概况(namenode们状态是同步的)
</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/linux1/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/linux1/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>修改etc/hadoop/mapred-site.xml,
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>linux0-cloud:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>linux0-cloud:19888</value>
</property>
</configuration>修改yarn-site.xml文件,
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>linux0-cloud:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>linux0-cloud:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>linux0-cloud:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>linux0-cloud:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>linux0-cloud:8088</value>
</property>
</configuration>下面将hadoop复制到其它slave节点:
命令:
sudo scp -r ~/hadoop linux1@linux1-cloud:~/ sudo scp -r ~/hadoop linux1@linux2-cloud:~/ sudo scp -r ~/hadoop linux1@linux3-cloud:~/
设置所有节点环境变量:
gedit ~/.bashrc
添加:
export HADOOP_HOME=/home/linux1/hadoop/hadoop-2.7.1
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin应用环境变量:
source ~/.bashrc六.启动Hadoop
首先格式化:
hdfs namenode -format启动hdfs:
start-dfs.sh启动yarn:
start-yarn.sh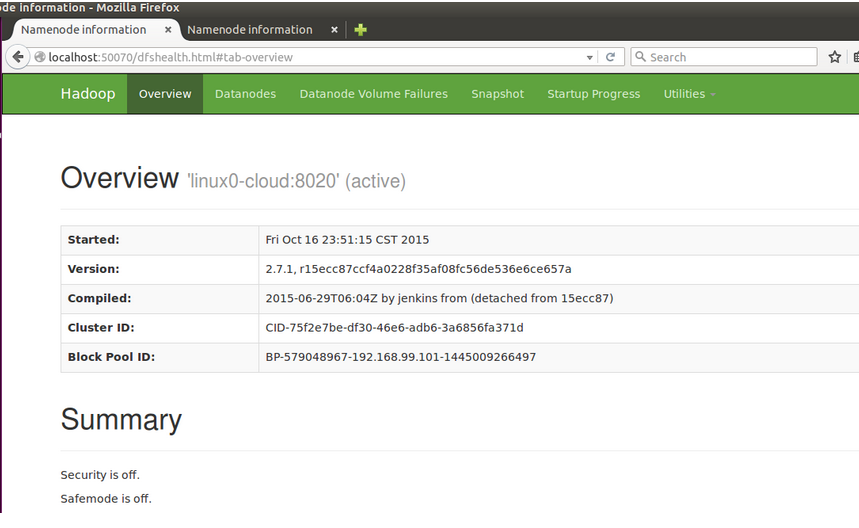
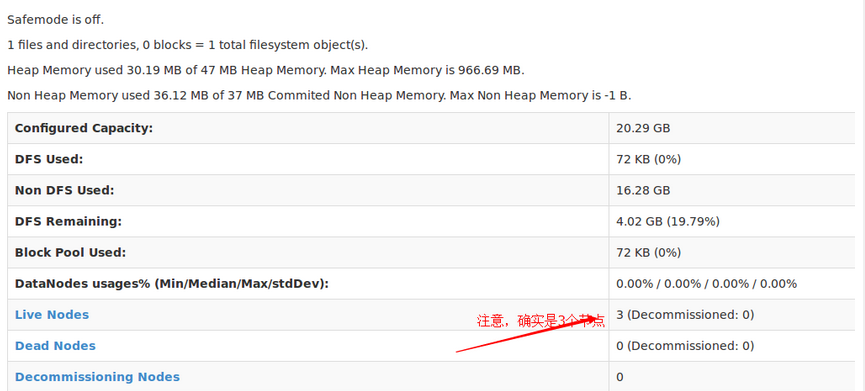
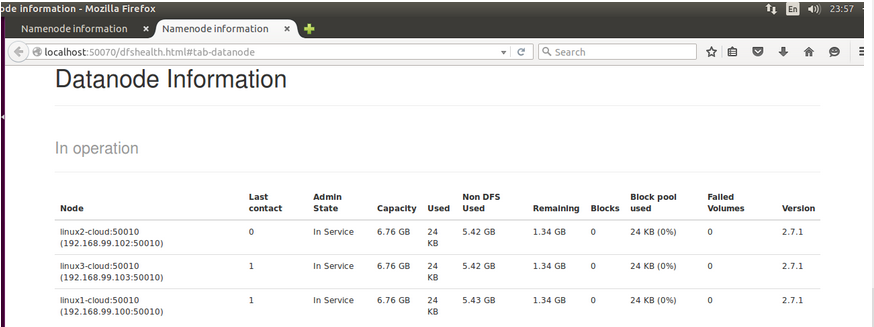
你也可以输入192.168.99.101:50070访问,不给你们截图,宿主机浏览器有不少标签
看完上述内容,你们对如何在window上使用VirtualBox搭建Ubuntu15.04全分布Hadoop2.7.1集群有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/697744/blog/518903



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



