这篇文章给大家分享的是有关ES-Hadoop之elasticsearch-repository-hdfs的示例分析的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
1. 在es/plugins下下载repository-hdfs插件,注意指定下载的是hadoop2版本:
bin/plugin -i elasticsearch/elasticsearch-repository-hdfs/2.1.2-hadoop2
安装完毕后可以看到如下的指示:

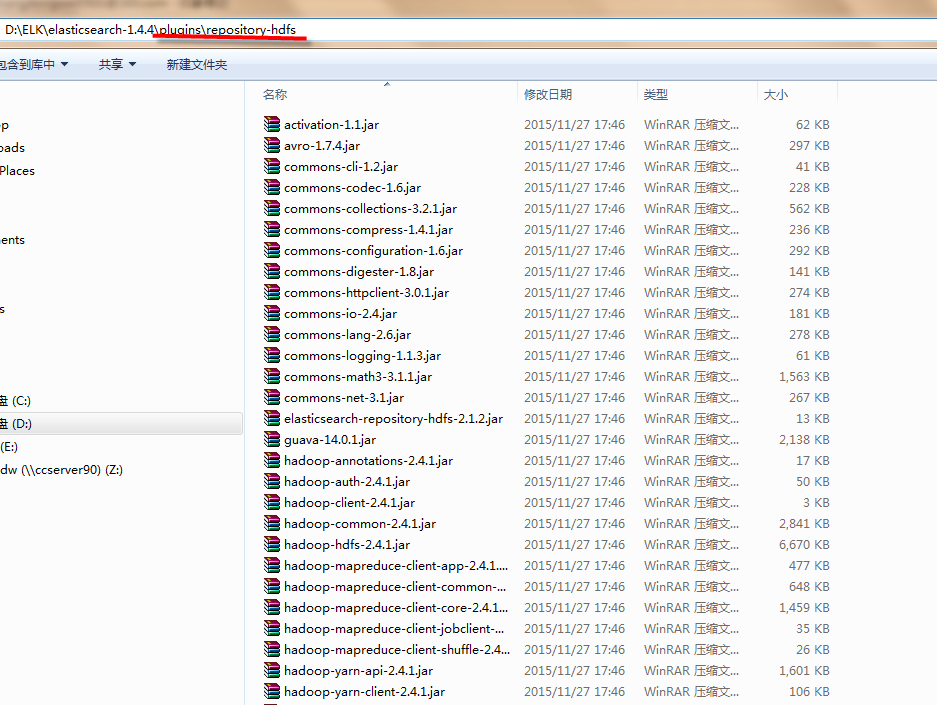
可以看到plugins/repository-hdfs的目录内容如下所示:
2. linux下的es安装该插件后,启动,然后执行如下命令:
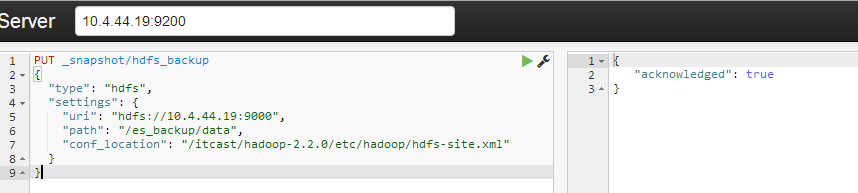
PUT _snapshot/hdfs_backup
{
"type": "hdfs",
"settings": {
"uri": "hdfs://10.4.44.19:9000",
"path": "/es_backup/data",
"conf_location": "/itcast/hadoop-2.2.0/etc/hadoop/hdfs-site.xml"
}
}该命令创建了一个hdfs_backup repository。
创建成功后基于/_snapshot endpoint的访问效果如下:
3. 可以查看当前共有多少个仓库:

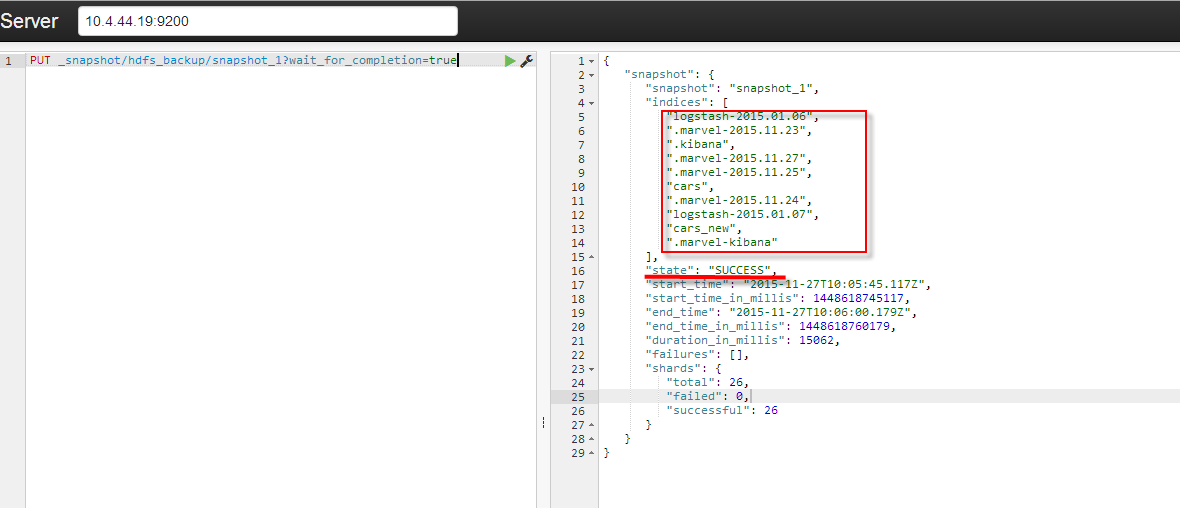
4. 执行如下命令,进行一次backup:
PUT _snapshot/hdfs_backup/snapshot_1?wait_for_completion=true
执行结果:
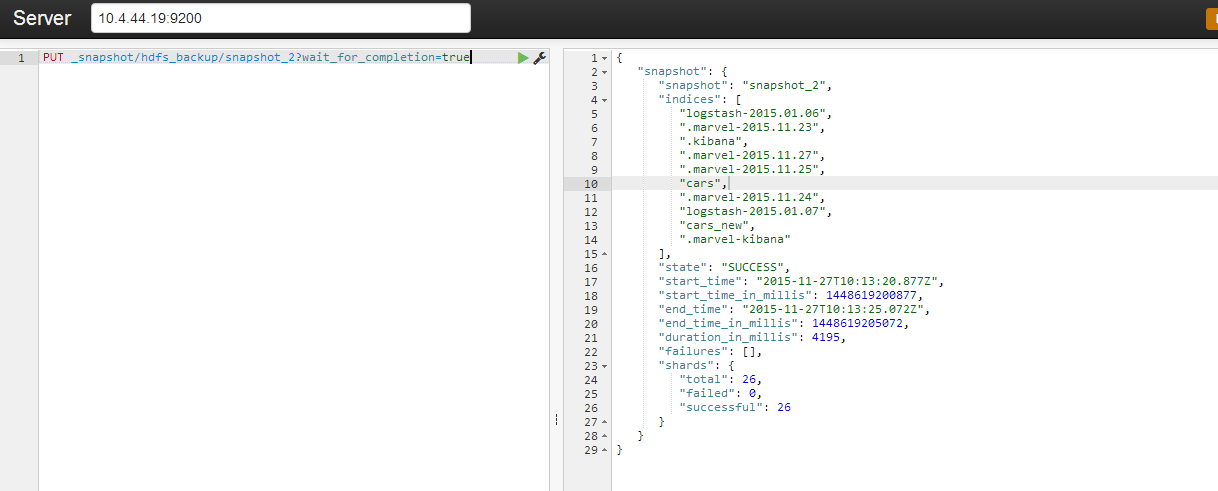
5. 过一段时间可以再次执行一次backup:
PUT _snapshot/hdfs_backup/snapshot_2?wait_for_completion=true
执行结果:
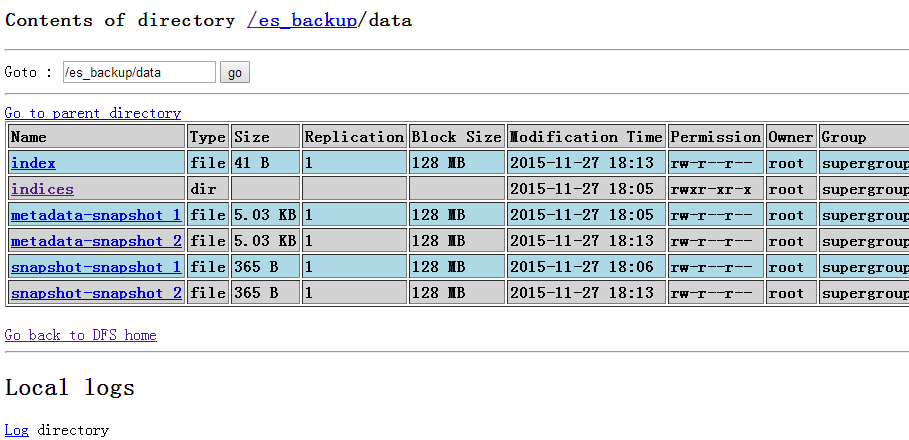
此时可以看到hdfs中备份了之前两次快照的数据:
感谢各位的阅读!关于“ES-Hadoop之elasticsearch-repository-hdfs的示例分析”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





