本篇内容主要讲解“Storm-0.9.3的安装部署步骤”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“Storm-0.9.3的安装部署步骤”吧!
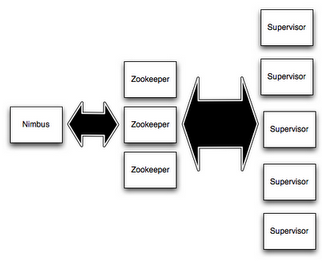
Storm集群中包含两类节点:主控节点(Master Node)和工作节点(Work Node)。其分别对应的角色如下:
主控节点(Master Node)上运行一个被称为Nimbus的后台程序,它负责在Storm集群内分发代码,分配任务给工作机器,并且负责监控集群运行状态。Nimbus的作用类似于Hadoop中JobTracker的角色。
每个工作节点(Work Node)上运行一个被称为Supervisor的后台程序。Supervisor负责监听从Nimbus分配给它执行的任务,据此启动或停止执行任务的工作进程。每一个工作进程执行一个Topology的子集;一个运行中的Topology由分布在不同工作节点上的多个工作进程组成。
Storm集群组件
Nimbus和Supervisor节点之间所有的协调工作是通过Zookeeper集群来实现的。此外,Nimbus和Supervisor进程都是快速失败(fail-fast)和无状态(stateless)的;Storm集群所有的状态要么在Zookeeper集群中,要么存储在本地磁盘上。这意味着你可以用kill -9来杀死Nimbus和Supervisor进程,它们在重启后可以继续工作。这个设计使得Storm集群拥有不可思议的稳定性。
——————————————————————————————————————————
搭建Zookeeper集群
Storm使用Zookeeper协调集群,由于Zookeeper并不用于消息传递,所以Storm给Zookeeper带来的压力相当低。大多数情况下,单个节点的Zookeeper集群足够胜任,不过为了确保故障恢复或者部署大规模Storm集群,可能需要更大规模节点的Zookeeper集群(对于Zookeeper集群的话,官方推荐的最小节点数为3个)。在Zookeeper集群的每台机器上完成以下安装部署步骤:
1. 下载安装Java JDK,官方下载链接为http://java.sun.com/javase/downloads/index.jsp,JDK版本为JDK 6或以上。
2. 根据Zookeeper集群的负载情况,合理设置Java堆大小,尽可能避免发生swap,导致Zookeeper性能下降。保守起见,4GB内存的机器可以为Zookeeper分配3GB最大堆空间。
3. 下载后解压安装Zookeeper包,官方下载链接为http://hadoop.apache.org/zookeeper/releases.html。
4. 根据Zookeeper集群节点情况,在conf目录下创建Zookeeper配置文件zoo.cfg:
tickTime=2000
dataDir=/var/zookeeper/
clientPort=2181
initLimit=5
syncLimit=2
server.1=zookeeper1:2888:3888
server.2=zookeeper2:2888:3888
server.3=zookeeper3:2888:3888
复制代码
5. 在dataDir目录下创建myid文件,文件中只包含一行,且内容为该节点对应的server.id中的id编号。其中,dataDir指定Zookeeper的数据文件目录;其中server.id=host:port:port,id是为每个Zookeeper节点的编号,保存在dataDir目录下的myid文件中,zookeeper1~zookeeper3表示各个Zookeeper节点的hostname,第一个port是用于连接leader的端口,第二个port是用于leader选举的端口。
6. 启动Zookeeper服务:
bin/zkServer.sh start
复制代码
7. 通过Zookeeper客户端测试服务是否可用:
bin/zkCli.sh -server 127.0.0.1:2181
复制代码
————————————————————————————————————————
10.134.84.93 Nimbus
10.139.37.57 Supervisor
10.139.18.45 Supervisor zookeeper
10.134.85.125 Supervisor zookeeper
10.134.74.59 Supervisor zookeeper
1. storm选择使用最新版apache-storm-0.9.3,下载地址:
http://www.apache.org/dyn/closer.cgi/storm/apache-storm-0.9.3/apache-storm-0.9.3.tar.gz
2. storm依赖jdk6和python
2.1 机器已经安装了jdk7,经试验启动storm时会报错。因此选择jdk6最新版6u45,下载地址:
http://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase6-419409.html#jdk-6u45-oth-JPR
选择

2.2 机器自带python2.4.3,但storm依赖2.6以上版本,我们选择使用2.7.9,下载地址:
https://www.python.org/downloads/release/python-279/
1. jdk安装
1.1 由于机器上已经安装了默认的jdk7,在终端直接输入java -version时会提示使用的是1.7

因此,需要把jdk6单独安装在一个目录。
直接执行jdk-6u45-linux-x64.bin,如下:

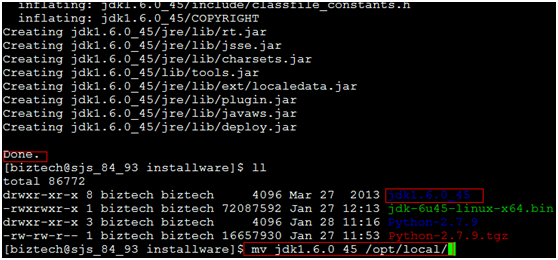
1.2 自动解压完毕后,会在当前目录生成jdk的文件夹,再把此文件夹mv到我们指定的JAVA_HOME地址,如/opt/local/jdk1.6.0_45,如下:
2. python安装
2.1 执行tar zxvf Python-2.7.9.tgz命令,解压Python安装包:

2.2 解压后,进行以下安装步骤:
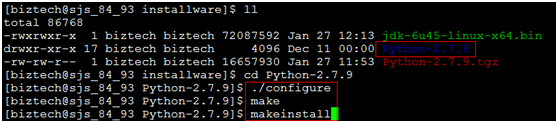
2.3 经过./configure、make、make install后,默认python2.7安装在/usr/local/bin/python2.7,而/usr/bin/python这个软链引用的依然是2.4.3,可以做下替换,如下:

1. 在服务器上解压storm安装包,红色部分为需要修改的配置文件:

2. 修改conf/storm_env.ini,指定使用的java环境

3. 修改conf/storm.yaml,指定strom的以下几项配置:
| #storm 使用的zookeeper 的服务器域名,默认端口2181 storm.zookeeper.servers:- “yf_18_45″- “sjs_85_125″- “sjs_74_59″#nimbus 的节点 nimbus.host: “sjs_84_93″ |
# 数据存储路径
storm.local.dir: “/data/storm”
# 本地日志路径
storm.log.dir: “/opt/logs/storm”
#supervisor 的槽位数及端口号,每个端口号表示一个槽位
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
# 指定drpc 服务器
drpc.servers:
- “yf_18_45″
- “sjs_85_125″
- “sjs_74_59″
- “yf_37_57″
4. 在每个storm节点进行以上安装步骤,其中storm可在一台机器上配置好后再scp到其他各台服务器。
1. 在nimbus节点启动nimbus、storm-ui和logviewer:
bin/storm nimbus &
bin/storm ui &
bin/storm logviewer &
3. 在各supervisor节点启动supervisor和logviewer:
bin/storm supervisor &
bin/storm logviewer &
验证
1. 访问 http://10.134.84.93:8080 ,查看ui是否正常,supervisor数为4,free slot数为16
2. 提交测试storm程序。
bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.3.jar storm.starter.ExclamationTopology ExclamationTopology
到此,相信大家对“Storm-0.9.3的安装部署步骤”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





