这篇文章给大家分享的是有关RocketMQ有什么特点的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
RocketMQ是一款分布式、队列模型的消息中间件,具有以下特点:
1.能够保证严格的消息顺序
2.提供丰富的消息拉取模式
3.高效的订阅者水平扩展能力
4.实时的消息订阅机制
5.亿级消息堆积能力
一.RocketMQ网络部署特点
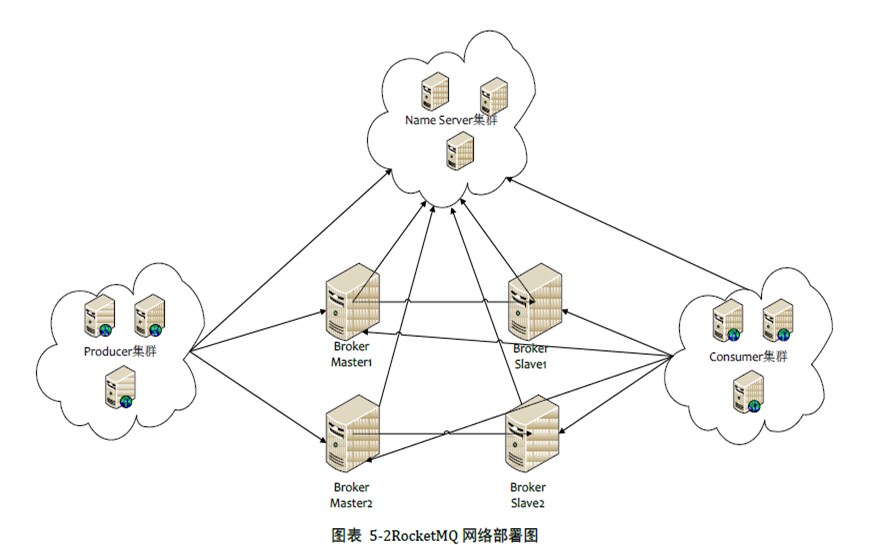
(1)NameServer是一个几乎无状态的节点,可集群部署,节点之间无任何信息同步
(2)Broker部署相对复杂,Broker氛围Master与Slave,一个Master可以对应多个Slaver,但是一个Slaver只能对应一个Master,Master与Slaver的对应关系通过指定相同的BrokerName,不同的BrokerId来定义,BrokerId为0表示Master,非0表示Slaver。Master可以部署多个。每个Broker与NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有的NameServer
(3)Producer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并向提供Topic服务的Master建立长连接,且定时向Master发送心跳。Produce完全无状态,可集群部署
(4)Consumer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并向提供Topic服务的Master、Slaver建立长连接,且定时向Master、Slaver发送心跳。Consumer即可从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定
二.RocketMQ储存特点
(1)零拷贝原理:Consumer消费消息过程,使用了零拷贝,零拷贝包括一下2中方式,RocketMQ使用第一种方式,因小块数据传输的要求效果比sendfile方式好
a )使用mmap+write方式
优点:即使频繁调用,使用小文件块传输,效率也很高
缺点:不能很好的利用DMA方式,会比sendfile多消耗CPU资源,内存安全性控制复杂,需要避免JVM Crash问题
b)使用sendfile方式
优点:可以利用DMA方式,消耗CPU资源少,大块文件传输效率高,无内存安全新问题
缺点:小块文件效率低于mmap方式,只能是BIO方式传输,不能使用NIO
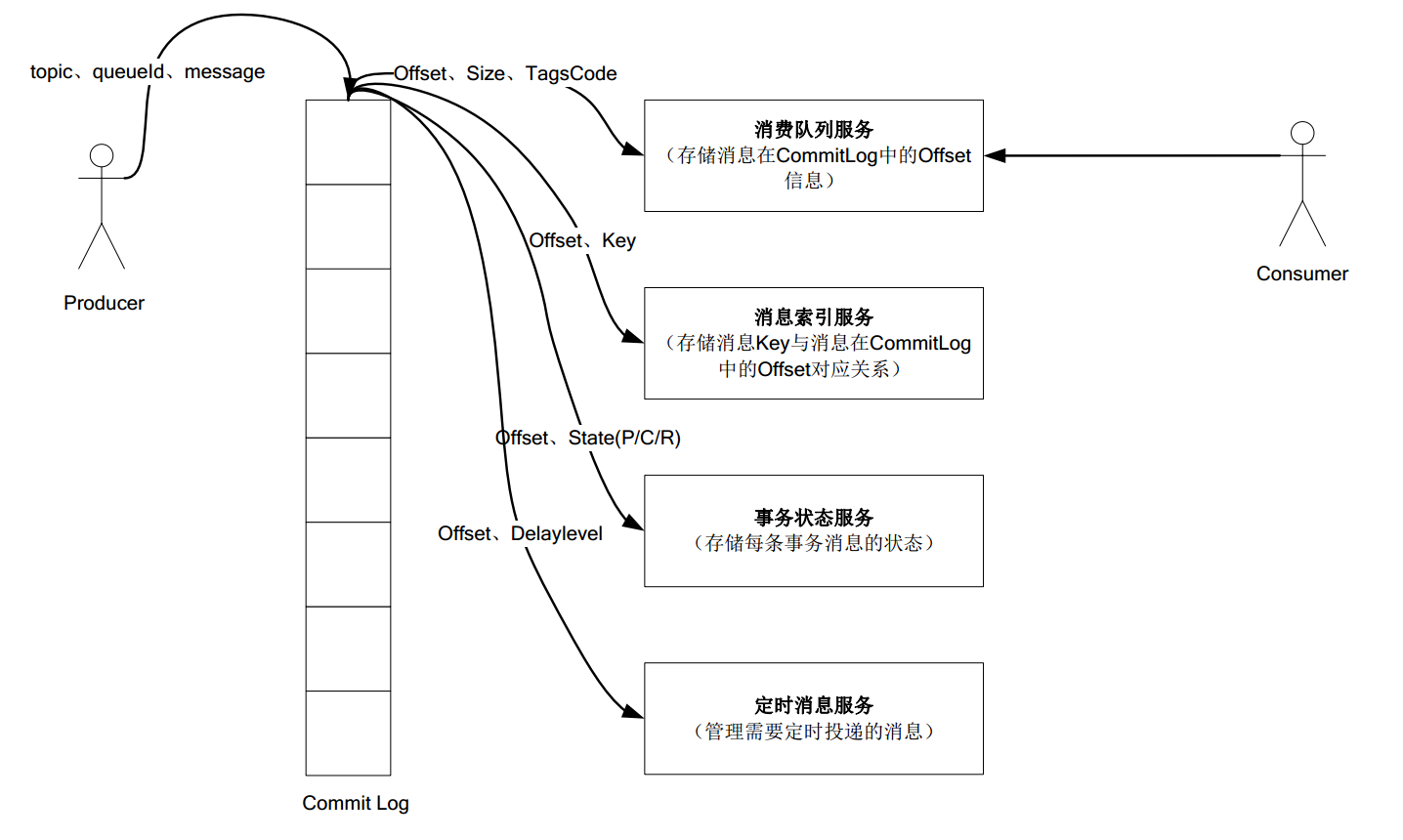
(2)数据存储结构
三.RocketMQ关键特性
1.单机支持1W以上的持久化队列
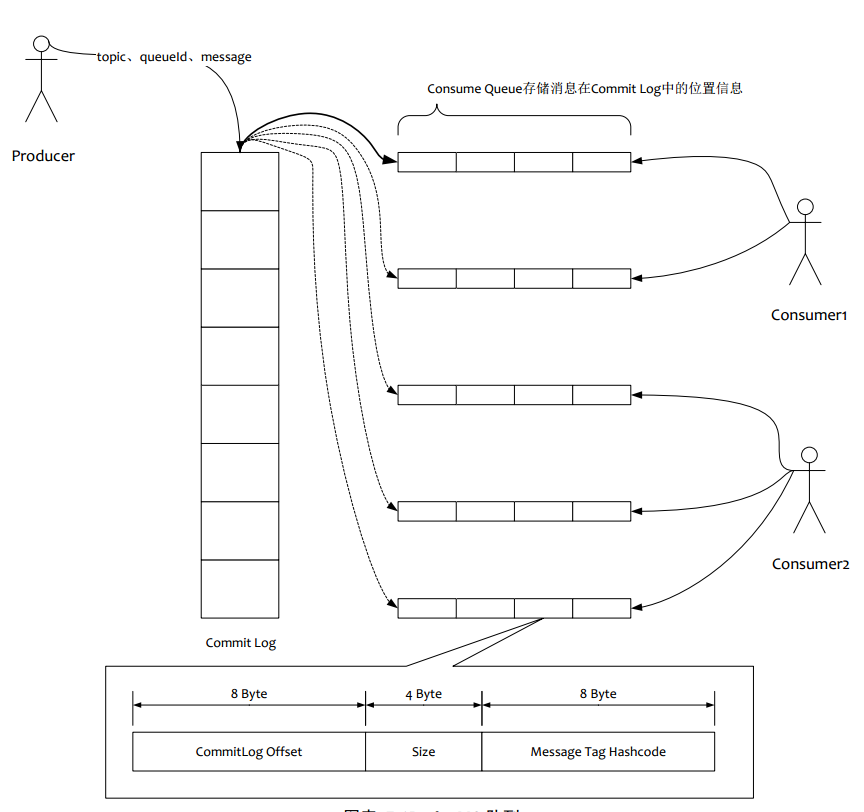
(1)所有数据单独储存到commit Log ,完全顺序写,随机读
(2)对最终用户展现的队列实际只储存消息在Commit Log 的位置信息,并且串行方式刷盘
这样做的好处:
(1)队列轻量化,单个队列数据量非常少
(2)对磁盘的访问串行话,避免磁盘竞争,不会因为队列增加导致IOWait增高
每个方案都有优缺点,他的缺点是:
(1)写虽然是顺序写,但是读却变成了随机读
(2)读一条消息,会先读Consume Queue,再读Commit Log,增加了开销
(3)要保证Commit Log 与 Consume Queue完全的一致,增加了编程的复杂度
以上缺点如何客服:
(1)随机读,尽可能让读命中pagecache,减少IO操作,所以内存越大越好。如果系统中堆积的消息过多,读数据要访问硬盘会不会由于随机读导致系统性能急剧下降,答案是否定的。
a)访问pagecache时,即使只访问1K的消息,系统也会提前预读出更多的数据,在下次读时就可能命中pagecache
b)随机访问Commit Log 磁盘数据,系统IO调度算法设置为NOOP方式,会在一定程度上将完全的随机读变成顺序跳跃方式,而顺序跳跃方式读较完全的随机读性能高5倍
(2)由于Consume Queue存储数量极少,而且顺序读,在pagecache的与读取情况下,Consume Queue的读性能与内存几乎一直,即使堆积情况下。所以可以认为Consume Queue完全不会阻碍读性能
(3)Commit Log中存储了所有的元信息,包含消息体,类似于MySQl、Oracle的redolog,所以只要有Commit Log存在, Consume Queue即使丢失数据,仍可以恢复出来
2.刷盘策略
rocketmq中的所有消息都是持久化的,先写入系统pagecache,然后刷盘,可以保证内存与磁盘都有一份数据,访问时,可以直接从内存读取
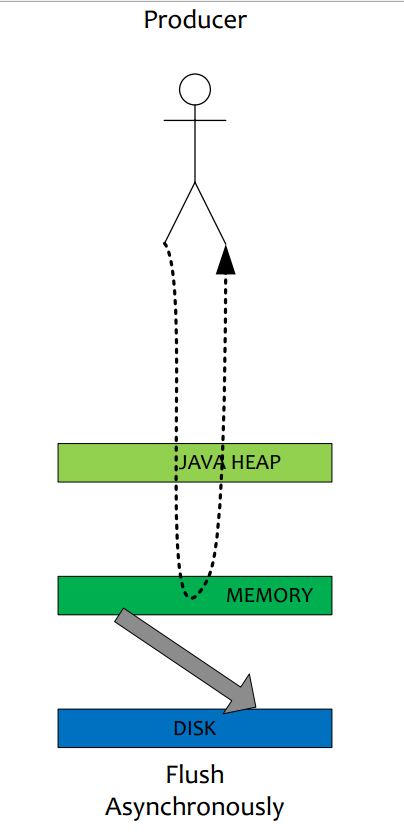
2.1异步刷盘
在有 RAID 卡, SAS 15000 转磁盘测试顺序写文件,速度可以达到 300M 每秒左右,而线上的网卡一般都为千兆网卡,写磁盘速度明显快于数据网络入口速度,那么是否可以做到写完 内存就向用户返回,由后台线程刷盘呢?
(1). 由于磁盘速度大于网卡速度,那么刷盘的进度肯定可以跟上消息的写入速度。
(2). 万一由于此时系统压力过大,可能堆积消息,除了写入 IO,还有读取 IO,万一出现磁盘读取落后情况,会不会导致系统内存溢出,答案是否定的,原因如下:
a) 写入消息到 PAGECACHE 时,如果内存不足,则尝试丢弃干净的 PAGE,腾出内存供新消息使用,策略是 LRU 方式。
b) 如果干净页不足,此时写入 PAGECACHE 会被阻塞,系统尝试刷盘部分数据,大约每次尝试 32 个 PAGE,来找出更多干净 PAGE。
综上,内存溢出的情况不会出现
2.2同步刷盘:
同步刷盘与异步刷盘的唯一区别是异步刷盘写完 PAGECACHE 直接返回,而同步刷盘需要等待刷盘完成才返回,同步刷盘流程如下:
(1)写入 PAGECACHE 后,线程等待,通知刷盘线程刷盘。
(2)刷盘线程刷盘后,唤醒前端等待线程,可能是一批线程。
(3)前端等待线程向用户返回成功。
3.消息查询
3.1按照MessageId查询消息
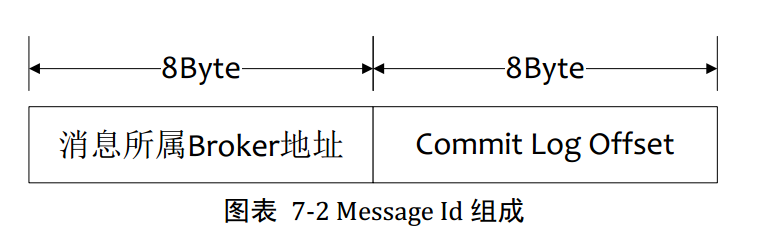
MsgId总共16个字节,包含消息储存主机地址,消息Commit Log Offset。从MsgId中解析出Broker的地址和Commit Log 偏移地址,然后按照存储格式所在位置消息buffer解析成一个完整消息
3.2按照Message Key查询消息
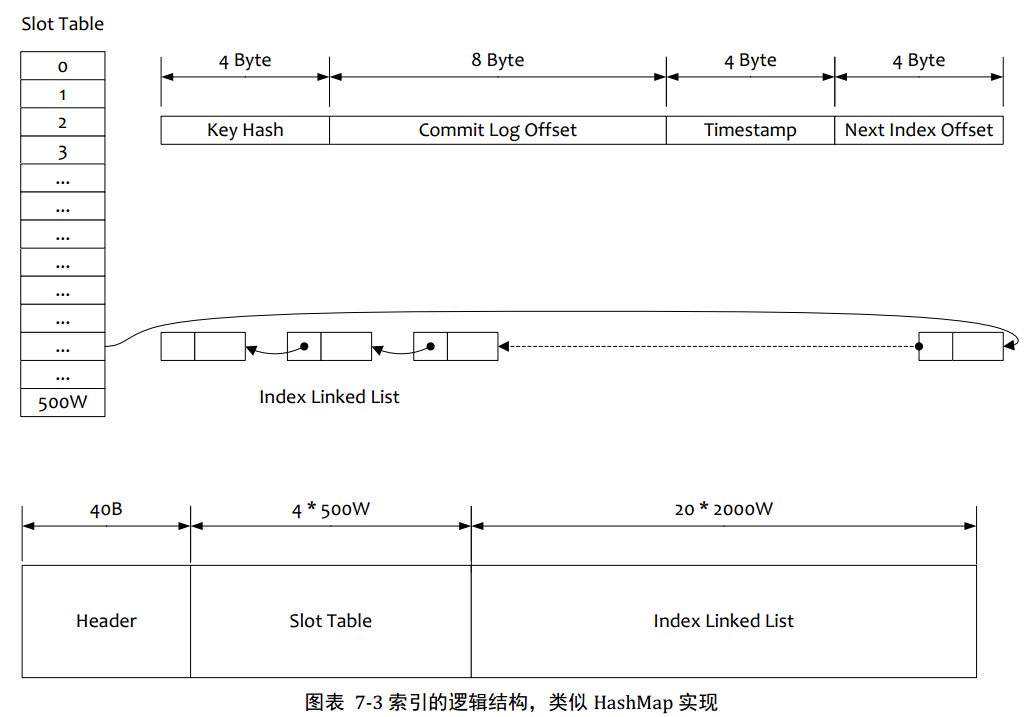
1.根据查询的key的hashcode%slotNum得到具体的槽位置 (slotNum是一个索引文件里面包含的最大槽目数目,例如图中所示slotNum=500W)
2.根据slotValue(slot对应位置的值)查找到索引项列表的最后一项(倒序排列,slotValue总是指向最新的一个索引项)
3.遍历索引项列表返回查询时间范围内的结果集(默认一次最大返回的32条记录)
4.Hash冲突,寻找key的slot位置时相当于执行了两次散列函数,一次key的hash,一次key的hash取值模,因此这里存在两次冲突的情况;第一种,key的hash值不同但模数相同,此时查询的时候会在比较第一次key的hash值(每个索引项保存了key的hash值),过滤掉hash值不想等的情况。第二种,hash值相等key不想等,出于性能的考虑冲突的检测放到客户端处理(key的原始值是存储在消息文件中的,避免对数据文件的解析),客户端比较一次消息体的key是否相同
5.存储,为了节省空间索引项中存储的时间是时间差值(存储时间——开始时间,开始时间存储在索引文件头中),整个索引文件是定长的,结构也是固定的
4.服务器消息过滤
RocketMQ的消息过滤方式有别于其他的消息中间件,是在订阅时,再做过滤,先来看下Consume Queue存储结构
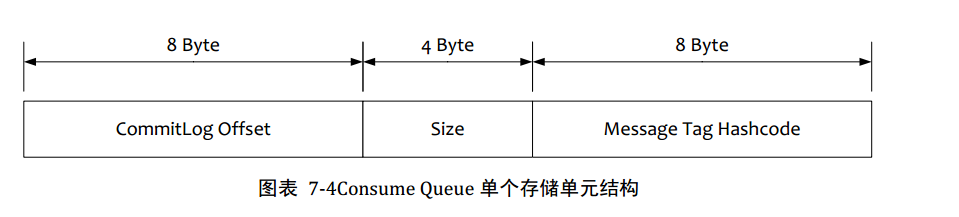
1.在Broker端进行Message Tag比较,先遍历Consume Queue,如果存储的Message Tag与订阅的Message Tag不符合,则跳过,继续比对下一个,符合则传输给Consumer。注意Message Tag是字符串形式,Consume Queue中存储的是其对应的hashcode,比对时也是比对hashcode
2.Consumer收到过滤消息后,同样也要执行在broker端的操作,但是比对的是真实的Message Tag字符串,而不是hashcode
为什么过滤要这么做?
1.Message Tag存储hashcode,是为了在Consume Queue定长方式存储,节约空间
2.过滤过程中不会访问Commit Log 数据,可以保证堆积情况下也能高效过滤
3.即使存在hash冲突,也可以在Consumer端进行修正,保证万无一失
5.单个JVM进程也能利用机器超大内存
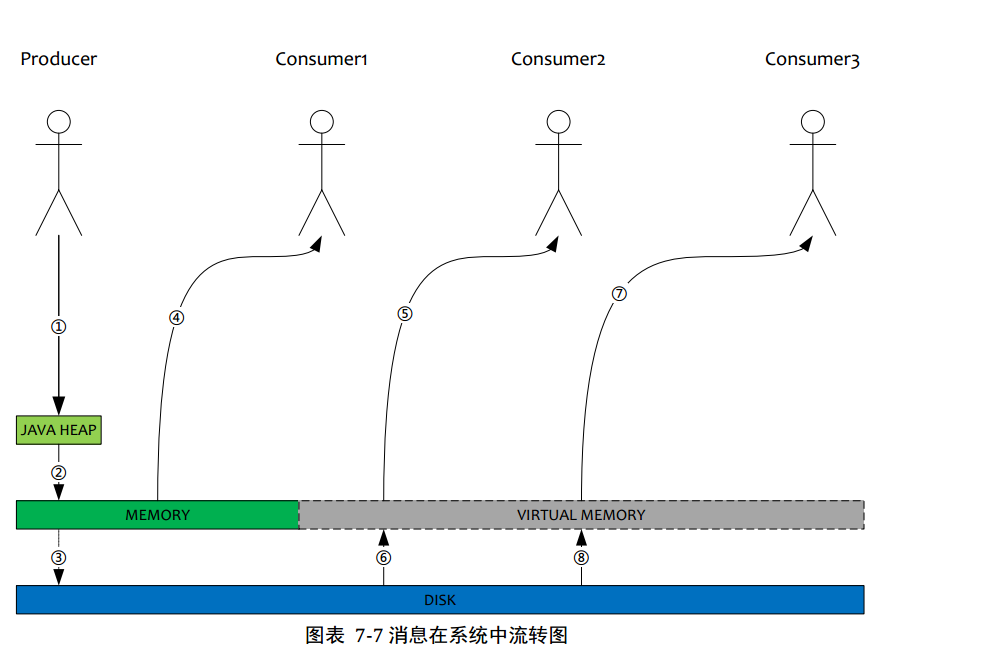
1.Producer发送消息,消息从socket进入java 堆
2.Producer发送消息,消息从java堆进入pagecache,物理内存
3.Producer发送消息,由异步线程刷盘,消息从pagecache刷入磁盘
4.Consumer拉消息(正常消费),消息直接从pagecache(数据在物理内存)转入socket,到达Consumer,不经过java堆。这种消费场景最多,线上96G物理内存,按照1K消息算,可以物理缓存1亿条消息
5.Consumer拉消息(异常消费),消息直接从pagecache转入socket
6.Consumer拉消息(异常消费),由于socket访问了虚拟内存,产生缺页中断,此时会产生磁盘IO,从磁盘Load消息到pagecache,然后直接从socket发出去
7.同5
8.同6
6.消息堆积问题解决办法
1 消息的堆积容量、依赖磁盘大小
2 发消息的吞吐量大小受影响程度、无Slave情况,会受一定影响、有Slave情况,不受影响
3 正常消费的Consumer是否会受影响、无Slave情况,会受一定影响、有Slave情况,不受影响
4 访问堆积在磁盘的消息时,吞吐量有多大、与访问的并发有关,最终会降到5000左右
在有Slave情况下,Master一旦发现Consumer访问堆积在磁盘的数据时,回想Consumer下达一个重定向指令,令Consumer从Slave拉取数据,这样正常的发消息与正常的消费不会因为堆积受影响,因为系统将堆积场景与非堆积场景分割在了两个不同的节点处理。这里会产生一个问题,Slave会不会写性能下降,答案是否定的。因为Slave的消息写入只追求吞吐量,不追求实时性,只要整体的吞吐量高就行了,而Slave每次都是从Master拉取一批数据,如1M,这种批量顺序写入方式使堆积情况,整体吞吐量影响相对较小,只是写入RT会变长。
感谢各位的阅读!关于“RocketMQ有什么特点”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





