这篇文章给大家分享的是有关如何在生产过程中监控Kubernetes的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
监测Kubernetes集群不是一个简单的事情。为了阐述可能会发生的错误的类型,这里是我们在AWS配置上的一个例子。
我们集群中的一个例子完美展示了用SkyDNS运行以及所有pods启动的健康状态,然而,在几分钟之后,SkyDNS就进入“CrashLoopBackoff”状态了。应用程序容器已经是启动的,但是还在功能失调阶段,因为他们在第一次重新启动的时候无法到达数据库。
结果原来是集群宕机,但是我们只能盯着事件和pods状态,对于发生了什么无法得到一个清晰的理解。
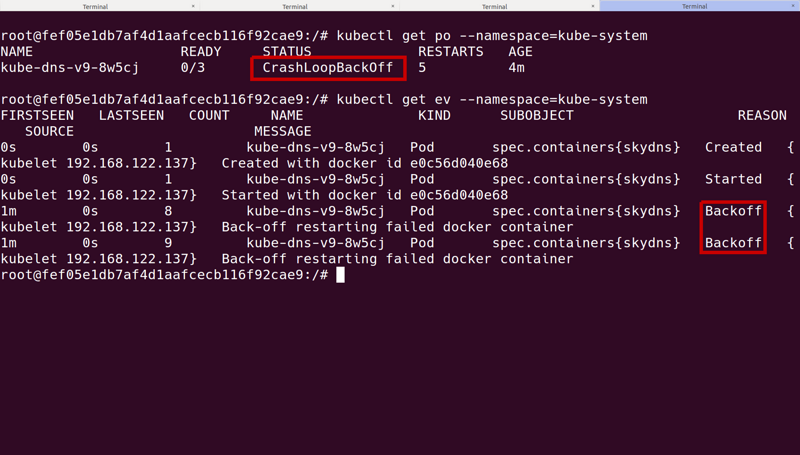
在联系到主节点,看了SkyDNS pod的日志之后,他们用etcd揭露一个问题。SkyDNS无法连接,或者连接在它建立之后立刻变得不稳定了。etcd它本身就是在运行的,那么问题是出在哪里呢?
在做了相当一部分的调查之后,我们找到了answer。高延迟网络连接磁盘导致读写错误,这就导致了etcd无法写到文件系统。虽然它是正确配置而且也在运行工作,但是它并不是一直可为Kubernetes服务所用。
吸取教训——即使你已经成功地建立起集群,但也不能保证它就可以像预期的那样继续工作。
那么在配置期间哪些问题比较容易出错呢?问题主要有以下这些:
主机之间没有联系
etcd宕机或者不稳定/错误配置导致滞后
主机间的覆盖网络层损坏
单个节点中的任意一个都会宕机
Kubernetes API服务器或者控制器管理者宕机
Docker无法启动容器
网络分割会影响节点子集
我们在跟第一届KubeCon的参加者交流了一些意见,头脑风暴出以下可能的解决办法:
你怎样评估Kubernetes集群的健康?@klizhenas建议创建一个能够给pods进行调度以及取消调度的app;有没有人创建一下这个?
——Brandon Philips(@Brandon Philips)2015年11月11日
我们评估一下来监控Kubernetes的方法:
典型监测;
面向应用的冒烟测试
传统的监控监测方法还没有出现短缺。这个种类之中最好的选择之一就是monit。
这是一个极其轻便精简(单个执行文件),而且久经战场的后台程序运行在成千上万台机器上面——为小的起步但是是限制到监测单个系统。这是它最大的缺点。
使用monit过程中发现的问题之一就是一组测试执行有限和拓展性的缺乏。虽然可配置,但是我们还是不得不通过写脚本来拓展它的功能,或者通过微弱的界面来使特殊目的程序得到控制。
更加重要的是,我们发现,连接几个monit实例到一个高可用系统和弹性网络是非常难的,而且系统和网络还要代理收集自己分享的信息,然后协同工作来另这些信息保持更新。
“冒烟测试”这个术语的定义:
“一系列初步的测试来揭示一些简单的故障的严重性,以此来拒绝预期中软件的发布。它通常包含一个子集的测试,测试覆盖了大多数重要的作用来确定重要作用在按照预期运行。冒烟测试最频繁的特点就是它运行的很快,通常是秒级的。”
以我们已有的Kubernetes知识,我们坚信我们可以使用冒烟测试用以下特点来创建一个监视系统:
轻量级定期测试
高可用性和弹性网络分区
零故障操作环境
时间序列作为健康数据的历史
不管故障容易发生的抽象层次,就算是应用程序故障,或者是低层次网络错误,这个系统都能够追踪他们以查到实际的原因。
我们的高层次解决方案是一系列程序Agent,一个集群中的一个节点驻留在另一个节点上。他们互相之间通过一个Serf提供的gossip协议来交流:
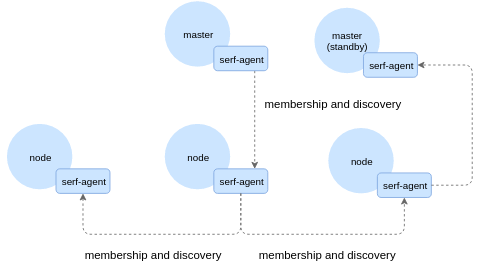
Kubernetes关键组件的Agents监控状态——etcd,scheduler,API服务器和另外一些东西,还有一些执行冒烟程序——创建可以互相交流的轻量级容器。
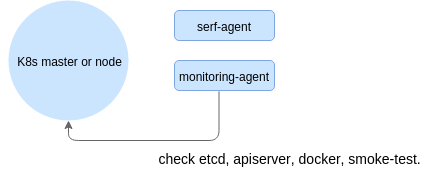
Agent定期同步数据,这样每个节点都是随时更新关于集群作为一个整体的信息。由于Serf提供的一致性保证比较弱,导致更新信息也不是很严格。定期测试结果保存到后端——这可以很简单,就如同一个SQLite数据库或者InfluxDB等一系列实时数据库。
拥有一个对等系统对侦测故障和监测信息十分有帮助,即使系统中的关键部分部分宕机也没有关系。在下面的例子中,主要节点以及大部分的节点都已经宕机,这就导致etcd也出了故障。然而,我们仍然可以得到关于集群连接到以下任意一个节点的诊断信息:
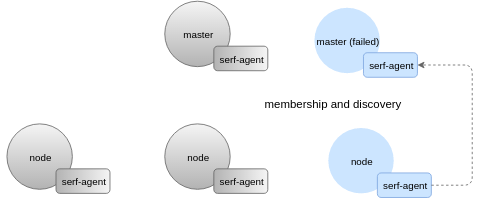
这里是在部分损坏的系统截图:
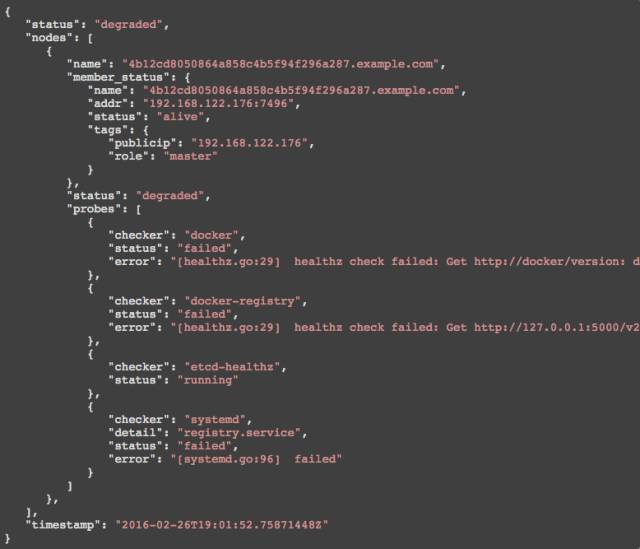
由于它的简易,目前的模型就有了一定的限制。如果是为更小一些的集群(比如8个节点)就可以运行,然而,在一个再大一点的集群,你就不想每个节点都可以互相交流了。这个解决方式就是我们计划采取的方案是创建一个特殊的聚合器,从Skype的超级节点那里或者是从Consul的“anti-entropy catelogs上面借鉴一些想法。
监测Kubernetes集群的状态不是直接使用传统监测工具就可以了的。手动故障排除有一定的复杂性,在集群里有一个自动反馈循环的话,就可以消除很大部分的复杂性。Satellite项目已经证明当操作集群的时候对我们是有用的,所以我们决定对它进行开源,希望它可以成为一个帮助提升kubernetes发现错误系统。
感谢各位的阅读!关于“如何在生产过程中监控Kubernetes”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





