HIVE作业管理分析及解决方案是什么,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
对于hive任务展示的时候需要把id和mr id关联, 杀死任务的时候需要把所有属于这个hive语句的任务都杀死。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。 本质是将SQL转换为MapReduce程序 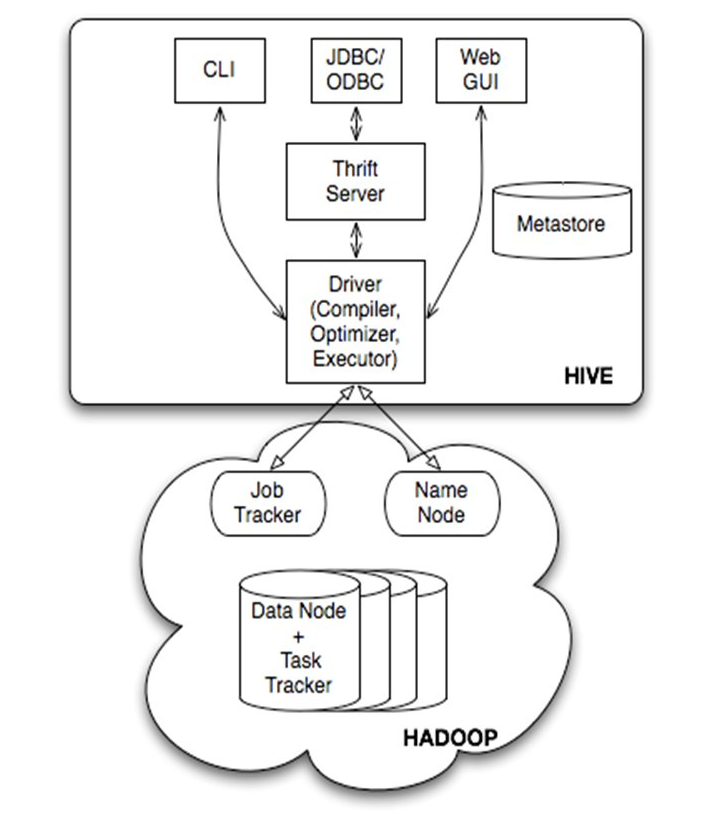
thrift是facebook开发的一个软件框架,它用来进行可扩展且跨语言的服务的开发,hive集成了该服务,能让不同的编程语言调用hive的接口。
两者都允许远程客户端使用多种编程语言,通过HiveServer或者HiveServer2,客户端可以在不启动CLI的情况下对Hive中的数据进行操作, 允许远程客户端使用多种编程语言如java,python等向hive提交请求,取回结果(从hive0.15起就不再支持hiveserver了)。
HiveServer或者HiveServer2都是基于Thrift的,但HiveSever有时被称为Thrift server,而HiveServer2却不会。
既然已经存在HiveServer,为什么还需要HiveServer2呢?
这是因为==HiveServer不能处理多于一个客户端的并发请求==,这是由于HiveServer使用的Thrift接口所导致的限制,不能通过修改HiveServer的代码修正。因此在Hive-0.11.0版本中重写了HiveServer代码得到了HiveServer2,进而解决了该问题。
HiveServer2支持多客户端的并发和认证,为开放API客户端如JDBC、ODBC提供更好的支持。
命令行接口,CLI可以以两种模式运行,一种是单纯的客户端,直接连接driver;还有一种是连接hiveserver1;hiveserver1已经被hiveserver2取代,并在1.0.0版本去掉。因为安全性等原因,官方希望用beeline替代cli;或者直接修改cli的底层实现来达到无缝修改。 https://issues.apache.org/jira/browse/HIVE-10511 https://cwiki.apache.org/confluence/display/Hive/Replacing+the+Implementation+of+Hive+CLI+Using+Beeline
hive客户端提供了一种通过网页的方式访问hive所提供的服务。这个接口对应hive的hwi组件(hive web interface),使用前要启动hwi服务。 ==hwi因为使用较少,2.2版本后被移除。==
通过Thrift协议与某个单独的HiveServer2进程进行连接通信。
HiveServer2提供了一个新的命令行工具Beeline,它是基于SQLLine CLI的JDBC客户端。
Beeline工作模式有两种,即本地嵌入模式和远程模式。嵌入模式情况下,它返回一个嵌入式的Hive(类似于Hive CLI)。而远程模式则是通过Thrift协议与某个单独的HiveServer2进程进行连接通信。
在开发工作当中,提交 Hadoop 任务,任务的运行详情,这是我们所关心的,当业务并不复杂的时候,我们可以使用 Hadoop 提供的命令工具去管理 YARN 中的任务。在编写 Hive SQL 的时候,需要在 Hive 终端,编写 SQL 语句,来观察 MapReduce 的运行情况,长此以往,感觉非常的不便。另外随着业务的复杂化,任务的数量增加,此时我们在使用这套流程,已预感到力不从心,这时候 Hive 的监控系统此刻便尤为显得重要,我们需要观察 Hive SQL 的 MapReduce 运行详情以及在 YARN 中的相关状态。
Hive Falcon 用于监控 Hadoop 集群中被提交的任务,以及其运行的状态详情。其中 Yarn 中任务详情包含任务 ID,提交者,任务类型,完成状态等信息。另外,还可以编写 Hive SQL,并运 SQL,查看 SQL 运行详情。也可以查看 Hive 仓库中所存在的表及其表结构等信息。
==不能将HIVE的查询和yarn任务关联在一起,不满足需求。==
待确认
待确认
采用thrift方式实现。具体可以下载hue源代码,apps/beeswax, 使用python实现。
此实现方式只能管理通过hue界面执行的查询,其他客户端的查询无法管理。 查询和mapreduce的关联关系是通过分析日志实现的,thrift没有对应的接口。 https://groups.google.com/a/cloudera.org/forum/#!topic/hue-user/wSDcTnZJqTg
日志
2017-04-26 13:54:24,068 INFO ql.Driver (Driver.java:compile(411)) - Compiling command(queryId=hadoop_20170426135454_41352e71-5685-48e5-9e4d-c25819669666): select count(*) from t_function
2017-04-26 13:54:26,891 INFO HiveMetaStore.audit (HiveMetaStore.java:logAuditEvent(388)) - ugi=hadoop ip=unknown-ip-addr cmd=get_table : db=default tbl=t_function
2017-04-26 13:54:37,444 INFO ql.Driver (Driver.java:compile(463)) - Semantic Analysis Completed
2017-04-26 13:54:37,677 INFO ql.Driver (Driver.java:getSchema(245)) - Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:bigint, comment:null)], properties:null)
2017-04-26 13:54:38,331 INFO ql.Driver (Driver.java:compile(541)) - Completed compiling command(queryId=hadoop_20170426135454_41352e71-5685-48e5-9e4d-c25819669666); Time taken: 14.712 second
s
2017-04-26 13:54:38,332 INFO ql.Driver (Driver.java:execute(1448)) - Executing command(queryId=hadoop_20170426135454_41352e71-5685-48e5-9e4d-c25819669666): select count(*) from t_function
2017-04-26 13:54:38,334 INFO ql.Driver (SessionState.java:printInfo(927)) - Query ID = hadoop_20170426135454_41352e71-5685-48e5-9e4d-c25819669666
2017-04-26 13:54:38,335 INFO ql.Driver (SessionState.java:printInfo(927)) - Total jobs = 1
2017-04-26 13:54:38,516 INFO ql.Driver (SessionState.java:printInfo(927)) - Launching Job 1 out of 1
2017-04-26 13:55:24,615 INFO exec.Task (SessionState.java:printInfo(927)) - Starting Job = job_1493083994846_0010, Tracking URL = http://T-163:23188/proxy/application_1493083994846_0010/
2017-04-26 13:55:24,860 INFO exec.Task (SessionState.java:printInfo(927)) - Kill Command = /opt/beh/core/hadoop/bin/hadoop job -kill job_1493083994846_0010未发现完全实现该功能的开源方案,接下来需要看看有没有其他人干过类似的事,并发了相关文章。
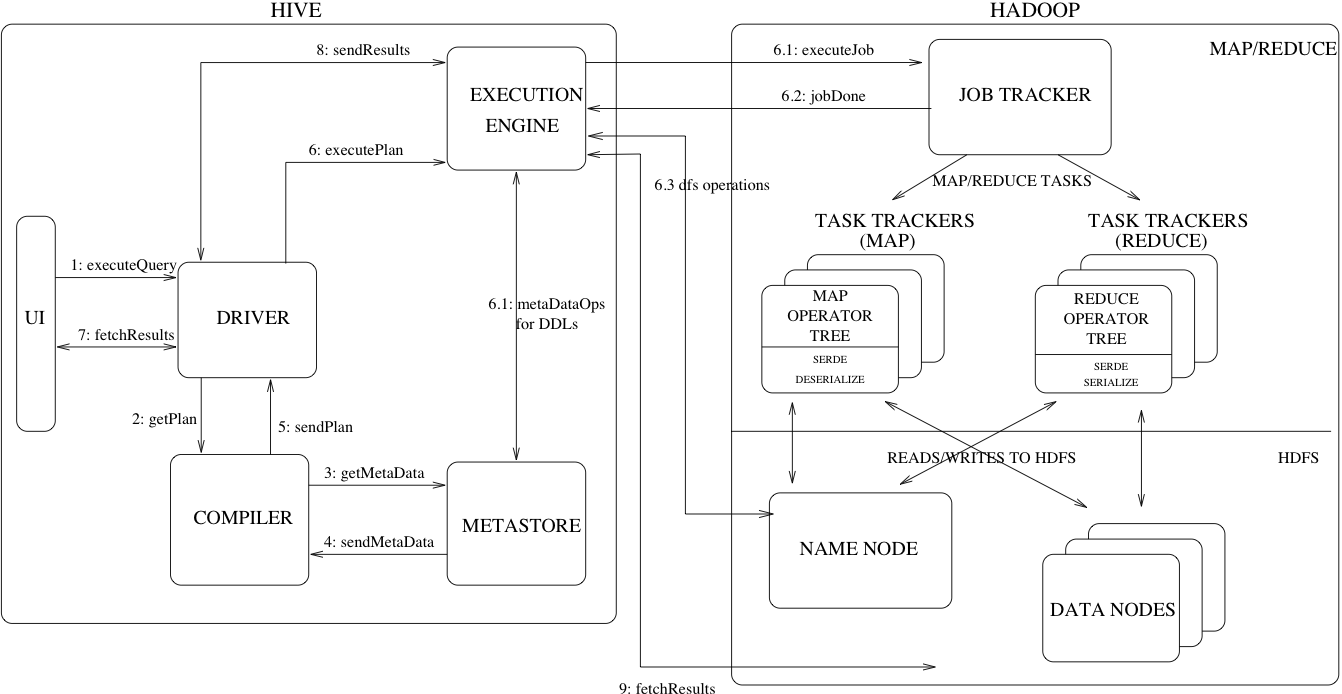
目前数据平台使用Hadoop构建,为了方便数据分析师的工作,使用Hive对Hadoop MapReduce任务进行封装,我们面对的不再是一个个的MR任务,而是一条条的SQL语句。数据平台内部通过类似JDBC的接口与HiveServer进行交互,仅仅能够感知到一条SQL的开始与结束,而中间的这个过程通常是漫长的(两个因素:数据量、SQL复杂度),某些场景下用户需要了解这条SQL语句的执行进度,从而为我们引入以下几个问题:
(1)通过JDBC接口执行一条SQL语句时,这条SQL语句被转换成几个MR任务,每个MR任务的JobId是多少,如何维护这条SQL语句与MR任务的对应关系?
(2)如何获取MR任务的运行状态,通过JobClient?
(3)通过HiveServer是否可以获取到上述信息?
http://www.cnblogs.com/yurunmiao/p/4224137.html
通过之前的调研发现,不管是开源项目还是其他网络资料,大多数需求只实现了特定情况下的hive查询与yarn任务之间的对应, 多数还是在log上做文章,通过分析hive产生的日志来获得查询和yarn任务的关系。
种种迹象表明,情况不太乐观,遇到硬茬了;想做一种兼容所有执行方式的查询管理工具,有比较大的难度,需要深入到源代码去了解。
所有查询方式
graph LR
Hue-->Thrift
Thrift-->Driver
CLI-->Driver
HWI-->Driver
Beeline-->Driver
Beeline-->ThriftHWI方式官方将在2.2版本后去掉,且使用率不高,暂不支持。
Thrift方式支持多客户端的并发和认证,官方建议采用这种方式,故Beeline只支持Thrift使用方式。
CLI虽然不通过Thrift,但因为现在的项目用的比较多,考虑支持。
通过以上分析,我们要支持的访问方式如下。
支持查询方式
graph LR
Hue-->Thrift
Thrift-->Driver
CLI-->Driver
Beeline-->Thrift通过上述分析,我们得出我们的研究方向,并确定了研究方案。 主要分两部分,CLI模式任务管理和Thrift模式任务管理。
我们知道,cli模式下,我们一次只能执行一条查询,查询执行过程中,我们可以通过ctrl+c来终止查询。 ctrl+c是给进程发送sig_int中断信号。
通过阅读源码我们发现,中断信号的处理在processLine函数中触发,该函数为处理单条命令。 http://blog.csdn.net/lpxuan151009/article/details/7956518 注: 源码为hive1.1分支,其中hive-cli工程即为CLI的对应工程。 入口类为org.apache.hadoop.hive.cli.CliDriver。
if (allowInterrupting) {
// Remember all threads that were running at the time we started line processing.
// Hook up the custom Ctrl+C handler while processing this line
interruptSignal = new Signal("INT");
oldSignal = Signal.handle(interruptSignal, new SignalHandler() {
private final Thread cliThread = Thread.currentThread();
private boolean interruptRequested;
@Override
public void handle(Signal signal) {
boolean initialRequest = !interruptRequested;
interruptRequested = true;
// Kill the VM on second ctrl+c
if (!initialRequest) {
console.printInfo("Exiting the JVM");
System.exit(127);
}
// Interrupt the CLI thread to stop the current statement and return
// to prompt
console.printInfo("Interrupting... Be patient, this might take some time.");
console.printInfo("Press Ctrl+C again to kill JVM");
// First, kill any running MR jobs
HadoopJobExecHelper.killRunningJobs();
TezJobExecHelper.killRunningJobs();
HiveInterruptUtils.interrupt();
}
});
}至此,CLI查询的终止操作我们已经通过进程和源代码两种方式获取到, 此种任务管理的任务解决方案见六。
执行流程
graph LR
processCmd-->processLocalCmd
processLine-->processCmd
executeDriver-->processLine
run-->executeDriver
main-->runprocessLocalCmd
Driver qp = (Driver) proc;
PrintStream out = ss.out;
long start = System.currentTimeMillis();
if (ss.getIsVerbose()) {
out.println(cmd);
}
qp.setTryCount(tryCount);
ret = qp.run(cmd).getResponseCode();
if (ret != 0) {
qp.close();
return ret;
}查询实际执行的地方,可以在此处将执行相关信息输出,输出方式可选择log方式或者数据库,也可选择rpc(rpc方式)
相比较而言,CLI的任务管理相对简单,因为每个CLI只能执行一个查询; 而Thrift模式则支持并发,这里的Thrift模式我们指的是hiveserver2的实现方式。 通过Thrift模式,Hue,Beeline,Ambari等等客户端均可以连接到hive执行查询任务, 需要把这些查询任务都统一管理起来。
Thrift连接
graph LR
Hue-->hiveserver2
Beeline-->hiveserver2
Ambari-->hiveserver2
other-->hiveserver2我们发现,官方提供的thrift包主要实现的是一个连接所对应的各种操作, 但并不包括连接间的信息;即连接间的信息并未提供外部接口。
下面为一段Thrift示例代码,主要功能为建立一个连接后查询hive的数据数据。
thrift示例代码
TSocket tSocket = new TSocket("T-162", 10000);
tSocket.setTimeout(20000);
TTransport transport = tSocket;
TBinaryProtocol protocol = new TBinaryProtocol(transport);
TCLIService.Client client = new TCLIService.Client(protocol);
transport.open();
TOpenSessionReq openReq = new TOpenSessionReq();
TOpenSessionResp openResp = client.OpenSession(openReq);
TSessionHandle sessHandle = openResp.getSessionHandle();
TExecuteStatementReq execReq = new TExecuteStatementReq(sessHandle, "show databases");
TExecuteStatementResp execResp = client.ExecuteStatement(execReq);
TOperationHandle stmtHandle = execResp.getOperationHandle();
TFetchResultsReq fetchReq = new TFetchResultsReq(stmtHandle, TFetchOrientation.FETCH_FIRST, 100);
TFetchResultsResp resultsResp = client.FetchResults(fetchReq);
List<TColumn> res=resultsResp.getResults().getColumns();
for(TColumn tCol: res){
Iterator<String> it = tCol.getStringVal().getValuesIterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
TCloseOperationReq closeReq = new TCloseOperationReq();
closeReq.setOperationHandle(stmtHandle);
client.CloseOperation(closeReq);
TCloseSessionReq closeConnectionReq = new TCloseSessionReq(sessHandle);
client.CloseSession(closeConnectionReq);
transport.close();通过查看源代码我们发现, 注: 源码为hive1.1分支,其中hive-service工程即为hiveserver2的对应工程。 Thrift类主要在org.apache.hive.service.cli.thrift包下。
session&operation管理
graph LR
HiveServer2-->CLIService
CLIService-->SessionManager
SessionManager-->handleToSession
SessionManager-->OperationManager
OperationManager-->handleToOperationSessionManager
private final Map<SessionHandle, HiveSession> handleToSession =
new ConcurrentHashMap<SessionHandle, HiveSession>();
private final OperationManager operationManager = new OperationManager();OperationManager
private final Map<OperationHandle, Operation> handleToOperation =
new HashMap<OperationHandle, Operation>();CLIService.cancelOperation
@Override
public void cancelOperation(OperationHandle opHandle)
throws HiveSQLException {
sessionManager.getOperationManager().getOperation(opHandle)
.getParentSession().cancelOperation(opHandle);
LOG.debug(opHandle + ": cancelOperation()");
}通过上述接口可知,只需要找到对应操作的OperationHandle, 然后调用CLIService.cancelOperation即可。
operation&handler
graph LR
SQLOperation-->ExecuteStatementOperation
ExecuteStatementOperation-->Operation
OperationHandle-->Handlepublic abstract class Handle {
private final HandleIdentifier handleId;
public Handle() {
handleId = new HandleIdentifier();
}
public Handle(HandleIdentifier handleId) {
this.handleId = handleId;
}
public Handle(THandleIdentifier tHandleIdentifier) {
this.handleId = new HandleIdentifier(tHandleIdentifier);
}
public HandleIdentifier getHandleIdentifier() {
return handleId;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((handleId == null) ? 0 : handleId.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (obj == null) {
return false;
}
if (!(obj instanceof Handle)) {
return false;
}
Handle other = (Handle) obj;
if (handleId == null) {
if (other.handleId != null) {
return false;
}
} else if (!handleId.equals(other.handleId)) {
return false;
}
return true;
}
@Override
public abstract String toString();
}可以通过handle id 进行查找。 需要通过thrift接口放出根据handle id停止operation的接口。
// CancelOperation()
//
// Cancels processing on the specified operation handle and
// frees any resources which were allocated.
struct TCancelOperationReq {
// Operation to cancel
1: required TOperationHandle op_handle
}thrift cancle接口已有; 现在需要thrift的获取所有operation的接口;用于展示 现在需要thrift的获取所有session的接口;用于展示
cli程序没有通信模块,如果增加通信模块修改较大,选择定位进程并对进程发送中断信号的方式取消查询。
通过修改配置,将查询log根据进程号进行细分,这样就可以获得查询和进程号的关系。
当想要杀死一个进程是,通过ssh给对应主机的指定进程发送中断信息即可。不能通过发送中断信号来执行,因为执行查询的用户可能有很多,==只有root才能保证中断发送成功==, 但是使用root权限会有安全问题,所有此处只能采用rpc方式进行。
具体rpc方案目前可选的为hadoop rpc形式或者thrift方式,轮询心跳方式或者cs合集模式。
暂定轮询心跳方式,IPC定时查询命令,心跳间隔1分钟。
工作量: 4-8工作日
因为cli方案的问题,所以最佳方案可能还是修改driver层。
日志格式
hive-hadoop-hive-T-162.log.2621@T-162
hive-hadoop-hive-T-162.log.28632@T-162
hive-hadoop-hive-T-162.log.362@T-162
hive-hadoop-hive-T-162.log.5762@T-162增加thrift的获取所有operation的接口,展示所有查询;调用取消查询接口杀死查询。
工作量:4-8工作日
因为不管cli还是thrift方式,最终都要经过driver层,所以在driver层修改,可以一站式解决所有问题。 但和上面两种不同的是,上面两种都只是在原有代码上加了一层壳,基本没有动核心代码; 而driver层,则需要改动一定程度逻辑的代码,难度有所增加。
看完上述内容,你们掌握HIVE作业管理分析及解决方案是什么的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3078255/blog/893455



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



