这期内容当中小编将会给大家带来有关如何理解R语言聚类算法中的k中心聚类,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
1.原理解析:
针对K-均值算法易受极值影响这一缺点的改进算法.在原理上的差异在于选择个类别中心点时不取样本均值点,而在类别内选取到其余样本距离之和最小的样本为中心。
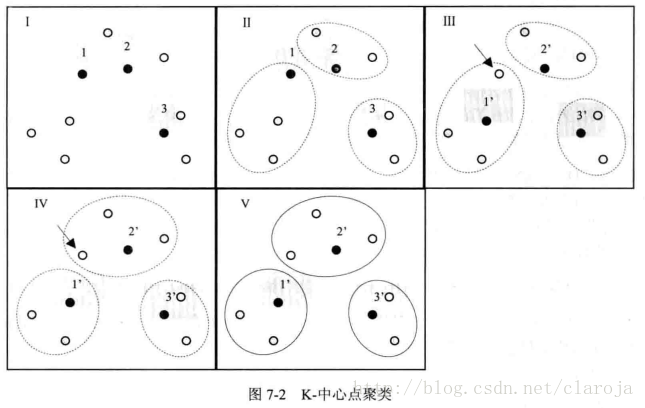
2.在R语言中的应用
k中心聚类(K-medoids)主要运用到了R语言中cluster包(R语言内置包)中的pam函数。
pam(x,k,diss=inherits(x,”dist”),metric=”euclidean”,medoids=NULL,stand=FALSE,cluster.only=FALSE,do.swap=TRUE,keep.diss=!diss&&!cluster.only&&n<100,keep.data=!diss&&!cluster.only,pamonce=FALSE,trace.lev=0)
3.以iris数据集为例进行线性判别分析
1)应用模型并查看模型的相应参数
fit_pam=pam(iris[,-5],3)
fit_pam[1:length(fit_pam)]

上述就是小编为大家分享的如何理解R语言聚类算法中的k中心聚类了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





