Hyperledger Fabric推荐Kafa用于生产环境。Kafa是一个分布式、具有水平伸缩能力、崩溃容错能力的日志系统。在Hyperledger Fabric区块链中可以有多个Kafka节点,使用zookeeper进行同步管理。本文将介绍Kfaka的基本工作原理,以及在HyperledgerFabric中使用Kafka和zookeeper实现共识的原理,并通过一个实例剖析Hyperledger Farbic中Kafka共识的达成过程。
如果希望快速掌握Fabric区块链的链码及应用开发,建议访问汇智网的在线互动课程:
- Fabric区块链Java开发详解
- Fabric区块链NodeJs开发详解
Kafka本质上是一个消息处理系统,它使用的是经典的发布-订阅模型。消息的消费者订阅特定的主题,以便收到新消息的通知,生产者则负责消息的发布。
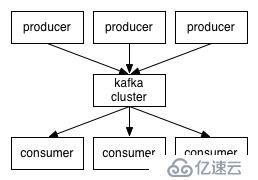
当主题的数据规模变得越来越大时,可以拆分为多个分区,Kafka保障在一个分区内的消息是按顺序排列的。
Kafka并不跟踪消费者读取了哪些消息,也不会自动删除已经读取的消息。Kafka会保存消息一段时间,例如一天,或者直到数据规模超过一定的阈值。消费者需要轮询新的消息,这是的他们可以根据自己的需求来定位消息,因此可以重放或重新处理事件。消费者处于不同的消费者分组,对应一个或多个消费者进程。每个分区被分贝给单一的消费者进程,因此同样的消息不会被多次读取。
崩溃容错机制是通过在多个Kafka代理之间复制分区来实现的。因此如果一个代理由于软件或硬件故障挂掉,数据也不会丢失。当然接下来还需要一个领导-跟随机制,领导者持有分区,跟随者则进行分区的复制。当领导者挂掉后,会有某个跟随者转变为新的领导者。
如果一个消费者订阅了某个主体,那么它怎么知道从哪个分区领导者来读取订阅的消息?
答案在于zookeeper服务。
zookeeper是一个分布式key-value存储库,通常用于存储元数据及集群机制的实现。zookeeper允许服务(Kafka代理)的客户端订阅变化并获得实时通知。这就是代理如何确定应当使用哪个分区领导者的原因。zookeeper有超强的故障容错能力,因此Kafka的运行严重依赖于它。
在zookeeper中存储的元数据包括:
要理解在超级账本Hyperledger Fabric中的Kafka是如何工作的,首先需要理解几个重要的术语:
注意,虽然在Hyperledger Fabric中Kafka被称为共识(Consensus),但是其核心是交易排序服务以及额外的崩溃容错能力。
在Hyperledger Fabric中的Kafka实际运行逻辑如下:
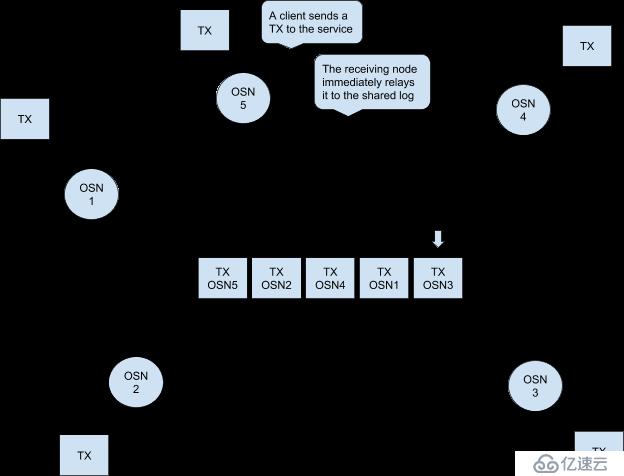
考虑下图,假设排序节点OSN0和OSN2时连接到广播客户端,OSN1连接到分发客户端。
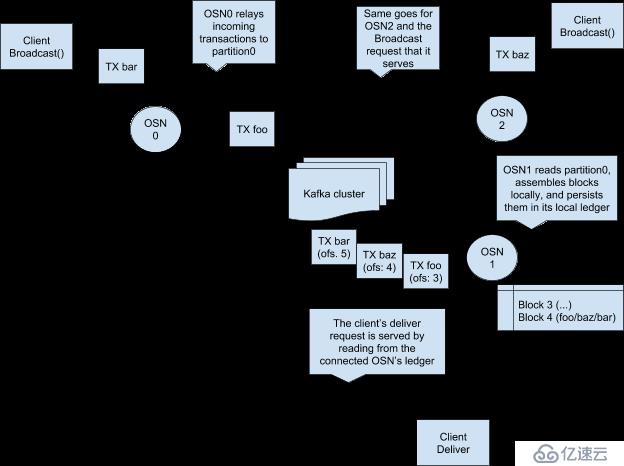
Kakfa的高性能对于Hyperledger Fabric有很大的帮助,多个排序节点通过Kafka实现同步,而Kafka本身并不是排序节点,它只是将排序节点通过流连接起来。虽然Kafka支持崩溃容错,它并不能提供对网络中恶意***的保护。需要一种拜占庭容错方案(BFT)才可以对抗恶意的***,但是目前在Farbic框架中还有待实现这一机制。
总而言之,在Hyperledger Farbic中,Kafka共识模块是可以用于生产环境的,它可以支持崩溃容错,但无法对抗恶意***。
原文:The ABCs of Kafka in Hyperledger Fabric
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





