本篇内容介绍了“怎么在Kubernetes集群中利用GPU进行AI训练”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
截止Kubernetes 1.8版本:
对GPU的支持还只是实验阶段,仍停留在Alpha特性,意味着还不建议在生产环境中使用Kubernetes管理和调度GPU资源。
只支持NVIDIA GPUs。
Pods不能共用同一块GPU,即使同一个Pod内不同的Containers之间也不能共用同一块GPU。这是Kubernetes目前对GPU支持最难以接受的一点。因为一块PU价格是很昂贵的,一个训练进程通常是无法完全利用满一块GPU的,这势必会造成GPU资源的浪费。
每个Container请求的GPU数要么为0,要么为正整数,不允许为为分数,也就是说不支持只请求部分GPU。
无视不同型号的GPU计算能力,如果你需要考虑这个,那么可以考虑使用NodeAffinity来干扰调度过程。
只支持docker作为container runtime,才能使用GPU,如果你使用rkt等,那么你可能还要再等等了。
目前,Kubernetes主要负责GPU资源的检测和调度,真正跟NVIDIA Driver通信的还是docker,因此整个逻辑结构图如下:
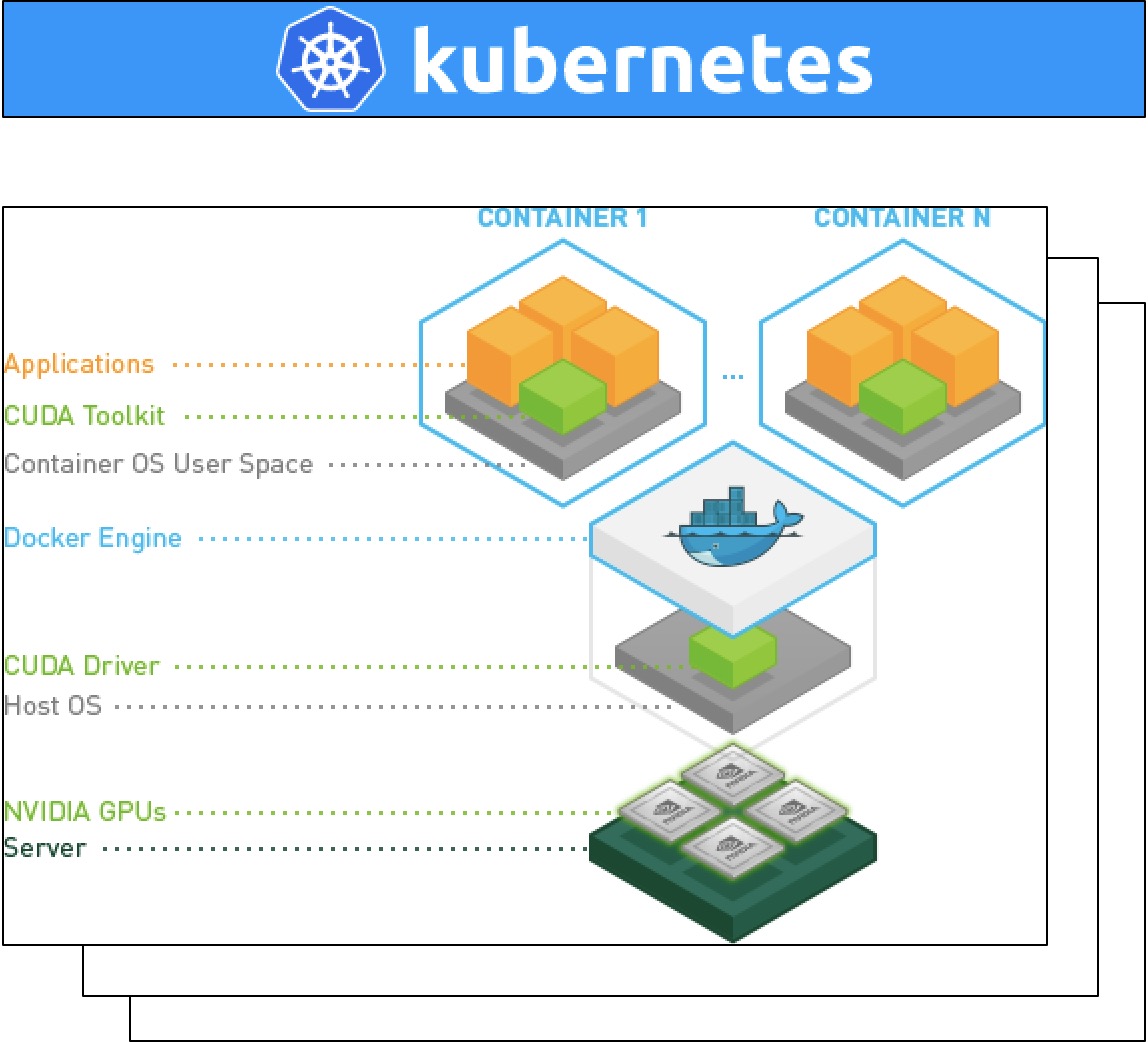
请确认Kubernetes集群中的GPU服务器已经安装和加载了NVIDIA Drivers,可以使用nvidia-docker-plugin来确认是否已加载Drivers。
如何安装,请参考nvidia-docker 2.0 installation。
如何确定NVIDIA Drivers Ready呢?执行命令 kubectl get node $GPU_Node_Name -o yaml查看该Node的信息,如果看到.status.capacity.alpha.kubernetes.io/nvidia-gpu: $Gpu_num,则说明kubelet已经成功通过driver识别到了本地的GPU资源。
请确认kube-apiserver, kube-controller-manager, kube-scheduler, kubelet, kube-proxy每个组件的--feature-gatesflag中都包含Accelerators=true(虽然实际上不是每个组件都需要配置这一项,比如kube-proxy)
注意在BIOS里面检查你的UEFI是否开启,如果开启的话请立马关掉它,否则nvidia驱动可能会安装失败。
如果你使用的是Kubernetes 1.8,那么也可以利用kubernetes device plugin这一Alpha特性,让第三方device plugin发现和上报资源信息给kubelet,Nividia有对应的plugin,请参考nvidia k8s-device-plugin。nvidia k8s-device-plugin通过DaemonSet方式部署到GPUs Server中,下面是其yaml描述文件内容:
apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: nvidia-device-plugin-daemonset spec: template: metadata: labels: name: nvidia-device-plugin-ds spec: containers: - image: nvidia-device-plugin:1.0.0 name: nvidia-device-plugin-ctr imagePullPolicy: Never env: - name: NVIDIA_VISIBLE_DEVICES value: ALL - name: NVIDIA_DRIVER_CAPABILITIES value: utility,compute volumeMounts: - name: device-plugin mountPath: /var/lib/kubelet/device-plugins volumes: - name: device-plugin hostPath: path: /var/lib/kubelet/device-plugins
关于Kubernetes Device Plugin,后面有机会我再单独写一篇博文来深入分析。
不同于cpu和memory,你必须强制显式申明你打算使用的GPU number,通过在container的resources.limits中设置alpha.kubernetes.io/nvidia-gpu为你想要使用的GPU数,通过设置为1就已经足够了,应该没多少训练场景一个worker需要独占几块GPU的。
kind: Pod apiVersion: v1 metadata: name: gpu-pod spec: containers: - name: gpu-container-1 image: gcr.io/google_containers/pause:2.0 resources: limits: alpha.kubernetes.io/nvidia-gpu: 1 volumeMounts: - mountPath: /usr/local/nvidia name: nvidia volumes: - hostPath: path: /var/lib/nvidia-docker/volumes/nvidia_driver/384.98 name: nvidia
注意,需要将主机上的nvidia_driver通过hostpath挂载到容器内的/usr/local/nvidia
有些同学或许已经有疑问了:为啥没看到设置resources.requests,直接设置resources.limits?
熟悉Kubernetes中LimitRanger和Resource QoS的同学应该就发现了,这种对GPU resources的设置是属于QoS为Guaranteed,也就是说:
你可以只显式设置limits,不设置requests,那么requests其实就等于limits。
你可以同时显示设置limits和requests,但两者必须值相等。
你不能只显示设置requests,而不设置limits,这种情况属于Burstable。
注意,在Kubernetes 1.8.0 Release版本中,存在一个bug:设置GPU requests小于limits是允许的,具体issue可以参考Issue 1450,代码已经合并到v1.8.0-alpha.3中,请使用时注意。下面是对应的修改代码。
pkg/api/v1/validation/validation.go
func ValidateResourceRequirements(requirements *v1.ResourceRequirements, fldPath *field.Path) field.ErrorList {
...
// Check that request <= limit.
limitQuantity, exists := requirements.Limits[resourceName]
if exists {
// For GPUs, not only requests can't exceed limits, they also can't be lower, i.e. must be equal.
if quantity.Cmp(limitQuantity) != 0 && !v1helper.IsOvercommitAllowed(resourceName) {
allErrs = append(allErrs, field.Invalid(reqPath, quantity.String(), fmt.Sprintf("must be equal to %s limit", resourceName)))
} else if quantity.Cmp(limitQuantity) > 0 {
allErrs = append(allErrs, field.Invalid(reqPath, quantity.String(), fmt.Sprintf("must be less than or equal to %s limit", resourceName)))
}
} else if resourceName == v1.ResourceNvidiaGPU {
allErrs = append(allErrs, field.Invalid(reqPath, quantity.String(), fmt.Sprintf("must be equal to %s request", v1.ResourceNvidiaGPU)))
}
}
return allErrs
}关于Kubernetes Resource QoS的更多知识,请参考我的另一篇博文:Kubernetes Resource QoS机制解读。
前面提到,Kubernetes默认不支持GPU硬件的区别和差异化调度,如果你需要这种效果,可以通过NodeAffinity来实现,或者使用NodeSelector来实现(不过,NodeAffinity能实现NodeSelector,并且强大的多,NodeSelector应该很快会Deprecated。)
首先,给GPU服务器打上对应的Label,你有两种方式:
在kubelet启动flag中添加--node-labels='alpha.kubernetes.io/nvidia-gpu-name=$NVIDIA_GPU_NAME',当然alpha.kubernetes.io/nvidia-gpu-name你可以换成其他你自定义的key,但要注意可读性。这种方式,需要重启kubelet才能生效,属于静态方式。
通过rest client修改对应的Node信息,加上对应的Label。比如执行kubectl label node $GPU_Node_Name alpha.kubernetes.io/nvidia-gpu-name=$NVIDIA_GPU_NAME,这是实时生效的,可随时增加删除,属于动态方式。
然后,在需要使用指定GPU硬件的Pod Spec中添加对应的NodeAffinity Type为requiredDuringSchedulingIgnoredDuringExecution的相关内容,参考如下:
kind: pod
apiVersion: v1
metadata:
annotations:
scheduler.alpha.kubernetes.io/affinity: >
{
"nodeAffinity": {
"requiredDuringSchedulingIgnoredDuringExecution": {
"nodeSelectorTerms": [
{
"matchExpressions": [
{
"key": "alpha.kubernetes.io/nvidia-gpu-name",
"operator": "In",
"values": ["Tesla K80", "Tesla P100"]
}
]
}
]
}
}
}
spec:
containers:
- name: gpu-container-1
resources:
limits:
alpha.kubernetes.io/nvidia-gpu: 1
volumeMounts:
- mountPath: /usr/local/nvidia
name: nvidia
volumes:
- hostPath:
path: /var/lib/nvidia-docker/volumes/nvidia_driver/384.98
name: nvidia其中Tesla K80, Tesla P100都是NVIDIA GPU的型号。
通常,CUDA Libs安装在GPU服务器上,那么使用GPU的Pod可以通过volume type为hostpath的方式使用CUDA Libs。
kind: Pod apiVersion: v1 metadata: name: gpu-pod spec: containers: - name: gpu-container-1 image: gcr.io/google_containers/pause:2.0 resources: limits: alpha.kubernetes.io/nvidia-gpu: 1 volumeMounts: - mountPath: /usr/local/nvidia name: nvidia volumes: - hostPath: path: /var/lib/nvidia-docker/volumes/nvidia_driver/384.98 name: nvidia
参考如何落地TensorFlow on Kubernetes将TensorFlow跑在Kubernetes集群中,并且能创建Distributed TensorFlow集群启动训练。

不同的是,在worker对应的Job yaml中按照上面的介绍:
将docker image换成tensorflow:1.3.0-gpu;
给container加上GPU resources limits, 去掉cpu和memory的相关resources requests设置;
并挂载对应的CUDA libs,然后在训练脚本中就能使用/device:GPU:1, /device:GPU:2, ...进行加速训练了。
“怎么在Kubernetes集群中利用GPU进行AI训练”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





