这期内容当中小编将会给大家带来有关基于CNN的中文文本分类算法是怎样的,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
文本分类任务是一个经久不衰的课题,其应用包括垃圾邮件检测、情感分析等。
传统机器学习的做法是先进行特征工程,构建出特征向量后,再将特征向量输入各种分类模型(贝叶斯、SVM、神经网络等)进行分类。
随着深度学习的发展以及RNN、CNN的陆续出现,特征向量的构建将会由网络自动完成,因此我们只要将文本的向量表示输入到网络中就能够完成自动完成特征的构建与分类过程。
就分类任务而言,CNN比RNN更为合适。CNN目前在图像处理方向应用最为广泛,在文本处理上也有一些的应用。
下面来设计一个简单的CNN,并将其应用于中文垃圾邮件检测任务。
1.1神经网络基础知识
如果你对深度学习或RNN、CNN等神经网络并不太熟悉,请先移步至这里
http://www.wildml.com/
寻找相关文章进行精读,这个博主写的每一篇文章都很好,由浅至深,非常适合入门。
1.2如何将CNN运用到文本处理
参考understanding-convolutional-neural-networks-for-nlp
http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
1.3CNN网络结构和实现方法(必读)
此博文中的CNN网络结构和实现方法绝大部分是参考了 IMPLEMENTING A CNN FOR TEXT CLASSIFICATION IN TENSORFLOW 这篇文章的,CNN的结构和实现细节在这篇文章均有详述。
2 训练数据
2.1 中文垃圾邮件数据集
说明:对TREC06C进行了简单的清洗得到,以utf-8格式存储
完整代码 数据集下载地址:
1、转发本文至朋友圈
2、关注微信公众号 datayx 然后回复 文本分类 即可获取。
2.2垃圾邮件
spam_5000.utf8

3 预处理
3.1输入
上述两个文件 ( spam_5000.utf8 ham_5000.utf8)
embedding_dim (word embedding的维度, 即用多少维度的向量来表示一个单词)
3.2 输出:
max_document_length (最长的邮件所包含的单词个数)
x (所有邮件的向量表示, 维度为[所有邮件个数,max_doument_length, embedding_dim])
y (所有邮件对应的标签,[0, 1]表示正常邮件,[1, 0]表示垃圾邮件,y的维度为[所有邮件个数, 2])
3.3 主要流程:
3.3.1 过滤字符
为了分词的方便,示例程序中去除了所有的非中文字符,你也可以选择保留标点符号,英文字符,数字等其他字符,但要在分词时进行一定的特殊处理
3.3.2 分词
为了训练Word2Vec 模型,需要先对训练文本进行分词。这里为了方便起见,直接对每个中文字符进行分隔,即最后训练处的word2vec 的向量是对字的embedding, 效果也比较不错
3.3.3 对齐
为了加快网络的训练过程,需要进行批量计算,因此输入的训练样本需要进行对齐(padding)操作,使得其维度一致。这里的对齐就是把所有的邮件长度增加到max_document_length (最长的邮件所包含的单词个数),空白的位置用一个指定单词进行填充(示例程序中用的填充单词为”PADDING”)
3.3.4 训练word2vec
在对文本进行分词和对齐后,就可以训练处word2vec模型了,具体的训练过程不在此阐述,程序可以参考项目文件中的word2vec_helpers.py。
4 定义CNN网络与训练步骤
4.1 网络结构
此博文中的CNN网络结构和实现方法绝大部分是参考了 IMPLEMENTING A CNN FOR TEXT CLASSIFICATION IN TENSORFLOW 这篇文章的,CNN的结构和实现细节在这篇文章均有详述。重复的地方不再说明,主要说说不同的地方。
那篇文章中实现的CNN是用于英文文本二分类的,并且在卷积之前,有一层embedding层,用于得到文本的向量表示。
而本博文中实现的CNN在上面的基础上略有修改,用于支持中文文本的分类。CNN的结构的唯一变化是去掉了其中的embedding层,改为直接将word2vec预训练出的embedding向量输入到网络中进行分类。
网络结构图如下图所示:
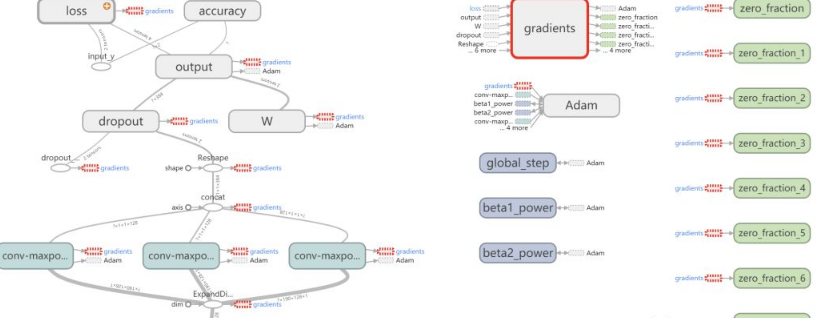
4.2 训练步骤
在预处理阶段得到了x和y, 接下来将x 和 y 按照一定比例分成训练集train_x, train_y和测试集dev_x, dev_y。
接着按照batch_size分批将train_x输入至网络TextCNN中进行训练,经过三个卷积层的卷积和max-pool之后,合并得到一个向量,这个向量代表了各个卷积层学到的关于训练数据的某些特征,最后将这个向量输入到一个单层的神经网络并用softmax分类,得到最终的分类结果,计算损失(交叉熵)并开始后向传播,执行批量梯度下降来更新网络参数。
5 结果
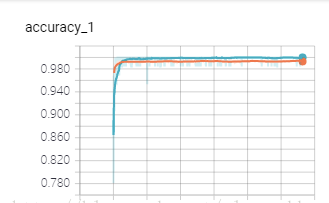
准确率:
误差:
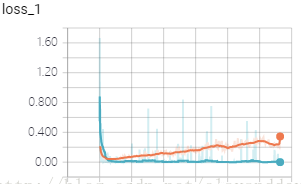
因为数据集并没有标准的训练集和测试集,本文只是按照0.1的比例进行了简单的分割,且并没有对一些重复的文档进行筛选,所以准确率能够达到99%左右。如果用比较标准的数据集,并加入交叉验证等方法,相信准确率会降低一些,但相信准确率仍能够超过绝大部分用传统机器学习的方法写出的分类器。
上述就是小编为大家分享的基于CNN的中文文本分类算法是怎样的了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4585416/blog/4622053



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



