这篇文章主要讲解了“Kubernetes Scheduler的优先级队列是什么”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Kubernetes Scheduler的优先级队列是什么”吧!
从Kubernetes 1.8开始,Scheduler提供了基于Pod Priorty的抢占式调度,我在解析Kubernetes 1.8中的基于Pod优先级的抢占式调度和Kubernetes 1.8抢占式调度Preemption源码分析中对此做过深入分析。但这还不够,当时调度队列只有FIFO类型,并不支持优先级队列,这会导致High Priority Pod抢占Lower Priority Pod后再次进入FIFO队列中排队,经常会导致抢占的资源被队列前面的Lower Priority Pod占用,导致High Priority Pod Starvation的问题。为了减轻这一问题,从Kubernetes 1.9开始提供Pod优先级的调度队列,即PriorityQueue,这同样需要用户打开PodPriority这个Feature Gate。
先看看PriorityQueue的结构定义。
type PriorityQueue struct {
lock sync.RWMutex
cond sync.Cond
activeQ *Heap
unschedulableQ *UnschedulablePodsMap
nominatedPods map[string][]*v1.Pod
receivedMoveRequest bool
}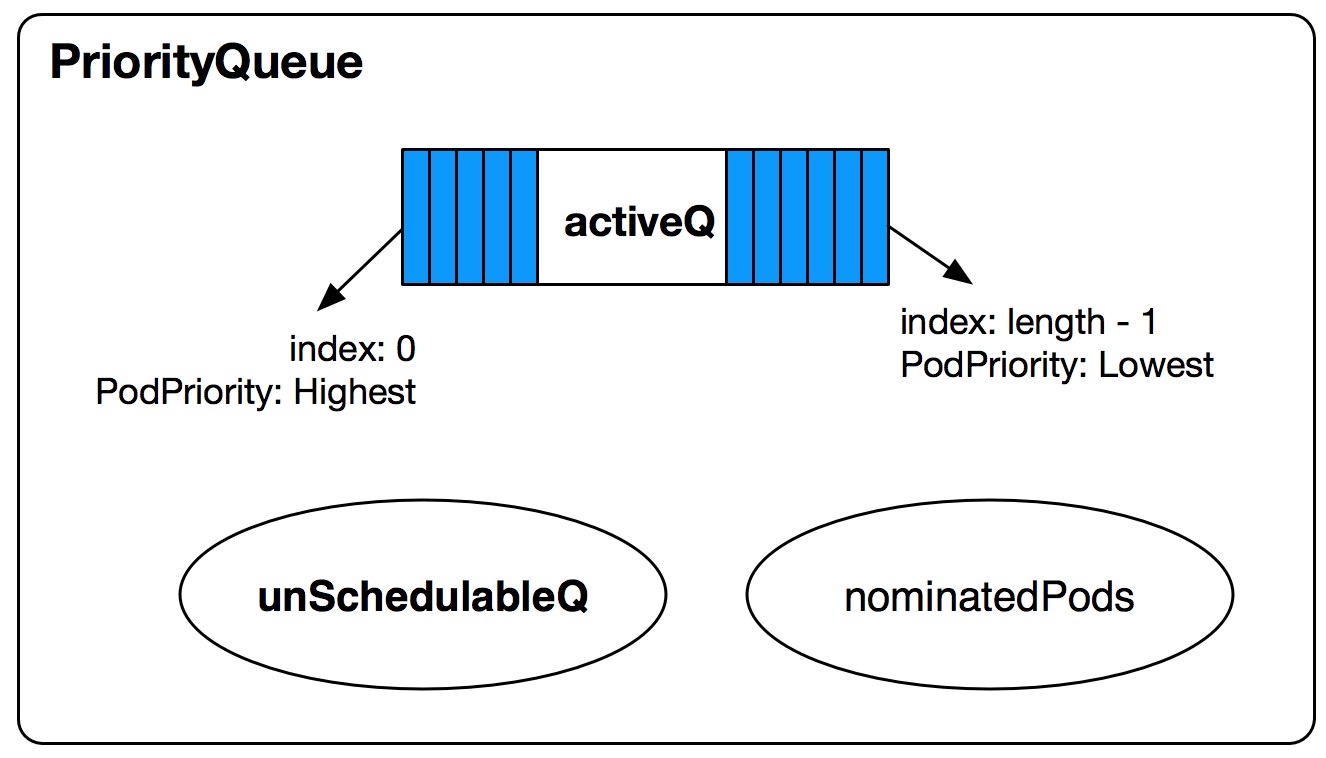
activeQ:PriorityQueue的Sub-Queue之一,是一个有序的Heap结构,按照Pod优先级从高到低递减的顺序存放待调度的Pending Pod相关信息,优先级最高的Pod信息在最上面,Pop Heap时将得到最高优先级的Pod信息。
unschedulableQ:PriorityQueue的Sub-Queue之一,主要是是一个无序的Map,key为pod.Name + "_" + pod.Namespace,value为那些已经尝试调度并且调度失败的UnSchedulable的Pod Object。
nominatedPods:为Map结构,key为node name,value为该Node上Nominated Pod Objects。当发生抢占调度时,preemptor pods会打上NominatedNodeName Annotation,表示经过抢占调度的逻辑后,该Pod希望能调度到NominatedNodeName这个Node上,调度时会考虑这个,防止高优先级的Pods进行抢占调度释放了低优先级Pods到它被再次调度这个时间段内,抢占的资源又被低优先级的Pods占用了。关于scheduler怎么处理Nominated Pods,我后续会单独写篇博客来分析。
receivedMoveRequest:当scheduler将Pods从unschedulableQ移到activeQ时,这个值设为true。当scheduler从activeQ中Pop一个Pods时,这个值设为false。这表示当scheduler要调度某个Pod时是否接受到Move请求。当调度发生Error时,会尝试将UnSchedulable Pod重新加入到调度队列(unSchedulableQ or activeQ)中,这时只有当receivedMoveRequest为false并且该Pod Condition Status为False或者Unschedulable时,才会将该Pod Add到unschedulableQ(或者Update it)。
active是真正实现优先级调度的Heap,我们继续看看这个Heap的实现。
type Heap struct {
data *heapData
}
type heapData struct {
items map[string]*heapItem
queue []string
keyFunc KeyFunc
lessFunc LessFunc
}
type heapItem struct {
obj interface{} // The object which is stored in the heap.
index int // The index of the object's key in the Heap.queue.
}heapData是activeQ中真正用来存放items的结构:
items:Map结构,key为Heap中对象的key,通过下面的keyFunc生成,value为heapItem对象,heapItem包括真正的Pod Object及其在Heap中的index。
queue:string array,顺序存放Pod对应的key,按照优先级从高到低的顺序对应index从0到高。
keyFunc:根据Pod Object生成对应的key的Function,格式为"meta.GetNamespace() + "/" + meta.GetName"。
lessFunc:用来根据Pod优先级比较Heap中的Pod Object(然后决定其在Heap中的index,index为0的Pod优先级最高,随着index递增,Pod优先级递减)。
在scheduler config factory创建时,会注册podQueue的创建Func为NewSchedulingQueue。NewSchedulingQueue会检查PodPriority Feature Gate是否enable(截止Kubernetes 1.10版本,默认disable),如果PodPriority enable,则会invoke NewPriorityQueue创建PriorityQueue来管理未调度的Pods。如果PodPriority disable,则使用大家熟悉的FIFO Queue。
func NewSchedulingQueue() SchedulingQueue {
if util.PodPriorityEnabled() {
return NewPriorityQueue()
}
return NewFIFO()
}NewPriorityQueue初始化优先级队列代码如下。
// NewPriorityQueue creates a PriorityQueue object.
func NewPriorityQueue() *PriorityQueue {
pq := &PriorityQueue{
activeQ: newHeap(cache.MetaNamespaceKeyFunc, util.HigherPriorityPod),
unschedulableQ: newUnschedulablePodsMap(),
nominatedPods: map[string][]*v1.Pod{},
}
pq.cond.L = &pq.lock
return pq
}主要初始化activeQ、unschedulableQ、nominatedPods。
newHeap初始化activeQ时,注册heapData对应的keyFunc和lessFunc。
unschedulableQ初始化时,注册keyFunc。
newHeap构建activeQ的时候,传入两个参数,第一个就是keyFunc: MetaNamespaceKeyFunc。
func MetaNamespaceKeyFunc(obj interface{}) (string, error) {
if key, ok := obj.(ExplicitKey); ok {
return string(key), nil
}
meta, err := meta.Accessor(obj)
if err != nil {
return "", fmt.Errorf("object has no meta: %v", err)
}
if len(meta.GetNamespace()) > 0 {
return meta.GetNamespace() + "/" + meta.GetName(), nil
}
return meta.GetName(), nil
}MetaNamespaceKeyFunc根据Pod Object生成对应的key的Function,格式为"meta.GetNamespace() + "/" + meta.GetName"。
newHeap传入的第二个参数是lessFunc:HigherPriorityPod。
const (
DefaultPriorityWhenNoDefaultClassExists = 0
)
func HigherPriorityPod(pod1, pod2 interface{}) bool {
return GetPodPriority(pod1.(*v1.Pod)) > GetPodPriority(pod2.(*v1.Pod))
}
func GetPodPriority(pod *v1.Pod) int32 {
if pod.Spec.Priority != nil {
return *pod.Spec.Priority
}
return scheduling.DefaultPriorityWhenNoDefaultClassExists
}HigherPriorityPod用来根据Pod优先级比较Heap中的Pod Object,然后决定其在Heap中的index。
index为0的Pod优先级最高,随着index递增,Pod优先级递减。
注意:如果pod.Spec.Priority为nil(意味着这个Pod在创建时集群里还没有对应的global default PriorityClass Object),并不是去把现在global default PriorityClass中的值设置给这个Pod.Spec.Priority,而是设置为0。个人觉得,设置为默认值比较合理。
unschedulableQ的构建是通过调用newUnschedulablePodsMap完成的,里面进行了UnschedulablePodsMap的pods的初始化,以及pods map中keyFunc的注册。
func newUnschedulablePodsMap() *UnschedulablePodsMap {
return &UnschedulablePodsMap{
pods: make(map[string]*v1.Pod),
keyFunc: util.GetPodFullName,
}
}
func GetPodFullName(pod *v1.Pod) string {
return pod.Name + "_" + pod.Namespace
}注意:unschedulableQ中keyFunc实现的key生成规则是
pod.Name + "_" + pod.Namespace,不同于activeQ中keyFunc(格式为"meta.GetNamespace() + "/" + meta.GetName")。我也不理解为何要搞成两种不同的格式,统一按照activeQ中的keyFunc就很好。
前面了解了PriorityQueue的结构,接着我们就要思考怎么往优先级Heap(activeQ)中添加对象了。
func (h *Heap) Add(obj interface{}) error {
key, err := h.data.keyFunc(obj)
if err != nil {
return cache.KeyError{Obj: obj, Err: err}
}
if _, exists := h.data.items[key]; exists {
h.data.items[key].obj = obj
heap.Fix(h.data, h.data.items[key].index)
} else {
heap.Push(h.data, &itemKeyValue{key, obj})
}
return nil
}
func Push(h Interface, x interface{}) {
h.Push(x)
up(h, h.Len()-1)
}
func up(h Interface, j int) {
for {
i := (j - 1) / 2 // parent
if i == j || !h.Less(j, i) {
break
}
h.Swap(i, j)
j = i
}
}
func (h *heapData) Less(i, j int) bool {
if i > len(h.queue) || j > len(h.queue) {
return false
}
itemi, ok := h.items[h.queue[i]]
if !ok {
return false
}
itemj, ok := h.items[h.queue[j]]
if !ok {
return false
}
return h.lessFunc(itemi.obj, itemj.obj)
}往activeQ中添加Pod时,如果该Pod已经存在,则根据其PriorityClass Value更新它在heap中的index,否则把它Push入堆。
Push和Fix类似,都需要对该Pod在activeQ heap中进行重新排序。排序时,通过Less Func进行比较,Less Func最终就是invoke前面注册的activeQ中的lessFunc,即HigherPriorityPod。也就说Push和Fix时会根据Pod的优先级从高到低依次对应index从小到大。
使用PriorityQueue进行待调度Pod管理时,会从activeQ中Pop一个Pod出来,这个Pod是heap中的第一个Pod,也是优先级最高的Pod。
func (h *Heap) Pop() (interface{}, error) {
obj := heap.Pop(h.data)
if obj != nil {
return obj, nil
}
return nil, fmt.Errorf("object was removed from heap data")
}
func Pop(h Interface) interface{} {
n := h.Len() - 1
h.Swap(0, n)
down(h, 0, n)
return h.Pop()
}
func down(h Interface, i, n int) {
for {
j1 := 2*i + 1
if j1 >= n || j1 < 0 { // j1 < 0 after int overflow
break
}
j := j1 // left child
if j2 := j1 + 1; j2 < n && !h.Less(j1, j2) {
j = j2 // = 2*i + 2 // right child
}
if !h.Less(j, i) {
break
}
h.Swap(i, j)
i = j
}
}从activeQ heap中Pop一个Pod出来时,最终也是通过Less Func进行比较(即HigherPriorityPod)找出最高优先级的Pod。
了解了PriorityQueue及Pod进出Heap的原理之后,我们回到Scheduler Config Factory,看看Scheduler中podInformer、nodeInformer、serviceInformer、pvcInformer等注册的EventHandler中对PriorityQueue的操作。
func NewConfigFactory(...) scheduler.Configurator {
...
// scheduled pod cache
podInformer.Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
return assignedNonTerminatedPod(t)
case cache.DeletedFinalStateUnknown:
if pod, ok := t.Obj.(*v1.Pod); ok {
return assignedNonTerminatedPod(pod)
}
runtime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, c))
return false
default:
runtime.HandleError(fmt.Errorf("unable to handle object in %T: %T", c, obj))
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: c.addPodToCache,
UpdateFunc: c.updatePodInCache,
DeleteFunc: c.deletePodFromCache,
},
},
)
// unscheduled pod queue
podInformer.Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
switch t := obj.(type) {
case *v1.Pod:
return unassignedNonTerminatedPod(t)
case cache.DeletedFinalStateUnknown:
if pod, ok := t.Obj.(*v1.Pod); ok {
return unassignedNonTerminatedPod(pod)
}
runtime.HandleError(fmt.Errorf("unable to convert object %T to *v1.Pod in %T", obj, c))
return false
default:
runtime.HandleError(fmt.Errorf("unable to handle object in %T: %T", c, obj))
return false
}
},
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: c.addPodToSchedulingQueue,
UpdateFunc: c.updatePodInSchedulingQueue,
DeleteFunc: c.deletePodFromSchedulingQueue,
},
},
)
// ScheduledPodLister is something we provide to plug-in functions that
// they may need to call.
c.scheduledPodLister = assignedPodLister{podInformer.Lister()}
nodeInformer.Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: c.addNodeToCache,
UpdateFunc: c.updateNodeInCache,
DeleteFunc: c.deleteNodeFromCache,
},
)
c.nodeLister = nodeInformer.Lister()
...
// This is for MaxPDVolumeCountPredicate: add/delete PVC will affect counts of PV when it is bound.
pvcInformer.Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: c.onPvcAdd,
UpdateFunc: c.onPvcUpdate,
DeleteFunc: c.onPvcDelete,
},
)
c.pVCLister = pvcInformer.Lister()
// This is for ServiceAffinity: affected by the selector of the service is updated.
// Also, if new service is added, equivalence cache will also become invalid since
// existing pods may be "captured" by this service and change this predicate result.
serviceInformer.Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: c.onServiceAdd,
UpdateFunc: c.onServiceUpdate,
DeleteFunc: c.onServiceDelete,
},
)
c.serviceLister = serviceInformer.Lister()
...
}通过assignedNonTerminatedPod FilterFunc过滤出那些已经Scheduled并且NonTerminated Pods,然后再对这些Pods的Add/Update/Delete Event Handler进行注册,这里我们只关注对PriorityQueue的操作。
// assignedNonTerminatedPod selects pods that are assigned and non-terminal (scheduled and running).
func assignedNonTerminatedPod(pod *v1.Pod) bool {
if len(pod.Spec.NodeName) == 0 {
return false
}
if pod.Status.Phase == v1.PodSucceeded || pod.Status.Phase == v1.PodFailed {
return false
}
return true
}注册Add assignedNonTerminatedPod Event Handler为addPodToCache。
func (c *configFactory) addPodToCache(obj interface{}) {
...
c.podQueue.AssignedPodAdded(pod)
}
// AssignedPodAdded is called when a bound pod is added. Creation of this pod
// may make pending pods with matching affinity terms schedulable.
func (p *PriorityQueue) AssignedPodAdded(pod *v1.Pod) {
p.movePodsToActiveQueue(p.getUnschedulablePodsWithMatchingAffinityTerm(pod))
}
func (p *PriorityQueue) movePodsToActiveQueue(pods []*v1.Pod) {
p.lock.Lock()
defer p.lock.Unlock()
for _, pod := range pods {
if err := p.activeQ.Add(pod); err == nil {
p.unschedulableQ.delete(pod)
} else {
glog.Errorf("Error adding pod %v to the scheduling queue: %v", pod.Name, err)
}
}
p.receivedMoveRequest = true
p.cond.Broadcast()
}
// getUnschedulablePodsWithMatchingAffinityTerm returns unschedulable pods which have
// any affinity term that matches "pod".
func (p *PriorityQueue) getUnschedulablePodsWithMatchingAffinityTerm(pod *v1.Pod) []*v1.Pod {
p.lock.RLock()
defer p.lock.RUnlock()
var podsToMove []*v1.Pod
for _, up := range p.unschedulableQ.pods {
affinity := up.Spec.Affinity
if affinity != nil && affinity.PodAffinity != nil {
terms := predicates.GetPodAffinityTerms(affinity.PodAffinity)
for _, term := range terms {
namespaces := priorityutil.GetNamespacesFromPodAffinityTerm(up, &term)
selector, err := metav1.LabelSelectorAsSelector(term.LabelSelector)
if err != nil {
glog.Errorf("Error getting label selectors for pod: %v.", up.Name)
}
if priorityutil.PodMatchesTermsNamespaceAndSelector(pod, namespaces, selector) {
podsToMove = append(podsToMove, up)
break
}
}
}
}
return podsToMove
}addPodToCache除了将pod加入到schedulerCache中之外,还会调用podQueue.AssignedPodAdded。
对于PriorityQueue而言,AssignedPodAdded负责unSchedulableQ中的pods进行与该pod的Pod Affinity检查,把那些满足Pod Affinity的pods从unSchedulableQ中移到activeQ中,待scheduler进行调度。
在这里要注意movePodsToActiveQueue中设置了receivedMoveRequest为true。
func (p *PriorityQueue) AddUnschedulableIfNotPresent(pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
if p.unschedulableQ.get(pod) != nil {
return fmt.Errorf("pod is already present in unschedulableQ")
}
if _, exists, _ := p.activeQ.Get(pod); exists {
return fmt.Errorf("pod is already present in the activeQ")
}
if !p.receivedMoveRequest && isPodUnschedulable(pod) {
p.unschedulableQ.addOrUpdate(pod)
p.addNominatedPodIfNeeded(pod)
return nil
}
err := p.activeQ.Add(pod)
if err == nil {
p.addNominatedPodIfNeeded(pod)
p.cond.Broadcast()
}
return err
}如果receivedMoveRequest为false并且该Pod Condition Status为False或者Unschedulable时,才会将该Pod Add/Update到unschedulableQ,否则加入到activeQ。
因此receivedMoveRequest设置错误可能会导致该pod本应该加入到unSchedulableQ中,却被加入到了activeQ中,这会导致scheduler多做一次无效的调度,当然这对性能的影响是很小的。
但是这里应该是有问题的,如果getUnschedulablePodsWithMatchingAffinityTerm得到的podsToMove数组为空时,并没有pods会真正从unSchedulableQ中移到activeQ中,此时MoveRequest是无效的,receivedMoveRequest仍然应该为false。
上面的receivedMoveRequest设置不对带来什么问题呢?当某个pod调度发生Error时会调用AddUnschedulableIfNotPresent将该pod加入到unSchedulableQ或者activeQ中。
注册Update assignedNonTerminatedPod Event Handler为updatePodInCache。
func (c *configFactory) updatePodInCache(oldObj, newObj interface{}) {
...
c.podQueue.AssignedPodUpdated(newPod)
}
// AssignedPodUpdated is called when a bound pod is updated. Change of labels
// may make pending pods with matching affinity terms schedulable.
func (p *PriorityQueue) AssignedPodUpdated(pod *v1.Pod) {
p.movePodsToActiveQueue(p.getUnschedulablePodsWithMatchingAffinityTerm(pod))
}updatePodInCache中对podQueue的操作是AssignedPodUpdated,其实现同AssignedPodAdded,不再多说。
注册Delete assignedNonTerminatedPod Event Handler为deletePodFromCache。
func (c *configFactory) deletePodFromCache(obj interface{}) {
...
c.podQueue.MoveAllToActiveQueue()
}
func (p *PriorityQueue) MoveAllToActiveQueue() {
p.lock.Lock()
defer p.lock.Unlock()
for _, pod := range p.unschedulableQ.pods {
if err := p.activeQ.Add(pod); err != nil {
glog.Errorf("Error adding pod %v to the scheduling queue: %v", pod.Name, err)
}
}
p.unschedulableQ.clear()
p.receivedMoveRequest = true
p.cond.Broadcast()
}当发生Delete assignedNonTerminatedPod Event时,会调用podQueue.MoveAllToActiveQueue将unSchedulableQ中的所有Pods移到activeQ中,unSchedulableQ也就被清空了。
如果集群中出现频繁删除pods的动作,会导致频繁将unSchedulableQ中的所有Pods移到activeQ中。如果unSchedulableQ中有个High Priority的Pod,那么就会导致频繁的抢占Lower Priority Pods的调度机会,使得Lower Priority Pod长期处于饥饿状态。关于这个问题,社区已经在考虑增加对应的back-off机制,减轻这种情况带来的影响。
通过unassignedNonTerminatedPod FilterFunc过滤出那些还未成功调度的并且NonTerminated Pods,然后再对这些Pods的Add/Update/Delete Event Handler进行注册,这里我们只关注对PriorityQueue的操作。
// unassignedNonTerminatedPod selects pods that are unassigned and non-terminal.
func unassignedNonTerminatedPod(pod *v1.Pod) bool {
if len(pod.Spec.NodeName) != 0 {
return false
}
if pod.Status.Phase == v1.PodSucceeded || pod.Status.Phase == v1.PodFailed {
return false
}
return true
}注册Add unassignedNonTerminatedPod Event Handler为addPodToSchedulingQueue。
func (c *configFactory) addPodToSchedulingQueue(obj interface{}) {
if err := c.podQueue.Add(obj.(*v1.Pod)); err != nil {
runtime.HandleError(fmt.Errorf("unable to queue %T: %v", obj, err))
}
}
func (p *PriorityQueue) Add(pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
err := p.activeQ.Add(pod)
if err != nil {
glog.Errorf("Error adding pod %v to the scheduling queue: %v", pod.Name, err)
} else {
if p.unschedulableQ.get(pod) != nil {
glog.Errorf("Error: pod %v is already in the unschedulable queue.", pod.Name)
p.deleteNominatedPodIfExists(pod)
p.unschedulableQ.delete(pod)
}
p.addNominatedPodIfNeeded(pod)
p.cond.Broadcast()
}
return err
}当发现有unassigned Pods Add时,addPodToSchedulingQueue负责把该pods加入到activeQ中,并确保unSchedulableQ中没有这些unassigned pods。
注册Update unassignedNonTerminatedPod Event Handler为updatePodInSchedulingQueue。
func (c *configFactory) updatePodInSchedulingQueue(oldObj, newObj interface{}) {
pod := newObj.(*v1.Pod)
if c.skipPodUpdate(pod) {
return
}
if err := c.podQueue.Update(oldObj.(*v1.Pod), pod); err != nil {
runtime.HandleError(fmt.Errorf("unable to update %T: %v", newObj, err))
}
}updatePodInSchedulingQueue中先调用skipPodUpdate检查是否该pod update event可以忽略。
如果不能忽略该pod update,再invoke podQueue.Update更新activeQ,如果该pod不在activeQ中,则从unSchedulableQ中删除该pod,然后把新的pod Push到activeQ中。
func (c *configFactory) skipPodUpdate(pod *v1.Pod) bool {
// Non-assumed pods should never be skipped.
isAssumed, err := c.schedulerCache.IsAssumedPod(pod)
if err != nil {
runtime.HandleError(fmt.Errorf("failed to check whether pod %s/%s is assumed: %v", pod.Namespace, pod.Name, err))
return false
}
if !isAssumed {
return false
}
// Gets the assumed pod from the cache.
assumedPod, err := c.schedulerCache.GetPod(pod)
if err != nil {
runtime.HandleError(fmt.Errorf("failed to get assumed pod %s/%s from cache: %v", pod.Namespace, pod.Name, err))
return false
}
// Compares the assumed pod in the cache with the pod update. If they are
// equal (with certain fields excluded), this pod update will be skipped.
f := func(pod *v1.Pod) *v1.Pod {
p := pod.DeepCopy()
// ResourceVersion must be excluded because each object update will
// have a new resource version.
p.ResourceVersion = ""
// Spec.NodeName must be excluded because the pod assumed in the cache
// is expected to have a node assigned while the pod update may nor may
// not have this field set.
p.Spec.NodeName = ""
// Annotations must be excluded for the reasons described in
// https://github.com/kubernetes/kubernetes/issues/52914.
p.Annotations = nil
return p
}
assumedPodCopy, podCopy := f(assumedPod), f(pod)
if !reflect.DeepEqual(assumedPodCopy, podCopy) {
return false
}
glog.V(3).Infof("Skipping pod %s/%s update", pod.Namespace, pod.Name)
return true
}skipPodUpdate检查到以下情况同时发生时,都会返回true,表示忽略该pod update event。
该pod已经Assumed:检查scheduler cache中assumePods中是否包含该pod,如果包含,说明它已经Assumed(当pod完成了scheduler的Predicate和Priority后,立刻就设置为Assumed,之后再调用apiserver的Bind接口)。
该pod update只更新了它的ResourceVersion, Spec.NodeName, Annotations三者之一或者全部。
func (p *PriorityQueue) Update(oldPod, newPod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
// If the pod is already in the active queue, just update it there.
if _, exists, _ := p.activeQ.Get(newPod); exists {
p.updateNominatedPod(oldPod, newPod)
err := p.activeQ.Update(newPod)
return err
}
// If the pod is in the unschedulable queue, updating it may make it schedulable.
if usPod := p.unschedulableQ.get(newPod); usPod != nil {
p.updateNominatedPod(oldPod, newPod)
if isPodUpdated(oldPod, newPod) {
p.unschedulableQ.delete(usPod)
err := p.activeQ.Add(newPod)
if err == nil {
p.cond.Broadcast()
}
return err
}
p.unschedulableQ.addOrUpdate(newPod)
return nil
}
// If pod is not in any of the two queue, we put it in the active queue.
err := p.activeQ.Add(newPod)
if err == nil {
p.addNominatedPodIfNeeded(newPod)
p.cond.Broadcast()
}
return err
}当skipPodUpdate为true时,接着调用PriorityQueue.Update:
如果该pod已经在activeQ中,则更新它。
如果该pod在unSchedulableQ中,检查该Pod是不是有效更新(忽略ResourceVersion、Generation、PodStatus)。
如果是有效更新,则从unSchedulableQ中删除该,并将更新的pod加到activeQ中待调度。
如果是无效更新,则更新unSchedulableQ中的该pod信息。
如果activeQ和unSchedulableQ中都没有该pod,则把该pod添加到activeQ中。
注册Delete unassignedNonTerminatedPod Event Handler为deletePodFromSchedulingQueue。
func (c *configFactory) deletePodFromSchedulingQueue(obj interface{}) {
...
if err := c.podQueue.Delete(pod); err != nil {
runtime.HandleError(fmt.Errorf("unable to dequeue %T: %v", obj, err))
}
...
}
func (p *PriorityQueue) Delete(pod *v1.Pod) error {
p.lock.Lock()
defer p.lock.Unlock()
p.deleteNominatedPodIfExists(pod)
err := p.activeQ.Delete(pod)
if err != nil { // The item was probably not found in the activeQ.
p.unschedulableQ.delete(pod)
}
return nil
}deletePodFromSchedulingQueue中对podQueue的处理就是调用其Delete接口,将该pod从activeQ或者unSchedulableQ中删除。
NodeInformer注册了Node的Add/Update/Delete Event Handler,这里我们只关注这些Handler对PriorityQueue的操作。
注册Add Node Event Handler为addNodeToCache。
注册Update Node Event Handler为updateNodeInCache。
注册Delete Node Event Handler为deleteNodeFromCache。
func (c *configFactory) addNodeToCache(obj interface{}) {
...
c.podQueue.MoveAllToActiveQueue()
}
func (c *configFactory) updateNodeInCache(oldObj, newObj interface{}) {
...
c.podQueue.MoveAllToActiveQueue()
}addNodeToCache和updateNodeInCache对PriorityQueue的操作都是一样的,调用PriorityQueue.MoveAllToActiveQueue将所有unSchedulableQ中的Pods移到activeQ中,意味着集群中增加或者更新Node时,所有未成功调度的pods都会重新在activeQ中按优先级进行重新排序等待调度。
deleteNodeFromCache中不涉及PodQueue的操作。
同
PodInformer EventHandler for Scheduled Pod中提到的一样,如果集群中出现频繁增加或者更新Node的动作,会导致频繁将unSchedulableQ中的所有Pods移到activeQ中。如果unSchedulableQ中有个High Priority的Pod,那么就会导致频繁的抢占Lower Priority Pods的调度机会,使得Lower Priority Pod长期处于饥饿状态。
serviceInformer注册了Service的Add/Update/Delete Event Handler,这里我们只关注这些Handler对PriorityQueue的操作。
注册Add Service Event Handler为onServiceAdd。
注册Update Service Event Handler为onServiceUpdate。
注册Delete Service Event Handler为onServiceDelete。
func (c *configFactory) onServiceAdd(obj interface{}) {
...
c.podQueue.MoveAllToActiveQueue()
}
func (c *configFactory) onServiceUpdate(oldObj interface{}, newObj interface{}) {
...
c.podQueue.MoveAllToActiveQueue()
}
func (c *configFactory) onServiceDelete(obj interface{}) {
...
c.podQueue.MoveAllToActiveQueue()
}Service的Add/Update/Delete Event Handler对podQueue的操作都是一样的,调用PriorityQueue.MoveAllToActiveQueue将所有unSchedulableQ中的Pods移到activeQ中,意味着集群中增加、更新或者删除Service时,所有未成功调度的pods都会重新在activeQ中按优先级进行重新排序等待调度。
同
PodInformer EventHandler for Scheduled Pod中提到的一样,如果集群中出现频繁Add/Update/Delete Service的动作,会导致频繁将unSchedulableQ中的所有Pods移到activeQ中。如果unSchedulableQ中有个High Priority的Pod,那么就会导致频繁的抢占Lower Priority Pods的调度机会,使得Lower Priority Pod长期处于饥饿状态。
pvcInformer注册了pvc的Add/Update/Delete Event Handler,这里我们只关注这些Handler对PriorityQueue的操作。
注册Add PVC Event Handler为onPvcAdd。
注册Update PVC Event Handler为onPvcUpdate。
注册Delete PVC Event Handler为onPvcDelete。
func (c *configFactory) onPvcAdd(obj interface{}) {
...
c.podQueue.MoveAllToActiveQueue()
}
func (c *configFactory) onPvcUpdate(old, new interface{}) {
...
c.podQueue.MoveAllToActiveQueue()
}sheduler对PVC的Add和Update Event的操作都是一样的,调用PriorityQueue.MoveAllToActiveQueue将所有unSchedulableQ中的Pods移到activeQ中,意味着集群中增加或者更新PVC时,所有未成功调度的pods都会重新在activeQ中按优先级进行重新排序等待调度。
Delete PVC不涉及PodQueue的操作。
PV的Add/Update/Delete也不涉及PodQueue的操作。
同
PodInformer EventHandler for Scheduled Pod中提到的一样,如果集群中出现频繁Add/Update PVC的动作,会导致频繁将unSchedulableQ中的所有Pods移到activeQ中。如果unSchedulableQ中有个High Priority的Pod,那么就会导致频繁的抢占Lower Priority Pods的调度机会,使得Lower Priority Pod长期处于饥饿状态。
感谢各位的阅读,以上就是“Kubernetes Scheduler的优先级队列是什么”的内容了,经过本文的学习后,相信大家对Kubernetes Scheduler的优先级队列是什么这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





