今天给大家介绍一下HLA-VBSeq中如何对全基因组数据进行HLA分型。文章的内容小编觉得不错,现在给大家分享一下,觉得有需要的朋友可以了解一下,希望对大家有所帮助,下面跟着小编的思路一起来阅读吧。
HLA-VBseq 利用全基因组测序的数据,可以提供8位的HLA分型结果,其文献链接如下
https://bmcgenomics.biomedcentral.com/articles/10.1186/1471-2164-16-S2-S7
下面利用30X的全基因组数据,对HLA-VBSeq, PHLAT, HLAminer这3款软件的分型结果进行了评估,准确率汇总如下
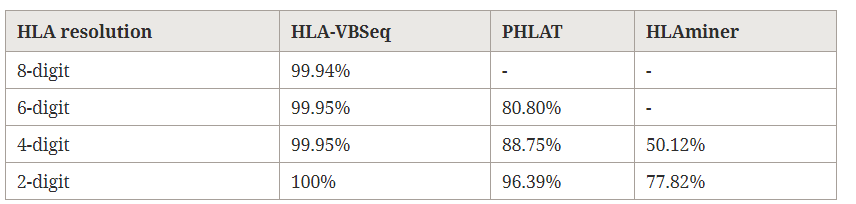
可以看到,只有HLA-VBSeq提供了8位的分型结果,准确率高达99.94%;对于2位到4位的分型结果,其准确率也高于另外两款软件。
同时还评估了不同测序量时,各种软件提供的4位分型结果的准确率,结果如下
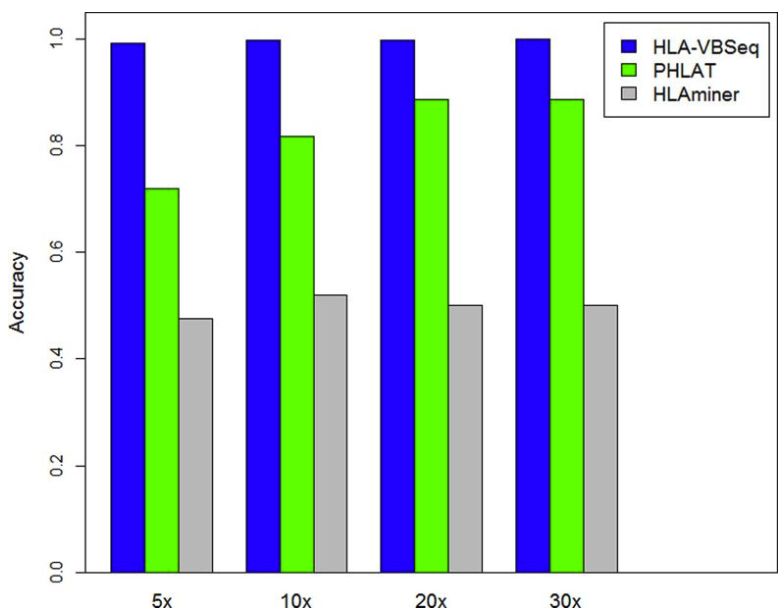
在不同条件下,HLA-VBseq的准确率都是最高的。由此可见,该软件的分型效果还是相当不错的,官网如下
http://nagasakilab.csml.org/hla/
该软件采用java语言开发,直接下载HLAVBseq.jar就可以了,除了该文件之外,还需要下载以下几个文件
bamNameIndex.jar
SamToFastq.jar
parse_result.pl
hla_all.fasta
Allelelist.txt
前三个程序在处理fastq文件时会用到;后两个文件是从IMGA/HLA数据库下载的,如果觉得官网提供的版本较老,可以从IMGA/HLA数据库下载最新版。
软件的步骤较多,首先将fastq序列与参考基因组进行比对,得到bam文件,然后对该bam文件进行操作。步骤如下:
利用samtools view 命令挑选出比对到HLA区域的reads , 命令如下
samtools view -hb align.bam chr6:29907037-29915661 chr6:31319649-31326989 chr6:31234526-31241863 chr6:32914391-32922899 chr6:32900406-32910847 chr6:32969960-32979389 chr6:32778540-32786825 chr6:33030346-33050555 chr6:33041703-33059473 chr6:32603183-32613429 chr6:32707163-32716664 chr6:32625241-32636466 chr6:32721875-32733330 chr6:32405619-32414826 chr6:32544547-32559613 chr6:32518778-32554154 chr6:32483154-32559613 chr6:30455183-30463982 chr6:29689117-29699106 chr6:29792756-29800899 chr6:29793613-29978954 chr6:29855105-29979733 chr6:29892236-29899009 chr6:30225339-30236728 chr6:31369356-31385092 chr6:31460658-31480901 chr6:29766192-29772202 chr6:32810986-32823755 chr6:32779544-32808599 chr6:29756731-29767588 | samtools fastq - -1 R1.fq -2 R2.fq需要注意的是,在使用view命令时,虽然也可以直接提供一个bed格式的文件来挑选特定区域的reads,但是这种用法不会利用到bam文件的索引,所以速度很慢。对于全基因组数据,bam文件很大,上述写法虽然冗长,但是执行效率高。
利用samtools view 命令挑选出没有比对上参考基因组的reads, 命令如下:
samtools view -hb -f 12 /home/pub/output/WGS/18B0315D/6343/6343_final.bam | samtools fastq - -1 unmapped_R1.fq -2 unmapped_R2.fq将比对到HLA区域的reads和没比对上参考基因组的reads合并,命令如下
cat R1.fq unmapped_R1.fq > R1.fastq
cat R2.fq unmapped_R2.fq > R2.fastq利用bwa软件,将上一步得到的reads与HLA参考序列比对,命令如下
bwa index hla_all.fasta
bwa mem -t 8 -P -L 10000 -a hla_all.fasta R1.fastq R2.fastq > out.samHLA-VBSeq支持双端或者单端测序的数据,这里以双端数据为例,用法如下
java -jar HLAVBSeq.jar hla_all.fasta out.sam result.txt --alpha_zero 0.01 --is_paired上一步就已经生成结果了,这一步只是格式化,下面的代码会筛选出HLA-A基因的分型结果
perl parse_result.pl Allelelist.txt result.txt | grep "^A\*" | sort -k2 -n -r > HLA.txt格式化之后的结果,内容如下
A*01:01:01:01 17.4022266628604
A*11:01:01 12.0376819868684共两列,第一列为Allel, 第二列为该Allel区域的平均测序深度。
以上就是HLA-VBSeq中如何对全基因组数据进行HLA分型的全部内容了,更多与HLA-VBSeq中如何对全基因组数据进行HLA分型相关的内容可以搜索亿速云之前的文章或者浏览下面的文章进行学习哈!相信小编会给大家增添更多知识,希望大家能够支持一下亿速云!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4580290/blog/4620966



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



