这篇文章给大家介绍Kubernetes中的kube-scheduler组件怎么用,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
Kubernetes作为一个容器编排调度引擎,资源调度是它的最基本也是最重要的功能。当开发者部署一个应用时它运行在哪个节点?这个节点满不满足开发的运行要求?Kubernetes又是如何进行资源调度的呢?
在Kubernetes中有一个kube-scheduler组件,该组件运行在master节点上,它主要负责pod的调度。Kube-scheduler监听kube-apiserver中是否有还未调度到node上的pod(即Spec.NodeName为空的Pod),再通过特定的算法为pod指定分派node运行。如果分配失败,则将该pod放置调度队列尾部以重新调度。调度主要分为几个部分:首先是预选过程,过滤不满足Pod要求的节点。然后是优选过程,对通过要求的节点进行优先级排序,最后选择优先级最高的节点分配,其中涉及到的两个关键点是过滤和优先级评定的算法。调度器使用一组规则过滤不符合要求的节点,其中包括设置了资源的request和指定了Nodename或者其他亲和性设置等等。优先级评定将过滤得到的节点列表进行打分,调度器考虑一些整体的优化策略,比如将Deployment控制的多个副本集分配到不同节点上等。
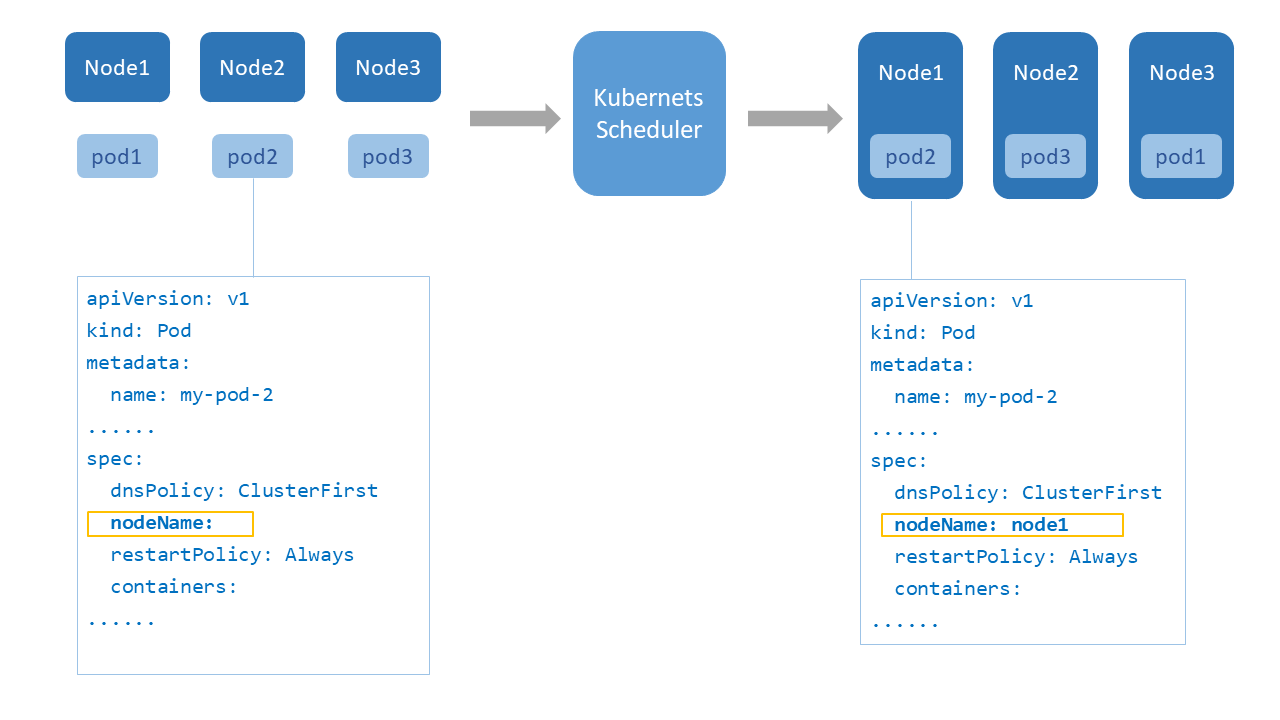
在部署应用时,开发者会考虑到使这个应用运行起来需要多少的内存和CPU资源的使用量,这样才能判断应将他运行在哪个节点上。在部署文件resource属性中添加requests字段用于说明运行该容器所需的最少资源,当调度器开始调度该Pod时,调度程序确保对于每种资源类型,计划容器的资源请求总和必须小于节点的容量才能分配该节点运行Pod,resource属性中添加limits字段用于限制容器运行时所获得的最大资源。如果该容器超出其内存限制,则可能被终止。 如果该容器可以重新启动,kubelet会将它重新启动。如果调度器找不到合适的节点运行Pod时,就会产生调度失败事件,调度器会将Pod放置调度队列以循环调度,直到调度完成。
在下面例子中,运行一个nginx Pod,资源请求了256Mi的内存和100m的CPU,调度器将判断哪个节点还剩余这么多的资源,寻找到了之后就会将这个Pod调度上去。同时也设置了512Mi的内存和300m的CPU的使用限制,如果该Pod运行之后超出了这一限制就将被重启甚至被驱逐。
apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - name: nginx image: nginx resources: requests: memory: "256Mi" cpu: "100m" limits: memory: "512Mi" cpu: "300m"
在部署应用后,可以使用 kubectl describe 命令进行查看Pod的调度事件,下面是一个coredns被成功调度到node3运行的事件记录。
$ kubectl describe po coredns-5679d9cd77-d6jp6 -n kube-system ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 29s default-scheduler Successfully assigned kube-system/coredns-5679d9cd77-d6jp6 to node3 Normal Pulled 28s kubelet, node3 Container image "grc.io/kubernetes/coredns:1.2.2" already present on machine Normal Created 28s kubelet, node3 Created container Normal Started 28s kubelet, node3 Started container
下面是一个coredns被调度失败的事件记录,根据记录显示不可调度的原因是没有节点满足该Pod的内存请求。
$ kubectl describe po coredns-8447874846-5hpmz -n kube-system ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 22s (x3 over 24s) default-scheduler 0/3 nodes are available: 3 Insufficient memory.
例如开发者需要部署一个ES集群,由于ES对磁盘有较高的要求,而集群中只有一部分节点有SSD磁盘,那么就需要将标记一下带有SSD磁盘的节点即给这些节点打上Lable,让ES的pod只能运行在带这些标记的节点上。
Lable是附着在K8S对象(如Pod、Service等)上的键值对。它可以在创建对象的时候指定,也可以在对象创建后随时指定。Kubernetes最终将对labels最终索引和反向索引用来优化查询和watch,在UI和命令行中会对它们排序。通俗的说,就是为K8S对象打上各种标签,方便选择和调度。
关于Kubernetes中的kube-scheduler组件怎么用就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





