Kafka 在 Yelp 的应用十分广泛,Yelp 每天通过各种集群发送数十亿条消息,在这背后,Kafka 使用 Zookeeper 完成各种分布式协调任务。
因为Yelp 非常依赖 Kafka,那么问题来了,它是否可以在不引起 Kafka 及其他 Zookeeper 用户注意的情况下切换 Zookeeper 集群呢?本文将揭晓答案。
Kafka 在 Yelp 的应用十分广泛。事实上,我们 每天通过各种集群发送数十亿条消息。在这背后,Kafka 使用 Zookeeper 完成各种分布式协调任务,例如决定哪个 Kafka broker 负责分配分区首领,以及在 broker 中存储有关主题的元数据。
Kafka 在 Yelp 的成功应用说明了我们的集群从其首次部署 Kafka 以来经历了大幅的增长。与此同时,其他的 Zookeeper 重度用户(例如 Smartstack 和 PaasTA)规模也在增长,给我们的共享 Zookeeper 集群添加了很多负担。为了缓解这种情况,我们决定让我们的 Kafka 集群使用专门的 Zookeeper 集群。
由于我们非常依赖 Kafka,因维护造成的任何停机都会导致连锁反应,例如显示给业务所有者的仪表盘出现延迟、日志堆积在服务器上。那么问题就来了:我们是否可以在不引起 Kafka 及其他 Zookeeper 用户注意的情况下切换 Zookeeper 集群?
Zookeeper 有丝分裂
经过团队间对 Kafka 和 Zookeeper 的几轮讨论和头脑风暴之后,我们找到了一种方法,似乎可以实现我们的目标:在不会导致 Kafka 停机的情况下让 Kafka 集群使用专门的 Zookeeper 集群。
我们提出的方案可以比作自然界的 细胞有丝分裂:我们复制 Zookeeper 主机(即 DNA),然后利用防火墙规则(即细胞壁)把复制好的主机分成两个独立的集群。

有丝分裂中的主要事件,染色体在细胞核中分裂
让我们一步一步深入研究细节。在本文中,我们将会用到源集群和目标集群,源集群代表已经存在的集群,目标集群代表 Kafka 将要迁移到的新集群。我们要用到的示例是一个包含三个节点的 Zookeeper 集群,但这个过程本身可用于任何数量的节点。
我们的示例将为 Zookeeper 节点使用以下 IP 地址:
源 192.168.1.1-3
目标 192.168.1.4-6
第 1 阶段:DNA 复制
首先,我们需要启动一个新的 Zookeeper 集群。这个目标集群必须是空的,因为在迁移的过程中,目标集群中的内容将被删除。
然后,我们将目标集群中的两个节点和源集群中的三个节点组合在一起,得到一个包含五个节点的 Zookeeper 集群。这么做的原因是我们希望数据(最初由 Kafka 保存在源 Zookeeper 集群中)被复制到目标集群上。Zookeeper 的复制机制会自动执行复制过程。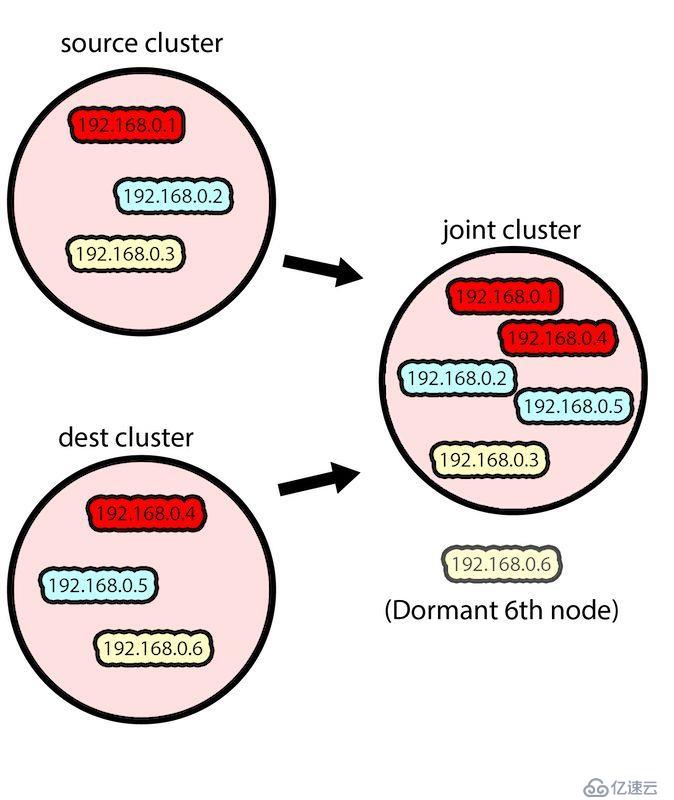
把来自源集群和目标集群的节点组合在一起
每个节点的 zoo.cfg 文件现在看起来都像下面这样,包含源集群的所有节点和目标集群中的两个节点:
server.1=192.168.1.1:2888:3888
server.2=192.168.1.2:2888:3888
server.3=192.168.1.3:2888:3888
server.4=192.168.1.4:2888:3888
server.5=192.168.1.5:2888:3888
注意,来自目标集群的一个节点(在上面的例子中是 192.168.1.6)在该过程中保持休眠状态,没有成为联合集群的一部分,并且 Zookeeper 也没有在其上运行,这是为了保持源集群的 quorum。
此时,联合集群必须重启。确保执行一次滚动重启(每次重启一个节点,期间至少有 10 秒的时间间隔),从来自目标集群的两个节点开始。这个顺序可以确保源集群的 quorum 不会丢失,并在新节点加入该集群时确保对其他客户端(如 Kafka)的可用性。
Zookeeper 节点滚动重启后,Kafka 对联合集群中的新节点一无所知,因为它的 Zookeeper 连接字符串只有原始源集群的 IP 地址:
zookeeper.connect=192.168.1.1,192.168.1.2,192.168.1.3/kafka
发送给 Zookeeper 的数据现在被复制到新节点,而 Kafka 甚至都没有注意到。
现在,源集群和目标集群之间的数据同步了,我们就可以更新 Kafka 的连接字符串,以指向目标集群:
zookeeper.connect=192.168.1.4,192.168.1.5,192.168.1.6/kafka
需要来一次 Kafka 滚动重启,以获取新连接,但不要进行整体停机。
第 2 阶段:有丝分裂
拆分联合集群的第一步是恢复原始源 Zookeeper 及目标 Zookeeper 的配置文件(zoo.cfg),因为它们反映了集群所需的最终状态。注意,此时不应重启 Zookeeper 服务。
我们利用防火墙规则来执行有丝分裂,把我们的联合集群分成不同的源集群和目标集群,每个集群都有自己的首领。在我们的例子中,我们使用 iptables 来实现这一点,但其实可以两个 Zookeeper 集群主机之间强制使用的防火墙系统应该都是可以的。
对每个目标节点,我们运行以下命令来添加 iptables 规则:
$source_node_list = 192.168.1.1,192.168.1.2,192.168.1.3
sudo /sbin/iptables -v -A INPUT -p tcp -d $source_node_list -j REJECT
sudo /sbin/iptables -v -A OUTPUT -p tcp -d $source_node_list -j REJECT
这将拒绝从目标节点到源节点的任何传入或传出 TCP 流量,从而实现两个集群的分隔。
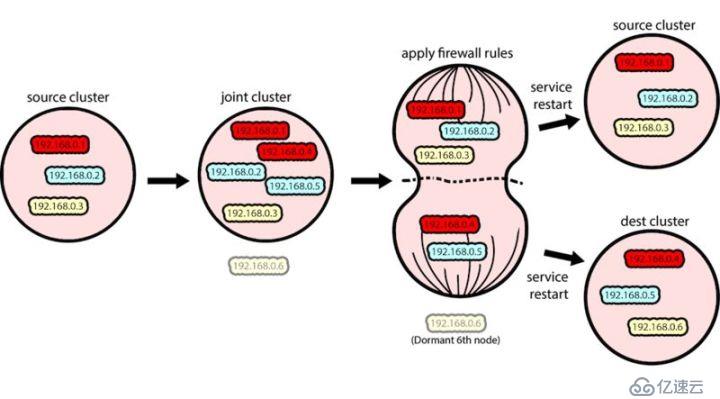
通过防火墙规则分隔源集群和目标集群,然后重启
分隔意味着现在两个目标节点与其他节点是分开的。因为它们认为自己属于一个五节点的集群,而且无法与集群的大多数节点进行通信,所以它们无法进行首领选举。
此时,我们同时重启目标集群中每个节点的 Zookeeper,包括那个不属于联合集群的休眠节点。这样 Zookeeper 进程将使用步骤 2 中提供的新配置,而且还会强制在目标集群中进行首领选举,从而每个集群都会有自己的首领。
从 Kafka 的角度来看,目标集群从发生网络分区那一刻起就不可用,直到首领选举结束后才可用。对 Kafka 来说,这是整个过程中 Zookeeper 不可用的唯一一个时间段。从现在开始,我们有了两个不同的 Zookeeper 集群。
现在我们要做的是清理。源集群仍然认为自己还有两个额外的节点,我们需要清理一些防火墙规则。
接下来,我们重启源集群,让只包含原始源集群节点的 zoo.cfg 配置生效。我们现在可以安全地删除防火墙规则,因为集群之间不再需要相互通信。下面的命令用于删除 iptables 规则:
$source_node_list = 192.168.1.1,192.168.1.2,192.168.1.3
sudo /sbin/iptables -v -D INPUT -p tcp -d $source_node_list -j REJECT
sudo /sbin/iptables -v -D OUTPUT -p tcp -d $source_node_list -j REJECT
树立信心分布式压力测试
我们用于测试迁移过程正确性的主要方法是分布式压力测试。在迁移过程中,我们通过脚本在多台机器上运行数十个 Kafka 生产者和消费者实例。当流量生成完成后,所有被消费的数据有效载荷被聚集到单台主机上,以便检测是否发生数据丢失。
分布式压力测试的工作原理是为 Kafka 生产者和消费者创建一组 Docker 容器,并在多台主机上并行运行它们。所有生成的消息都包含了一个序列号,可以用于检测是否发生消息丢失。
临时集群
为了证明迁移的正确性,我们需要构建一些专门用于测试的集群。我们不是通过手动创建 Kafka 集群,然后在测试完以后再关掉它们,而是构建了一个工具,可以在我们的基础架构上自动生成和关闭集群,从而可以通过脚本来执行整个测试过程。
这个工具连接到 AWS EC2 API 上,并用特定的 EC2 实例标签激活多台主机,允许我们的 puppet 代码配置主机和安装 Kafka(通过 External Node Classifiers
这个临时集群脚本后来被用于创建临时 Elasticsearch 集群进行集成测试,这证明了它是一个非常有用的工具。
zk-smoketest
我们发现,phunt 的 Zookeeper smoketest 脚本 Zookeeper 集群的状态。在迁移的每个阶段,我们在后台运行 smoketest,以确保 Zookeeper 集群的行为符合预期。
zkcopy
我们的第一个用于迁移的计划涉及关闭 Kafka、把 Zookeeper 数据子集复制到新集群、使用更新过的 Zookeeper 连接重启 Kafka。迁移过程的一个更精细的版本——我们称之为“阻止和复制(block & copy)”——被用于把 Zookeeper 客户端迁移到存有数据的集群,这是因为“有丝分裂”过程需要一个空白的目标 Zookeeper 集群。用于复制 Zookeeper 数据子集的工具是 zkcopy,它可以把 Zookeeper 集群的子树复制到另一个集群中。
我们还添加了事务支持,让我们可以批量管理 Zookeeper 操作,并最大限度地减少为每个 znode 创建事务的网络开销。这使我们使用 zkcopy 的速度提高了约 10 倍。
另一个加速迁移过程的核心功能是“mtime”支持,它允许我们跳过复制早于给定修改时间的节点。我们因此避免了让 Zookeeper 集群保持同步的第 2 个“catch-up”复制所需的大部分工作。Zookeeper 的停机时间从 25 分钟减少为不到 2 分钟。
经验教训
Zookeeper 集群是轻量级的,如果有可能,尽量不要在不同服务之间共享它们,因为它们可能会引起 Zookeeper 的性能问题,这些问题很难调试,并且通常需要停机进行修复。
我们可以在 Kafka 不停机的情况下让 Kafka 使用新的 Zookeeper 集群,但是,这肯定不是一件小事。
如果在进行 Zookeeper 迁移时允许 Kafka 停机,那就简单多了。
欢迎学Java和大数据的朋友们加入java架构交流: 855835163
加群链接:https://jq.qq.com/?_wv=1027&k=5dPqXGI
群内提供免费的架构资料还有:Java工程化、高性能及分布式、高性能、深入浅出。高架构。性能调优、Spring,MyBatis,Netty源码分析和大数据等多个知识点高级进阶干货的免费直播讲解 可以进来一起学习交流哦
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



