еҰӮдҪ•дҪҝз”ЁSQLиҜ»еҸ–Kafka并еҶҷе…ҘMySQL
д»ҠеӨ©е°ұи·ҹеӨ§е®¶иҒҠиҒҠжңүе…іеҰӮдҪ•дҪҝз”ЁSQLиҜ»еҸ–Kafka并еҶҷе…ҘMySQLпјҢеҸҜиғҪеҫҲеӨҡдәәйғҪдёҚеӨӘдәҶи§ЈпјҢдёәдәҶи®©еӨ§е®¶жӣҙеҠ дәҶи§ЈпјҢе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеёҢжңӣеӨ§е®¶ж №жҚ®иҝҷзҜҮж–Үз« еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
SqlSubmit зҡ„е®һзҺ°
笔иҖ…дёҖејҖе§ӢжҳҜжғіз”Ё SQL Client жқҘиҙҜз©ҝж•ҙдёӘжј”зӨәзҺҜиҠӮпјҢдҪҶеҸҜжғң 1.9 зүҲжң¬ SQL CLI иҝҳдёҚж”ҜжҢҒеӨ„зҗҶ CREATE TABLE иҜӯеҸҘгҖӮжүҖд»Ҙ笔иҖ…е°ұеҸӘеҘҪиҮӘе·ұеҶҷдәҶдёӘз®ҖеҚ•зҡ„жҸҗдәӨи„ҡжң¬гҖӮеҗҺжқҘжғіжғіпјҢд№ҹжҢәеҘҪзҡ„пјҢеҸҜд»Ҙи®©еҗ¬дј—еҗҢж—¶дәҶи§ЈеҰӮдҪ•йҖҡиҝҮ SQL зҡ„ж–№ејҸпјҢе’Ңзј–зЁӢзҡ„ж–№ејҸдҪҝз”Ё Flink SQLгҖӮ
SqlSubmit зҡ„дё»иҰҒд»»еҠЎжҳҜжү§иЎҢе’ҢжҸҗдәӨдёҖдёӘ SQL ж–Ү件пјҢе®һзҺ°йқһеёёз®ҖеҚ•пјҢе°ұжҳҜйҖҡиҝҮжӯЈеҲҷиЎЁиҫҫејҸеҢ№й…ҚжҜҸдёӘиҜӯеҸҘеқ—гҖӮеҰӮжһңжҳҜ CREATE TABLE жҲ– INSERT INTO ејҖеӨҙпјҢеҲҷдјҡи°ғз”Ё tEnv.sqlUpdate(...)гҖӮеҰӮжһңжҳҜ SET ејҖеӨҙпјҢеҲҷдјҡе°Ҷй…ҚзҪ®и®ҫзҪ®еҲ° TableConfig дёҠгҖӮе…¶ж ёеҝғд»Јз Ғдё»иҰҒеҰӮдёӢжүҖзӨәпјҡ
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();// еҲӣе»әдёҖдёӘдҪҝз”Ё Blink Planner зҡ„ TableEnvironment, 并е·ҘдҪңеңЁжөҒжЁЎејҸTableEnvironment tEnv = TableEnvironment.create(settings);// иҜ»еҸ– SQL ж–Ү件List<String> sql = Files.readAllLines(path);// йҖҡиҝҮжӯЈеҲҷиЎЁиҫҫејҸеҢ№й…ҚеүҚзјҖпјҢжқҘеҢәеҲҶдёҚеҗҢзҡ„ SQL иҜӯеҸҘList<SqlCommandCall> calls = SqlCommandParser.parse(sql);// ж №жҚ®дёҚеҗҢзҡ„ SQL иҜӯеҸҘпјҢи°ғз”Ё TableEnvironment жү§иЎҢfor (SqlCommandCall call : calls) { switch (call.command) { case SET: String key = call.operands[0]; String value = call.operands[1]; // и®ҫзҪ®еҸӮж•°
tEnv.getConfig().getConfiguration().setString(key, value); break; case CREATE_TABLE: String ddl = call.operands[0];
tEnv.sqlUpdate(ddl); break; case INSERT_INTO: String dml = call.operands[0];
tEnv.sqlUpdate(dml); break; default: throw new RuntimeException("Unsupported command: " + call.command);
}
}// жҸҗдәӨдҪңдёҡtEnv.execute("SQL Job");дҪҝз”Ё DDL иҝһжҺҘ Kafka жәҗиЎЁ
еңЁ flink-sql-submit йЎ№зӣ®дёӯпјҢжҲ‘们еҮҶеӨҮдәҶдёҖд»ҪжөӢиҜ•ж•°жҚ®йӣҶпјҲжқҘиҮӘйҳҝйҮҢдә‘еӨ©жұ е…¬ејҖж•°жҚ®йӣҶпјҢзү№еҲ«йёЈи°ўпјүпјҢдҪҚдәҺ src/main/resources/user_behavior.logгҖӮж•°жҚ®д»Ҙ JSON ж јејҸзј–з ҒпјҢеӨ§жҰӮй•ҝиҝҷдёӘж ·еӯҗпјҡ
{"user_id": "543462", "item_id":"1715", "category_id": "1464116", "behavior": "pv", "ts": "2017-11-26T01:00:00Z"}
{"user_id": "662867", "item_id":"2244074", "category_id": "1575622", "behavior": "pv", "ts": "2017-11-26T01:00:00Z"}дёәдәҶжЁЎжӢҹзңҹе®һзҡ„ Kafka ж•°жҚ®жәҗпјҢ笔иҖ…иҝҳзү№ең°еҶҷдәҶдёҖдёӘ source-generator.sh и„ҡжң¬пјҲж„ҹе…ҙи¶Јзҡ„еҸҜд»ҘзңӢдёӢжәҗз ҒпјүпјҢдјҡиҮӘеҠЁиҜ»еҸ– user_behavior.log зҡ„ж•°жҚ®е№¶д»Ҙй»ҳи®ӨжҜҸжҜ«з§’1жқЎзҡ„йҖҹзҺҮзҒҢеҲ° Kafka зҡ„ user_behavior topic дёӯгҖӮ
жңүдәҶж•°жҚ®жәҗеҗҺпјҢжҲ‘们е°ұеҸҜд»Ҙз”Ё DDL еҺ»еҲӣе»ә并иҝһжҺҘиҝҷдёӘ Kafka дёӯзҡ„ topicпјҲиҜҰи§Ғ src/main/resources/q1.sqlпјүгҖӮ
CREATE TABLE user_log (
user_id VARCHAR,
item_id VARCHAR,
category_id VARCHAR,
behavior VARCHAR,
ts TIMESTAMP
) WITH ( 'connector.type' = 'kafka', -- дҪҝз”Ё kafka connector 'connector.version' = 'universal', -- kafka зүҲжң¬пјҢuniversal ж”ҜжҢҒ 0.11 д»ҘдёҠзҡ„зүҲжң¬ 'connector.topic' = 'user_behavior', -- kafka topic 'connector.startup-mode' = 'earliest-offset', -- д»Һиө·е§Ӣ offset ејҖе§ӢиҜ»еҸ– 'connector.properties.0.key' = 'zookeeper.connect', -- иҝһжҺҘдҝЎжҒҜ 'connector.properties.0.value' = 'localhost:2181',
'connector.properties.1.key' = 'bootstrap.servers', 'connector.properties.1.value' = 'localhost:9092',
'update-mode' = 'append', 'format.type' = 'json', -- ж•°жҚ®жәҗж јејҸдёә json 'format.derive-schema' = 'true' -- д»Һ DDL schema зЎ®е®ҡ json и§Јжһҗ规еҲҷ
)
жіЁпјҡеҸҜиғҪжңүз”ЁжҲ·дјҡи§үеҫ—е…¶дёӯзҡ„ connector.properties.0.key зӯүеҸӮж•°жҜ”иҫғеҘҮжҖӘпјҢзӨҫеҢәи®ЎеҲ’е°ҶеңЁдёӢдёҖдёӘзүҲжң¬дёӯж”№иҝӣ并з®ҖеҢ– connector зҡ„еҸӮж•°й…ҚзҪ®гҖӮ
дҪҝз”Ё DDL иҝһжҺҘ MySQL з»“жһңиЎЁ
иҝһжҺҘ MySQL еҸҜд»ҘдҪҝз”Ё Flink жҸҗдҫӣзҡ„ JDBC connectorгҖӮдҫӢеҰӮ
CREATE TABLE pvuv_sink (
dt VARCHAR,
pv BIGINT,
uv BIGINT
) WITH ( 'connector.type' = 'jdbc', -- дҪҝз”Ё jdbc connector 'connector.url' = 'jdbc:mysql://localhost:3306/flink-test', -- jdbc url 'connector.table' = 'pvuv_sink', -- иЎЁеҗҚ 'connector.username' = 'root', -- з”ЁжҲ·еҗҚ 'connector.password' = '123456', -- еҜҶз Ғ 'connector.write.flush.max-rows' = '1' -- й»ҳи®Ө5000жқЎпјҢдёәдәҶжј”зӨәж”№дёә1жқЎ
)
PV UV и®Ўз®—
еҒҮи®ҫжҲ‘们зҡ„йңҖжұӮжҳҜи®Ўз®—жҜҸе°Ҹж—¶е…ЁзҪ‘зҡ„з”ЁжҲ·и®ҝй—®йҮҸпјҢе’ҢзӢ¬з«Ӣз”ЁжҲ·ж•°гҖӮеҫҲеӨҡз”ЁжҲ·еҸҜиғҪдјҡжғіеҲ°дҪҝз”Ёж»ҡеҠЁзӘ—еҸЈжқҘи®Ўз®—гҖӮдҪҶиҝҷйҮҢжҲ‘们д»Ӣз»ҚеҸҰдёҖз§Қж–№ејҸгҖӮеҚі Group Aggregation зҡ„ж–№ејҸгҖӮ
INSERT INTO pvuv_sink
SELECT
DATE_FORMAT(ts, 'yyyy-MM-dd HH:00') dt,
COUNT(*) AS pv,
COUNT(DISTINCT user_id) AS uv
FROM user_log
GROUP BY DATE_FORMAT(ts, 'yyyy-MM-dd HH:00')
е®ғдҪҝз”Ё DATE_FORMAT иҝҷдёӘеҶ…зҪ®еҮҪж•°пјҢе°Ҷж—Ҙеҝ—ж—¶й—ҙеҪ’дёҖеҢ–жҲҗвҖңе№ҙжңҲж—Ҙе°Ҹж—¶вҖқзҡ„еӯ—з¬ҰдёІж јејҸпјҢе№¶ж №жҚ®иҝҷдёӘеӯ—з¬ҰдёІиҝӣиЎҢеҲҶз»„пјҢеҚіж №жҚ®жҜҸе°Ҹж—¶еҲҶз»„пјҢ然еҗҺйҖҡиҝҮ COUNT(*) и®Ўз®—з”ЁжҲ·и®ҝй—®йҮҸпјҲPVпјүпјҢйҖҡиҝҮ COUNT(DISTINCT user_id) и®Ўз®—зӢ¬з«Ӣз”ЁжҲ·ж•°пјҲUVпјүгҖӮиҝҷз§Қж–№ејҸзҡ„жү§иЎҢжЁЎејҸжҳҜжҜҸ收еҲ°дёҖжқЎж•°жҚ®пјҢдҫҝдјҡиҝӣиЎҢеҹәдәҺд№ӢеүҚи®Ўз®—зҡ„еҖјеҒҡеўһйҮҸи®Ўз®—пјҲеҰӮ+1пјүпјҢ然еҗҺе°ҶжңҖж–°з»“жһңиҫ“еҮәгҖӮжүҖд»Ҙе®һж—¶жҖ§еҫҲй«ҳпјҢдҪҶиҫ“еҮәйҮҸд№ҹеӨ§гҖӮ
жҲ‘们е°ҶиҝҷдёӘжҹҘиҜўзҡ„з»“жһңпјҢйҖҡиҝҮ INSERT INTO иҜӯеҸҘпјҢеҶҷеҲ°дәҶд№ӢеүҚе®ҡд№үзҡ„ pvuv_sink MySQL иЎЁдёӯгҖӮ
жіЁпјҡеңЁж·ұеңі Meetup дёӯпјҢжҲ‘们жңүеҜ№иҝҷз§ҚжҹҘиҜўзҡ„жҖ§иғҪи°ғдјҳеҒҡдәҶж·ұеәҰзҡ„д»Ӣз»ҚгҖӮ
е®һжҲҳжј”зӨә
зҺҜеўғеҮҶеӨҮ
жң¬е®һжҲҳжј”зӨәзҺҜиҠӮйңҖиҰҒе®үиЈ…дёҖдәӣеҝ…йЎ»зҡ„жңҚеҠЎпјҢеҢ…жӢ¬пјҡ
Flink жң¬ең°йӣҶзҫӨпјҡз”ЁжқҘиҝҗиЎҢ Flink SQL д»»еҠЎгҖӮ
Kafka жң¬ең°йӣҶзҫӨпјҡз”ЁжқҘдҪңдёәж•°жҚ®жәҗгҖӮ
MySQL ж•°жҚ®еә“пјҡз”ЁжқҘдҪңдёәз»“жһңиЎЁгҖӮ
Flink жң¬ең°йӣҶзҫӨе®үиЈ…
1.дёӢиҪҪ Flink 1.9.0 е®үиЈ…еҢ…并解еҺӢпјҡ https://www.apache.org/dist/flink/flink-1.9.0/flink-1.9.0-bin-scala_2.11.tgz
2.дёӢиҪҪд»ҘдёӢдҫқиө– jar еҢ…пјҢ并жӢ·иҙқеҲ° flink-1.9.0/lib/ зӣ®еҪ•дёӢгҖӮеӣ дёәжҲ‘们иҝҗиЎҢж—¶йңҖиҰҒдҫқиө–еҗ„дёӘ connector е®һзҺ°гҖӮ
flink-sql-connector-kafka_2.11-1.9.0.jar
http://central.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.11/1.9.0/flink-sql-connector-kafka_2.11-1.9.0.jar
flink-json-1.9.0-sql-jar.jar
http://central.maven.org/maven2/org/apache/flink/flink-json/1.9.0/flink-json-1.9.0-sql-jar.jar
flink-jdbc_2.11-1.9.0.jar
http://central.maven.org/maven2/org/apache/flink/flink-jdbc_2.11/1.9.0/flink-jdbc_2.11-1.9.0.jar
mysql-connector-java-5.1.48.jar
https://dev.mysql.com/downloads/connector/j/5.1.html
3.е°Ҷ flink-1.9.0/conf/flink-conf.yaml дёӯзҡ„ taskmanager.numberOfTaskSlots дҝ®ж”№жҲҗ 10пјҢеӣ дёәжҲ‘们зҡ„жј”зӨәд»»еҠЎеҸҜиғҪдјҡж¶ҲиҖ—еӨҡдәҺ1дёӘзҡ„ slotгҖӮ
4.еңЁ flink-1.9.0 зӣ®еҪ•дёӢжү§иЎҢ ./bin/start-cluster.shпјҢеҗҜеҠЁйӣҶзҫӨгҖӮ
иҝҗиЎҢжҲҗеҠҹзҡ„иҜқпјҢеҸҜд»ҘеңЁ http://localhost:8081 и®ҝй—®еҲ° Flink Web UIгҖӮ
еҸҰеӨ–пјҢиҝҳйңҖиҰҒе°Ҷ Flink зҡ„е®үиЈ…и·Ҝеҫ„еЎ«еҲ° flink-sql-submit йЎ№зӣ®зҡ„ env.sh дёӯпјҢз”ЁдәҺеҗҺйқўжҸҗдәӨ SQL д»»еҠЎпјҢеҰӮжҲ‘зҡ„и·Ҝеҫ„жҳҜ
FLINK_DIR=/Users/wuchong/dev/install/flink-1.9.0
Kafka жң¬ең°йӣҶзҫӨе®үиЈ…
дёӢиҪҪ Kafka 2.2.0 е®үиЈ…еҢ…并解еҺӢпјҡ https://www.apache.org/dist/kafka/2.2.0/kafka_2.11-2.2.0.tgz
е°Ҷе®үиЈ…и·Ҝеҫ„еЎ«еҲ° flink-sql-submit йЎ№зӣ®зҡ„ env.sh дёӯпјҢеҰӮжҲ‘зҡ„и·Ҝеҫ„жҳҜ
KAFKA_DIR=/Users/wuchong/dev/install/kafka_2.11-2.2.0
еңЁ flink-sql-submit зӣ®еҪ•дёӢиҝҗиЎҢ ./start-kafka.sh еҗҜеҠЁ Kafka йӣҶзҫӨгҖӮ
еңЁе‘Ҫд»ӨиЎҢжү§иЎҢ jpsпјҢеҰӮжһңзңӢеҲ° Kafka иҝӣзЁӢе’Ң QuorumPeerMain иҝӣзЁӢеҚіиЎЁжҳҺеҗҜеҠЁжҲҗеҠҹгҖӮ
MySQL е®үиЈ…
еҸҜд»ҘеңЁе®ҳж–№йЎөйқўдёӢиҪҪ MySQL 并е®үиЈ…пјҡ
https://dev.mysql.com/downloads/mysql/
еҰӮжһңжңү Docker зҺҜеўғзҡ„иҜқпјҢд№ҹеҸҜд»ҘзӣҙжҺҘйҖҡиҝҮ Docker е®үиЈ…
https://hub.docker.com/_/mysql
$ docker pull mysql
$ docker run --name mysqldb -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 -d mysql
然еҗҺеңЁ MySQL дёӯеҲӣе»әдёҖдёӘ flink-test зҡ„ж•°жҚ®еә“пјҢ并жҢүз…§дёҠж–Үзҡ„ schema еҲӣе»ә pvuv_sink иЎЁгҖӮ
жҸҗдәӨ SQL д»»еҠЎ
еңЁ flink-sql-submit зӣ®еҪ•дёӢиҝҗиЎҢ ./source-generator.shпјҢдјҡиҮӘеҠЁеҲӣе»ә user_behavior topicпјҢ并е®һж—¶еҫҖйҮҢзҒҢе…Ҙж•°жҚ®
еңЁ flink-sql-submit зӣ®еҪ•дёӢиҝҗиЎҢ ./run.sh q1пјҢ жҸҗдәӨжҲҗеҠҹеҗҺпјҢеҸҜд»ҘеңЁ Web UI дёӯзңӢеҲ°жӢ“жү‘гҖӮ
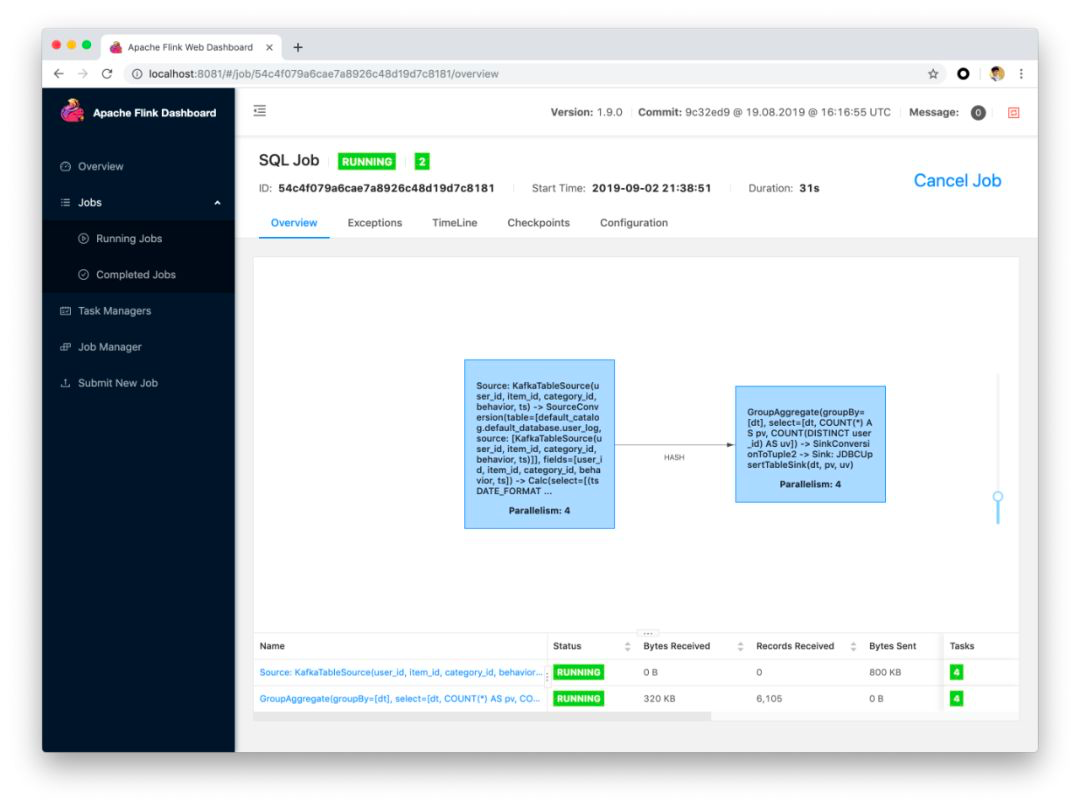
еңЁ MySQL е®ўжҲ·з«ҜпјҢжҲ‘们д№ҹеҸҜд»Ҙе®һж—¶ең°зңӢеҲ°жҜҸдёӘе°Ҹж—¶зҡ„ pv uv еҖјеңЁдёҚж–ӯең°еҸҳеҢ–
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们еҜ№еҰӮдҪ•дҪҝз”ЁSQLиҜ»еҸ–Kafka并еҶҷе…ҘMySQLжңүиҝӣдёҖжӯҘзҡ„дәҶи§Јеҗ—пјҹеҰӮжһңиҝҳжғідәҶи§ЈжӣҙеӨҡзҹҘиҜҶжҲ–иҖ…зӣёе…іеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеӨ§е®¶зҡ„ж”ҜжҢҒгҖӮ





