这篇文章给大家介绍TensorFlow 中的指标列与嵌入列如何理解,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
一般地,机器学习、深度学习 feed 进来的数据要求为数值型。如果某列取值为字符型,需要做数值转换,今天就来总结下 TensorFlow 中的指标列和嵌入列。
指标列 ( indicator column ) 是指取值仅一个为 1,其他都为 0 的向量,它是稀疏的; 嵌入列 (embedding column) ,取值介于0和1之间,它是稠密的。
指标列,采取 one-hot 编码方法,有多少类输入就会得到一个多少维的向量。如果输入类别为 4 类,那么可以编码为如下,0,1,2,3 类分别编码为4维的向量。
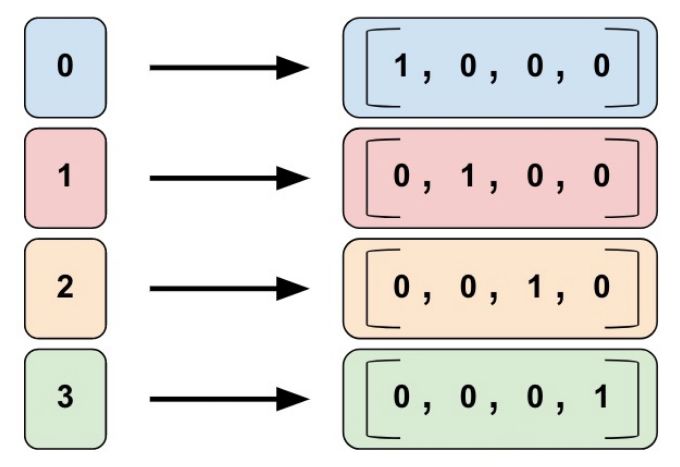
TensorFlow 中通过调用 tf.feature_column.indicator_column 创建指标列
categorical_column = ...
indicator_column = tf.feature_column.indicator_column(categorical_column)
但是,假设我们有一千万个可能的类别,或者可能有十亿个,而不是只有四个。出于多种原因,随着类别数量的增加,使用指标列来训练神经网络变得不可行。
如何解决类别数量激增导致的指标列不可行问题?
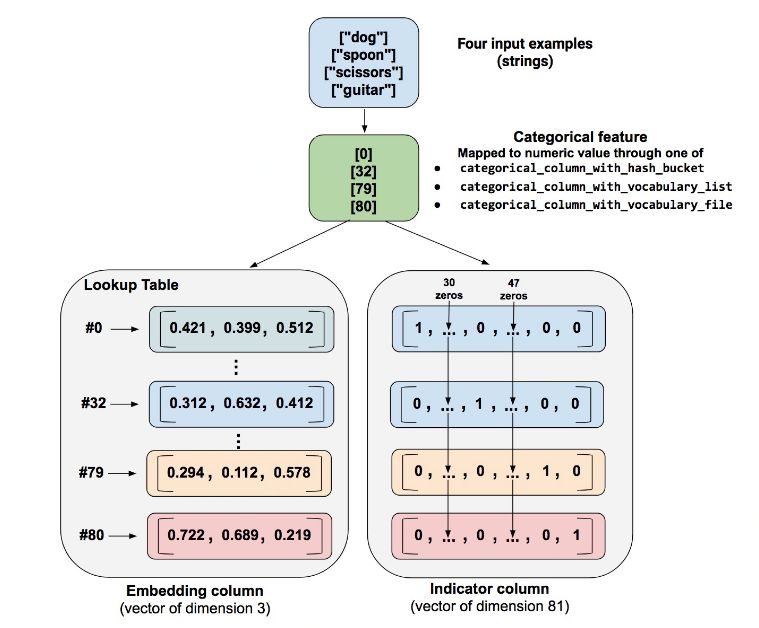
使用嵌入列来克服这一限制,嵌入列并非将数据表示为很多维度的独热矢量,而是将数据表示为低维度普通矢量,其中每个单元格可以包含任意数字,而不仅仅是 0 或 1。通过使每个单元格能够包含更丰富的数字,嵌入列包含的单元格数量远远少于指标列。
每个嵌入向量的维度是怎么确定的呢?嵌入矢量中的值如何神奇地得到分配呢?
1、设定词汇表单词个数为 1 万。如果选用指标列,则每个单词的取值为 1 万维,采取嵌入列,每个单词的维度仅为 10,这相比 one-hot 编码绝对是低维度了,维度取值一般经验公式是单词个数的4次方根。
2、初始时,将随机数字放入嵌入向量中,分配值在训练期间进行,嵌入矢量从训练数据中学习了类别之间的新关系。
TensorFlow 中通过调用 tf.feature_column.embedding_column 创建嵌入列,
categorical_column = ...
embedding_column = tf.feature_column.embedding_column(
categorical_column=categorical_column, dimension=dimension)
最后,以一个展示指标列和嵌入列的区别实例作为结尾,
关于TensorFlow 中的指标列与嵌入列如何理解就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





