жҖҺд№Ҳз”ЁRedisз»ҹи®ЎзӢ¬з«Ӣз”ЁжҲ·и®ҝй—®йҮҸ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңжҖҺд№Ҳз”ЁRedisз»ҹи®ЎзӢ¬з«Ӣз”ЁжҲ·и®ҝй—®йҮҸвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁжҖҺд№Ҳз”ЁRedisз»ҹи®ЎзӢ¬з«Ӣз”ЁжҲ·и®ҝй—®йҮҸй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқжҖҺд№Ҳз”ЁRedisз»ҹи®ЎзӢ¬з«Ӣз”ЁжҲ·и®ҝй—®йҮҸвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
дҪҝз”ЁHash
е“ҲеёҢжҳҜRedisзҡ„дёҖз§ҚеҹәзЎҖж•°жҚ®з»“жһ„пјҢRedisеә•еұӮз»ҙжҠӨзҡ„жҳҜдёҖдёӘејҖж•ЈеҲ—пјҢдјҡжҠҠдёҚеҗҢзҡ„keyжҳ е°„еҲ°е“ҲеёҢиЎЁдёҠпјҢеҰӮжһңжҳҜйҒҮеҲ°е…ій”®еӯ—еҶІзӘҒпјҢйӮЈд№Ҳе°ұдјҡжӢүеҮәдёҖдёӘй“ҫиЎЁеҮәжқҘгҖӮ
еҪ“дёҖдёӘз”ЁжҲ·и®ҝй—®зҡ„ж—¶еҖҷпјҢеҰӮжһңз”ЁжҲ·зҷ»йҷҶиҝҮпјҢйӮЈд№ҲжҲ‘们е°ұдҪҝз”Ёз”ЁжҲ·зҡ„idпјҢеҰӮжһңз”ЁжҲ·жІЎжңүзҷ»йҷҶиҝҮпјҢйӮЈд№ҲжҲ‘们д№ҹиғҪеӨҹеүҚз«ҜйЎөйқўйҡҸжңәз”ҹжҲҗдёҖдёӘkeyз”ЁжқҘж ҮиҜҶз”ЁжҲ·пјҢеҪ“з”ЁжҲ·и®ҝй—®зҡ„ж—¶еҖҷпјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁHSETе‘Ҫд»ӨпјҢkeyеҸҜд»ҘйҖүжӢ©URIдёҺеҜ№еә”зҡ„ж—ҘжңҹиҝӣиЎҢжӢјеҮ‘пјҢfieldеҸҜд»ҘдҪҝз”Ёз”ЁжҲ·зҡ„idжҲ–иҖ…йҡҸжңәж ҮиҜҶпјҢvalueеҸҜд»Ҙз®ҖеҚ•и®ҫзҪ®дёә1гҖӮ
еҪ“жҲ‘们иҰҒз»ҹи®ЎжҹҗдёҖдёӘзҪ‘з«ҷжҹҗдёҖеӨ©зҡ„и®ҝй—®йҮҸзҡ„ж—¶еҖҷпјҢе°ұеҸҜд»ҘзӣҙжҺҘдҪҝз”ЁHLENжқҘеҫ—еҲ°жңҖз»Ҳзҡ„з»“жһңдәҶгҖӮ
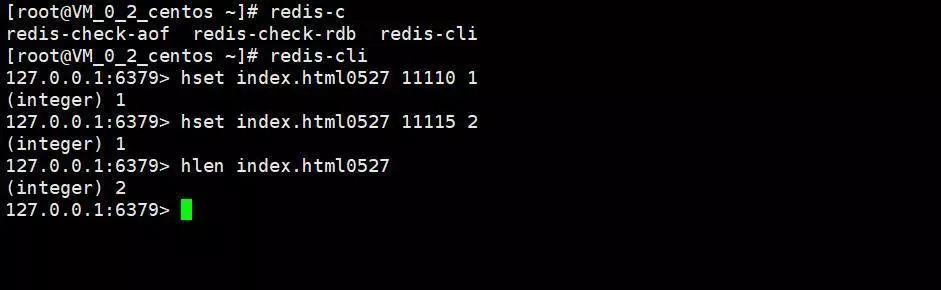
дјҳзӮ№пјҡз®ҖеҚ•пјҢе®№жҳ“е®һзҺ°пјҢжҹҘиҜўд№ҹжҳҜйқһеёёж–№дҫҝпјҢж•°жҚ®еҮҶзЎ®жҖ§йқһеёёй«ҳгҖӮ
зјәзӮ№пјҡеҚ з”ЁеҶ…еӯҳиҝҮеӨ§пјҢгҖӮйҡҸзқҖkeyзҡ„еўһеӨҡпјҢжҖ§иғҪд№ҹдјҡдёӢйҷҚгҖӮе°ҸзҪ‘з«ҷиҝҳиЎҢпјҢжӢјеӨҡеӨҡиҝҷз§Қж•°дәҝPVзҡ„зҪ‘з«ҷиӮҜе®ҡеҸ—дёҚдәҶ
дҪҝз”ЁBitset
жҲ‘们зҹҘйҒ“пјҢеҜ№дәҺдёҖдёӘ32дҪҚзҡ„intпјҢеҰӮжһңжҲ‘们еҸӘз”ЁжқҘи®°еҪ•idпјҢйӮЈд№ҲеҸӘиғҪеӨҹи®°еҪ•дёҖдёӘз”ЁжҲ·пјҢдҪҶеҰӮжһңжҲ‘们иҪ¬жҲҗ2иҝӣеҲ¶пјҢжҜҸдҪҚз”ЁжқҘиЎЁзӨәдёҖдёӘз”ЁжҲ·пјҢйӮЈд№ҲжҲ‘们е°ұиғҪеӨҹдёҖеҸЈж°”иЎЁзӨә32дёӘз”ЁжҲ·пјҢз©әй—ҙиҠӮзңҒдәҶ32еҖҚпјҒеҜ№дәҺжңүеӨ§йҮҸж•°жҚ®зҡ„еңәжҷҜпјҢеҰӮжһңжҲ‘们дҪҝз”ЁbitsetпјҢйӮЈд№ҲпјҢеҸҜд»ҘиҠӮзңҒйқһеёёеӨҡзҡ„еҶ…еӯҳгҖӮеҜ№дәҺжІЎжңүзҷ»йҷҶзҡ„з”ЁжҲ·пјҢжҲ‘们д№ҹеҸҜд»ҘдҪҝз”Ёе“ҲеёҢз®—жі•пјҢжҠҠеҜ№еә”зҡ„з”ЁжҲ·ж ҮиҜҶе“ҲеёҢжҲҗдёҖдёӘж•°еӯ—idгҖӮbitsetйқһеёёзҡ„иҠӮзңҒеҶ…еӯҳпјҢеҒҮи®ҫжңү1дәҝдёӘз”ЁжҲ·пјҢд№ҹеҸӘйңҖиҰҒ100000000/8/1024/1024зәҰзӯүдәҺ12е…ҶеҶ…еӯҳгҖӮ

Redisе·Із»ҸдёәжҲ‘们жҸҗдҫӣдәҶSETBITзҡ„ж–№жі•пјҢдҪҝз”Ёиө·жқҘйқһеёёзҡ„ж–№дҫҝпјҢжҲ‘们еҸҜд»ҘзңӢзңӢдёӢйқўзҡ„дҫӢеӯҗпјҢжҲ‘们еңЁitemйЎөйқўеҸҜд»ҘдёҚеҒңең°дҪҝз”ЁSETBITе‘Ҫд»ӨпјҢи®ҫзҪ®з”ЁжҲ·е·Із»Ҹи®ҝй—®дәҶиҜҘйЎөйқўпјҢд№ҹеҸҜд»ҘдҪҝз”ЁGETBITзҡ„ж–№жі•жҹҘиҜўжҹҗдёӘз”ЁжҲ·жҳҜеҗҰи®ҝй—®гҖӮжңҖеҗҺжҲ‘们йҖҡиҝҮBITCOUNTеҸҜд»Ҙз»ҹи®ЎиҜҘзҪ‘йЎөжҜҸеӨ©зҡ„и®ҝй—®ж•°йҮҸгҖӮ

дјҳзӮ№пјҡеҚ з”ЁеҶ…еӯҳжӣҙе°ҸпјҢжҹҘиҜўж–№дҫҝпјҢеҸҜд»ҘжҢҮе®ҡжҹҘиҜўжҹҗдёӘз”ЁжҲ·пјҢж•°жҚ®еҸҜиғҪз•Ҙжңүз‘•з–өпјҢеҜ№дәҺйқһзҷ»йҷҶзҡ„з”ЁжҲ·пјҢеҸҜиғҪдёҚеҗҢзҡ„keyжҳ е°„еҲ°еҗҢдёҖдёӘidпјҢеҗҰеҲҷйңҖиҰҒз»ҙжҠӨдёҖдёӘйқһзҷ»йҷҶз”ЁжҲ·зҡ„жҳ е°„пјҢжңүйўқеӨ–зҡ„ејҖй”ҖгҖӮ
зјәзӮ№пјҡеҰӮжһңз”ЁжҲ·йқһеёёзҡ„зЁҖз–ҸпјҢйӮЈд№ҲеҚ з”Ёзҡ„еҶ…еӯҳеҸҜиғҪжҜ”ж–№жі•дёҖжӣҙеӨ§гҖӮ
дҪҝз”ЁжҰӮзҺҮз®—жі•
еҜ№дәҺжӢјеӨҡеӨҡиҝҷз§ҚеӨҡдёӘйЎөйқўйғҪеҸҜиғҪйқһеёёеӨҡи®ҝй—®йҮҸзҡ„зҪ‘з«ҷпјҢеҰӮжһңжүҖйңҖиҰҒзҡ„ж•°йҮҸдёҚз”ЁйӮЈд№ҲеҮҶзЎ®пјҢеҸҜд»ҘдҪҝз”ЁжҰӮзҺҮз®—жі•пјҢдәӢе®һдёҠпјҢжҲ‘们еҜ№дёҖдёӘзҪ‘з«ҷзҡ„UVзҡ„з»ҹи®ЎпјҢ1дәҝи·ҹ1дәҝйӣ¶30дёҮе…¶е®һжҳҜе·®дёҚеӨҡзҡ„гҖӮеңЁRedisдёӯпјҢе·Із»Ҹе°ҒиЈ…дәҶHyperLogLogз®—жі•пјҢд»–жҳҜдёҖз§Қеҹәж•°иҜ„дј°з®—жі•гҖӮиҝҷз§Қз®—жі•зҡ„зү№еҫҒпјҢдёҖиҲ¬йғҪжҳҜж•°жҚ®дёҚеӯҳе…·дҪ“зҡ„еҖјпјҢиҖҢжҳҜеӯҳз”ЁжқҘи®Ўз®—жҰӮзҺҮзҡ„дёҖдәӣзӣёе…іж•°жҚ®гҖӮ

еҪ“з”ЁжҲ·и®ҝй—®зҪ‘з«ҷзҡ„ж—¶еҖҷпјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁPFADDе‘Ҫд»ӨпјҢи®ҫзҪ®еҜ№еә”зҡ„е‘Ҫд»ӨпјҢжңҖеҗҺжҲ‘们еҸӘиҰҒйҖҡиҝҮPFCOUNTе°ұиғҪйЎәеҲ©и®Ўз®—еҮәжңҖз»Ҳзҡ„з»“жһңпјҢеӣ дёәиҝҷдёӘеҸӘжҳҜдёҖдёӘжҰӮзҺҮз®—жі•пјҢжүҖд»ҘеҸҜиғҪеӯҳеңЁ0.81%зҡ„иҜҜе·®гҖӮ
дјҳзӮ№пјҡеҚ з”ЁеҶ…еӯҳжһҒе°ҸпјҢеҜ№дәҺдёҖдёӘkeyпјҢеҸӘйңҖиҰҒ12kbгҖӮеҜ№дәҺжӢјеӨҡеӨҡиҝҷз§Қи¶…еӨҡз”ЁжҲ·зҡ„зү№еҲ«йҖӮз”ЁгҖӮ
зјәзӮ№пјҡжҹҘиҜўжҢҮе®ҡз”ЁжҲ·зҡ„ж—¶еҖҷпјҢеҸҜиғҪдјҡеҮәй”ҷпјҢжҜ•з«ҹеӯҳзҡ„дёҚжҳҜе…·дҪ“зҡ„ж•°жҚ®гҖӮжҖ»ж•°д№ҹеӯҳеңЁдёҖе®ҡзҡ„иҜҜе·®гҖӮ
дёҠйқўе°ұжҳҜеёёи§Ғзҡ„3з§ҚйҖӮз”ЁRedisз»ҹи®ЎзҪ‘з«ҷз”ЁжҲ·и®ҝй—®ж•°зҡ„ж–№жі•дәҶгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңжҖҺд№Ҳз”ЁRedisз»ҹи®ЎзӢ¬з«Ӣз”ЁжҲ·и®ҝй—®йҮҸвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





