жңәеҷЁеӯҰд№ дёӯжҖҺд№ҲиҜ„дј°еҲҶзұ»ж•Ҳжһң
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іжңәеҷЁеӯҰд№ дёӯжҖҺд№ҲиҜ„дј°еҲҶзұ»ж•ҲжһңпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
з»ҷдҪ дёҖдёӘй—®йўҳпјҢеҒҮеҰӮиҖҒжқҝи®©еҸҰдёҖдёӘеҗҢдәӢеҺ»жЈҖжҹҘдёҖдёҮеј зәёеёҒдёӯпјҢжңүеӨҡе°‘жҳҜзңҹеёҒпјҢжңүеӨҡе°‘жҳҜеҒҮеёҒпјҢ然еҗҺиҝҷдёӘеҗҢдәӢз»ҷиҖҒжқҝжұҮжҠҘдәҶз»“жһңпјҡиҝҷдёҖдёҮеј зәёеёҒдёӯпјҢжңү2еҚғеј жҳҜзңҹеёҒпјҢжңү8еҚғеј жҳҜеҒҮеёҒгҖӮзҺ°еңЁпјҢиҖҒжқҝи®©дҪ жқҘиҜ„дј°иҝҷдёӘеҗҢдәӢзҡ„жұҮжҠҘз»“жһңпјҢдҪ дјҡжҖҺд№ҲеҒҡпјҹ
дҪ йҮҚж–°жҠҠдёҖдёҮеј зәёеёҒеҶҚз”ЁжңәеҷЁиҝҮдёҖйҒҚеҶҚеҒҡеҜ№жҜ”пјҢжҲ–иҖ…жҠҠиҝҷдёӘеҗҢдәӢзҡ„2еҚғеј зңҹеёҒдёҺ8еҚғеј еҒҮеёҒеҶҚиҝҮдёҖйҒҚпјҢиҝҷйғҪжҳҜеҸҜд»Ҙзҡ„гҖӮдҪҶжҳҜпјҢеҒҮеҰӮдёҚе…Ғи®ёдҪ иҝҷж ·еҒҡе‘ўпјҢжҜ”еҰӮдёҖдёҮеј зәёеёҒеҸҳжҲҗдәҶ1зҷҫдёҮеј пјҢдёҚеҸҜиғҪз»ҷдҪ ж—¶й—ҙеҶҚе…ЁйғЁжқҘдёҖйҒҚпјҢйӮЈдҪ жҖҺд№ҲеҒҡпјҹ
жҠҪжҹҘе•ҠгҖӮ
дјјд№Һе°ұиҝҷдёҖжӢӣпјҢйӮЈд№ҲиҰҒжҖҺд№ҲжҠҪжҹҘжүҚиғҪеҗҲзҗҶең°иҜ„дј°еҗҢдәӢжұҮжҠҘзҡ„з»“жһңе‘ўпјҹ
дёҖиҲ¬зҡ„еҒҡжі•жҳҜиҝҷж ·зҡ„пјҢе…ҲеңЁ2еҚғеј зңҹеёҒдёҠжҠҪжҹҘпјҡвҖңдҪ иҜҙиҝҷдәӣйғҪжҳҜзңҹеёҒпјҢе“ӘеҲ°еә•жңүеӨҡе°‘жҳҜзңҹзҡ„е‘ўпјҹвҖқ иҝҷдёӘжҜ”дҫӢпјҢеңЁж•°жҚ®еҲҶжһҗдёӯпјҢеҸ«PrecisionпјҢзІҫеәҰжҲ–зІҫеҮҶеәҰгҖӮеҰӮжһң100%жҳҜзңҹзҡ„пјҢйӮЈеҪ“然жҳҜжңҖеҘҪзҡ„гҖӮдҪҶеҚідҪҝзІҫеҮҶеәҰжҳҜ100%пјҢд№ҹдёҚиғҪиҜҙжҳҺиҝҷдёӘжұҮжҠҘз»“жһңе°ұokдәҶпјҢеӣ дёәпјҢеҸҰеӨ–8еҚғеј вҖңеҒҮеёҒвҖқдёӯд№ҹжңүеҸҜиғҪе…ЁжҳҜзңҹеёҒе•ҠгҖӮ
жүҖд»ҘпјҢиҝҳиҰҒеңЁ8еҚғеј еҒҮеёҒдёӯжҠҪжҹҘпјҡвҖңдҪ иҜҙйғҪжҳҜеҒҮзҡ„пјҢе“ӘеҲ°еә•жңүеӨҡе°‘жҳҜеҒҮзҡ„е‘ўпјҹвҖқ иҝҷдёӘжҜ”дҫӢпјҢд№ҹиғҪиҜҙжҳҺй—®йўҳпјҢеҒҮеҰӮжҠҪдәҶдёҖзҷҫеј пјҢз»“жһңжңү90еј йғҪжҳҜзңҹеёҒпјҲеҸӘжңү10%зңҹжҳҜеҒҮеёҒпјүпјҢйӮЈиҜҙиҝҷ8еҚғеј йғҪжҳҜеҒҮеёҒе°ұжҳҫеҫ—еҫҲдёҚеҸҜдҝЎгҖӮиҝҷдёӘжҜ”дҫӢпјҢе°ҸзЁӢи§үеҫ—е®ғд№ҹеҸ«дҪңзІҫеҮҶеәҰпјҢе°ұжҳҜвҖңдҪ иҜҙзҡ„еҒҮдёӯпјҢеҲ°еә•жңүеӨҡе°‘жҳҜеҒҮвҖқпјҢеҖји¶ҠеӨ§и¶ҠеҘҪгҖӮ
йӮЈйҷӨдәҶзІҫеҮҶеәҰпјҢжҳҜдёҚжҳҜе°ұеӨҹдәҶе‘ўпјҹ
зңӢиө·жқҘжҳҜеӨҹдәҶпјҢеӣ дёәпјҢзІҫеҮҶеәҰеҸҚеә”дәҶвҖңеҲӨжҳҜйқһвҖқзҡ„иғҪеҠӣгҖӮд»ҘдёҠйқўзҡ„дҫӢеӯҗжқҘиҜҙпјҢжҜ”еҰӮеҲӨж–ӯдёәзңҹеёҒзҡ„зІҫеәҰжҳҜ98%пјҢйӮЈе°ұж„Ҹе‘ізқҖеҸӘжңү2%зҡ„еҒҮеёҒиў«иҜҜеҲӨдёәзңҹеёҒдәҶпјҢжүҖд»ҘжҲ‘жҠҠеҒҮеёҒеҲӨж–ӯдёәзңҹеёҒзҡ„еҸҜиғҪжҖ§жҳҜеҫҲдҪҺзҡ„пјҲеҒҮи®ҫ2%еңЁдёҡз•ҢжҳҜеҫҲдҪҺзҡ„пјҡ-пјүгҖӮеҶҚжҜ”еҰӮпјҢеҒҮи®ҫеҲӨж–ӯдёәеҒҮеёҒзҡ„зІҫеәҰжҳҜ95%пјҢйӮЈе°ұж„Ҹе‘ізқҖеҸӘжңү5%зҡ„зңҹеёҒз»ҷиҜҜеҲӨжҲҗеҒҮеёҒдәҶгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢжҠҠеҒҮзҡ„еҲӨж–ӯжҲҗзңҹзҡ„пјҢжҲ–жҠҠзңҹзҡ„еҲӨж–ӯжҲҗеҒҮзҡ„пјҢжҜ”дҫӢйғҪеҫҲдҪҺгҖӮиҝҷдёҚе°ұе®ҢдәҶеҗ—пјҹиҝҷиҜҙжҳҺвҖңеҲӨжҳҜйқһвҖқзҡ„иғҪеҠӣеҫҲејәе•ҠпјҢиҝҷдёӘйў„жөӢзі»з»ҹжҳҜеҸҜдҝЎзҡ„е•ҠпјҢе®ғдёҚдјҡжҠҠзңҹеҒҮиҜҜеҲӨе•ҠпјҢдҪ з»ҷе®ғдёҖе ҶзәёеёҒпјҢе®ғе°ұиғҪз»ҷдҪ еҲҶиҫЁзңҹеҒҮпјҢдёҚдјҡеҮәй”ҷе•ҠгҖӮ
дҪҶжҳҜпјҢиҝҷйҮҢжңүдёҖдёӘеүҚжҸҗпјҢиҝҷдёӘзі»з»ҹиҰҒеңЁеҲӨж–ӯеҗҺпјҢдҪ жүҚзҹҘйҒ“жҳҜдёҚжҳҜеҲӨж–ӯеҜ№дәҶгҖӮеҰӮжһңиҝҷдёӘзі»з»ҹеҜ№жүҖжңүзәёеёҒйғҪдёҚеҲӨж–ӯпјҢжҲ–иҖ…иҖ…1дёҮеј зәёеёҒдёӯеҸӘеҲӨж–ӯдәҶ1еҚғеј пјҢйӮЈдҪ иҝҳжҢҮжңӣе®ғеҒҡд»Җд№Ҳпјҹе®ғжҳҜеҫҲеҮҶе•ҠпјҢдҪҶжҳҜпјҢе®ғеҸӘжңүеҲӨж–ӯеҮәжқҘзҡ„жүҚеҫҲеҮҶпјҢиҝҳжңүеҫҲеӨҡжҳҜжІЎжңүеҲӨж–ӯеҮәжқҘзҡ„пјҒдҪҶиҜқиҜҙеӣһжқҘпјҢе…¶е®һеҸӘиҰҒеҫҲеҮҶпјҲзІҫеәҰй«ҳпјүпјҢе°ұжңүдҪҝз”ЁеёӮеңәзҡ„пјҢиҝҷдёӘеҗҺйқўеҶҚиҜҙгҖӮ
жүҖд»ҘпјҢиҝҷйҮҢиҝҳжңүдёҖдёӘжҢҮж ҮпјҢеҸ«SensitivityзҒөж•ҸеәҰпјҢд№ҹеҸ«RecallеҸ¬еӣһзҺҮгҖӮ
еҸ¬еӣһзҺҮпјҢеҸҚжҳ дәҶвҖңжүҫеӣһвҖқзҡ„иғҪеҠӣпјҢжҜ”еҰӮжҲ‘з»ҷзі»з»ҹ1еҚғеј зңҹеёҒпјҢе®ғиғҪжүҫеҮә800еј зңҹеёҒпјҢйӮЈ80%е°ұжҳҜеҸ¬еӣһзҺҮгҖӮеҰӮжһңе®ғзҡ„еҸ¬еӣһзҺҮжҳҜ10%пјҢйӮЈиҜҙжҳҺеҸӘжүҫеӣһдәҶ100еј пјҢиҝҳжңү900еј жҳҜжҖҺд№ҲеӣһдәӢпјҹиҝҷж—¶пјҢжңүдёӨдёӘеҸҜиғҪпјҢдёҖжҳҜеҲӨж–ӯдёҚеҮәжқҘпјҢжҜ”еҰӮиҝҷ900еј жҲ‘е°ұжҳҜеҲӨж–ӯдёҚеҮәжқҘпјҢжүҖд»Ҙе°ұжүҫдёҚеӣһжқҘпјҢеҸҰдёҖдёӘеҸҜиғҪпјҢе°ұжҳҜиҜҜеҲӨдәҶпјҢжҜ”еҰӮ900еј жҲ‘йғҪиҜҜеҲӨдёәеҒҮеёҒдәҶгҖӮдҪҶжҳҜпјҢиҜҜеҲӨиҜҙжҳҺд»Җд№ҲпјҹиҜҜеҲӨиҜҙжҳҺзІҫеәҰе·®е•ҠпјҢжүҖд»ҘеҰӮжһңзІҫеәҰеҫҲй«ҳпјҢйӮЈе°ұеҸӘжңүдёҖз§ҚеҸҜиғҪпјҢе°ұжҳҜеҲӨж–ӯдёҚеҮәжқҘгҖӮ
жүҖд»ҘпјҢзІҫеәҰи·ҹеҸ¬еӣһзҺҮйғҪиҰҒзңӢпјҢзІҫеәҰеҸҚеә”дәҶйқ дёҚйқ и°ұпјҲиҜҙд»Җд№ҲжҳҜд»Җд№ҲпјүпјҢеҸ¬еӣһзҺҮеҸҚеә”дәҶиғҪдёҚиғҪжүҫеҲ°ж•°жҚ®пјҲиҰҶзӣ–дәҶеӨҡе°‘ж ·жң¬пјүгҖӮ
дёҚз®ЎжҳҜзІҫеәҰиҝҳжҳҜеҸ¬еӣһзҺҮпјҢйғҪеҸӘжҳҜдёҖдёӘж•°еӯ—пјҢиҖҢдёәдәҶеҫ—еҲ°иҝҷдёӘж•°еӯ—пјҢдёҖиҲ¬йғҪжҳҜз»ҸиҝҮеҫҲеӨҡж ·жң¬зҡ„йў„жөӢиҖғйӘҢжүҚеҫ—еҮәжқҘзҡ„пјҢжүҖд»ҘжҠҠиҝҷдәӣж ·жң¬йғҪеҸҚеә”еҮәжқҘе°ұжҳҫеҫ—еҫҲеҝ…иҰҒдәҶпјҢиҝҷиЎЁжҳҺпјҢжҲ‘зҡ„вҖңзҺҮвҖқжҳҜжңүз”ұжқҘзҡ„гҖӮиҝҷж—¶еҖҷпјҢвҖңж··ж·Ҷзҹ©йҳөвҖқе°ұеҮәеңәдәҶгҖӮ
ж··ж·Ҷзҹ©йҳөпјҢд№ҹеҸ«е·®й”ҷзҹ©йҳөпјҢеҗҚеӯ—йғҪжҳҜд»Һй¬јж–Үзҝ»иҜ‘иҝҮжқҘзҡ„пјҲз”ұжӯӨеҸҜи§ҒпјҢеҗ«д№үжүҚжҳҜжңҖйҮҚиҰҒзҡ„пјҢй¬јзҹҘйҒ“зҝ»иҜ‘еҲ°зҡ„жҳҜд»Җд№ҲпјүгҖӮж··ж·Ҷзҹ©йҳөжҳҜдёҖеј иЎЁж јпјҢдёҖиҫ№жҳҜзңҹе®һеҖјпјҢдёҖиҫ№жҳҜйў„жөӢеҖјпјҢжЁӘз«–жҖҺд№Ҳж‘ҶйғҪиЎҢпјҢзңӢдёӢйқўиҝҷдёӘеӣҫе°ұжҳҺзҷҪдәҶпјҡ
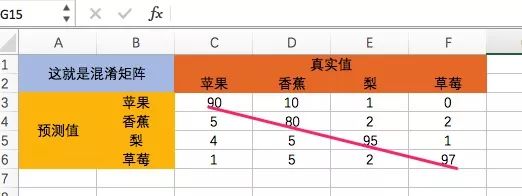
вҖңж··ж·ҶвҖқиЎЁжҳҺдәҶеҲҶзұ»зҡ„иғҪеҠӣпјҢд»ҘдёҠеӣҫдёәдҫӢпјҢиӢ№жһңзҡ„еҸ¬еӣһзҺҮпјҲеңЁдёҖе ҶиӢ№жһңдёӯиғҪжҚһеӣһеӨҡе°‘иӢ№жһңзҡ„иғҪеҠӣпјүжҳҜпјҡ90/(90+5+4+1)=90%пјҢиҖҢйҰҷи•үгҖҒжўЁдёҺиҚүиҺ“зҡ„еҸ¬еӣһзҺҮеҲҶеҲ«дёә80%гҖҒ95%гҖҒ97%гҖӮе°ҸзЁӢжҜҸдёӘеҲҶзұ»еҲҡеҘҪз”ЁдәҶ100дёӘзңҹе®һеҖјпјҢдёәдәҶж–№дҫҝеҝғз®—иғҪеҠӣдёҚеҘҪзҡ„дҪ гҖӮз”ұжӯӨеҸҜи§ҒпјҢеҸіеҜ№и§’зәҝдёҠзҡ„еҖје°ұжҳҜеҸ¬еӣһеҖјпјҢд№ҹе°ұжҳҜеҲӨж–ӯеҮҶзЎ®зҡ„еҖјгҖӮ
еҶҚзңӢзІҫеәҰпјҢиҝҷйҮҢиЎҢиЎЁзӨәдәҶзІҫеәҰпјҢжҜ”еҰӮиӢ№жһңзҡ„зІҫеәҰжҳҜпјҡ90/(90+10+1+0)=89%пјҢйҰҷи•үзҡ„зІҫеәҰжҳҜпјҡ80/(5+80+2+2)=89.9%пјҢжўЁи·ҹиҚүиҺ“еҲҶеҲ«жҳҜ90.4%гҖҒ92.4%гҖӮ
然еҗҺпјҢеҸ¬еӣһзҺҮи·ҹзІҫеәҰдёҖиө·жқҘзңӢпјҢ
иӢ№жһңгҖҒ йҰҷи•үгҖҒ жўЁгҖҒ иҚүиҺ“
90% 80% 95% 97%
89% 89.9% 90.4% 92.4%
иҚүиҺ“зҡ„еҸ¬еӣһзҺҮи·ҹзІҫеәҰйғҪжҳҜжңҖй«ҳзҡ„пјҢи®©жҲ‘们жҒӯе–ңе®ғпјҒ
йҷӨдәҶеҸ¬еӣһзҺҮи·ҹзІҫеәҰпјҢеҜ№дәҺеҲҶзұ»еҷЁпјҲдёҠйқўйў„жөӢиӢ№жһңйҰҷи•үе°ұжҳҜеҲҶзұ»еҷЁпјүж•ҲжһңиҜ„дј°пјҢиҝҳжңүдёӨдёӘжҢҮж ҮпјҢдёҖдёӘеҸ«жҖ»зҡ„еҮҶзЎ®зҺҮпјҢе°ұжҳҜжӢҝеҲӨж–ӯеҮҶзЎ®зҡ„еҖјпјҲеҸіеҜ№и§’зәҝдёҠзҡ„еҖјпјүзӣёеҠ пјҢеҶҚйҷӨд»ҘжҖ»зҡ„ж ·жң¬ж•°йҮҸпјҢиҝҷйҮҢе°ұжҳҜ(90+80+95+97)/400=90.5%пјҢеҸҰдёҖдёӘеҸ«зү№ејӮеәҰпјҢжҜ”еҰӮеҜ№дәҺиӢ№жһңпјҢе°ұжҳҜзңҹзҡ„дёҚжҳҜиӢ№жһңзҡ„ж ·жң¬дёӯпјҢеҲӨж–ӯдёҚжҳҜиӢ№жһңзҡ„жҜ”дҫӢгҖӮдҪҶе°ҸзЁӢи§үеҫ—иҝҷдёӨдёӘжҢҮж Үзҡ„еҸӮиҖғж„Ҹд№үдёҚеӨ§гҖӮ
д»ҺдёҖеј ж ·жң¬иЎЁпјҢжҠҪиұЎеҮәжҜҸдёӘеҲҶзұ»зҡ„еҸ¬еӣһзҺҮи·ҹзІҫеәҰпјҢеҰӮжһңеҶҚжҠҠжҠҪиұЎдёҖдёӢпјҢе°ұжҳҜжҜҸдёӘеҲҶзұ»зҡ„F1ScoreпјҢе®ғжҳҜеҸ¬еӣһзҺҮи·ҹзІҫеәҰзҡ„ж•ҙеҗҲпјҡF1Score=2*зІҫеәҰ*еҸ¬еӣһ/(зІҫеәҰ+еҸ¬еӣһ)пјҢдёҠйқўзҡ„дҫӢеӯҗпјҢиӢ№жһңзҡ„F1Score=2*90%*89%/(90%+89%)=89.49%гҖӮ
еҹәжң¬дёҠпјҢд№ҹе°ұжҳҜз”ЁзІҫеәҰгҖҒеҸ¬еӣһзҺҮжқҘжҸҸиҝ°еҲҶзұ»еҷЁзҡ„иҙЁйҮҸдәҶпјҢжңҖеӨҡеҶҚеҠ дёӘF1ScoreгҖӮ
и®©жҲ‘们еҶҚж·ұе…ҘдёҖзӮ№пјҢй—®дҪ дёҖдёӘй—®йўҳпјҢзІҫеәҰй«ҳеҸҜд»Ҙз”ЁдәҺд»Җд№ҲеңәжҷҜпјҹеҸ¬еӣһзҺҮй«ҳеҸҲеҸҜд»Ҙз”ЁдәҺд»Җд№ҲеңәжҷҜпјҹ
зІҫеәҰй«ҳпјҢе°ұжҳҜдёҚеҮәй”ҷе•°пјҢиҜҙжҳҜд»Җд№Ҳе°ұжҳҜд»Җд№ҲпјҢйӮЈеҸҜд»Ҙз”ЁдәҺеҲҶзұ»пјҢжҜ”еҰӮз»ҷдёҖжү№ж ·жң¬иҝҮжқҘпјҢж ·жң¬йҮҢйқўжңүABCDеҮ дёӘеҲҶзұ»пјҢзІҫеәҰй«ҳзҡ„жғ…еҶөдёӢпјҢе°ұеҸҜд»ҘжҢҮеҮәе“Әдәӣж ·жң¬жҳҜAпјҢе“Әдәӣж ·жң¬жҳҜBпјҢзӯүзӯүгҖӮеҰӮжһңзІҫеәҰй«ҳпјҢдҪҶеҸ¬еӣһзҺҮдҪҺпјҢдёҖж ·еҸҜд»Ҙз”ЁдәҺеҲҶзұ»пјҢеҸӘжҳҜпјҢжңүеҫҲеӨҡAзұ»зҡ„ж ·жң¬жІЎжңүжүҫеҮәжқҘпјҲи°Ғи®©дҪ еҲӨж–ӯдёҚеҮәжқҘпјүпјҢе…¶е®ғеҲҶзұ»д№ҹдёҖж ·гҖӮ
еҸ¬еӣһзҺҮй«ҳпјҢдҪҶзІҫеәҰдҪҺпјҢйӮЈе°ұжҳҜеҲҶзұ»жҳҜдёҚйқ и°ұзҡ„пјҢиҜҙжҳҜAз»“жһңеҸҜиғҪжҳҜBпјҢйӮЈе°ұдёҚиҰҒеҲҶзұ»дәҶпјҢиҝҷж—¶пјҢеӣ дёәеҸ¬еӣһзҺҮй«ҳпјҢйӮЈеҸҜд»Ҙз”ЁдәҺзӯӣйҖүе·Іжңүзҡ„еҲҶзұ»пјҢжҜ”еҰӮиҜҙжңүдёҖжү№ж ·жң¬еҹәжң¬жҳҜAзұ»пјҢеҸӘжҳҜйҮҢйқўеҸҜиғҪжңүдёҖдәӣBи·ҹCпјҢйӮЈе°ұеҸҜд»Ҙз”ЁиҝҷдёӘеҲҶзұ»еҷЁжқҘзӯӣйҖүдәҶпјҢзӣёеҪ“дәҺзә й”ҷпјҢеӣ дёәеҸ¬еӣһзҺҮй«ҳпјҢжүҖд»Ҙеҹәжң¬жҠҠAз»ҷжүҫеӣһжқҘпјҢе…¶е®ғзҡ„жү”жҺүгҖӮ
еҸ¬еӣһзҺҮй«ҳпјҢзІҫеәҰд№ҹй«ҳпјҢд№ҹж—ўеҸҜз”ЁдәҺеҲҶзұ»пјҢд№ҹеҸҜз”ЁдәҺе·ІжңүеҲҶзұ»пјҲзңҹзҡ„еҲҶеҘҪдәҶзҡ„пјүзҡ„зӯӣйҖүгҖӮ
йӮЈеҰӮжһңеҸ¬еӣһзҺҮдҪҺпјҢзІҫеәҰд№ҹдҪҺе‘ўпјҹйӮЈе°ұжҳҜеәҹзҡ„пјҢз”Ёдәәе·ҘеҘҪдәҶпјҒ
е…ідәҺвҖңжңәеҷЁеӯҰд№ дёӯжҖҺд№ҲиҜ„дј°еҲҶзұ»ж•ҲжһңвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





