怎么进行Spark NLP使用入门,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
关于AI在企业中应用的年度O‘Reilly报告已经在2019年2月发布, 该报告针对多个垂直行业的1300多从业人员进行调查, 该调查包含受访者所在企业中生产环境的AI项目,这些AI项目是如何在企业中应用,以及AI如何快速的扩展到深度学习,人机互助系统,知识图谱, 强化学习中。
该调查包含了受访者企业主要使用ML以及AI的框架以及工具情况,下图为使用情况总结的展示图:
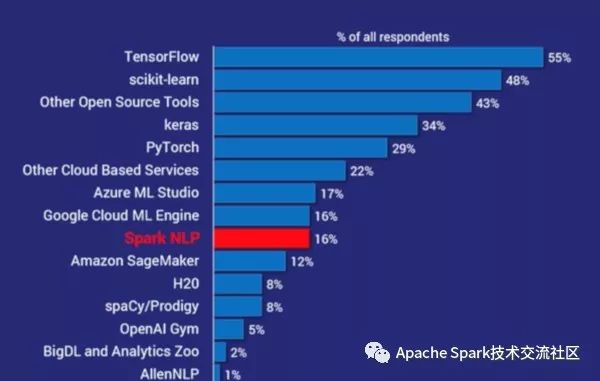
其中Spark NLP在所有的框架以及工具排在第7位,是迄今为止最受欢迎NLP库,其受欢迎程度是spaCy的两倍, 事实上,除了其他开源工具以及其他云服务外提供工具或者框架之外,Spark NLP是继scikit-learn, TensorFlow, Keras,和 PyTorch之后最受欢迎的AI工具。
该调查与近年来Spark NLP在医疗保健,金融, 生命科学和招聘中应用越来越广泛保持一致, 根本原因在NLP技术在近年来发生重大转变。
在过去的3-5年中深度学习在自然语言领域的兴起使得算法的精度越来越高,而传统的例如 spaCy, Stanford CoreNLP, ntlp以及OpenNLP在精度上显然比不上这些最新的研究成果。
为了追求更高的准确度以及性能,工业界不断将最新的研究成果产品化, 下图是迄今为止的总结(基于en_core_web_lg标准测试的F1值):
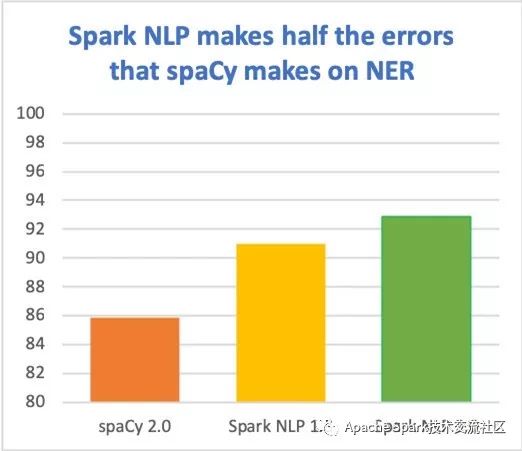
由于Apache Spark的优化使得无论在单机或者在集群的性能都已经非常接近bare metal的性能, Spark NLP的性能可以比传统的AI库快一个数量级, 这些传统的库受限于他们的设计。
一年前O'Reily发布了迄今为止最全面的产品级别的NLP库性能对比测试, 下图中左侧为在spaCy和Spark NLP训练简单流水的性能对比图, 该测试基于单机配置(Intel I5, 4核, 16GB内存)进行:
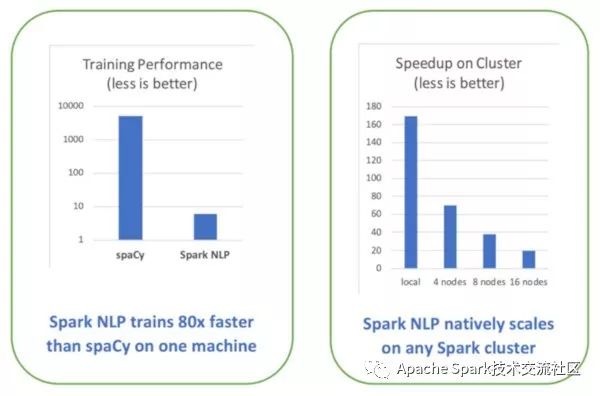
利用GPU来进行训练以及推理编程深度学习的领域的一大趋势,使用TensorFlow进行深度学习使得Spark NLP能够充分利用现代计算机平台 - 从nVida的DGX-1到Intel的Cascade Lake处理器, 传统的库, 不管有没有使用深度学习的技术, 需要重写代码才能够充分利用这些新硬件的特性,而正是这些新硬件的特性使得NLP性能提高了一个数量级。
在深度学习领域能够将模型训练,推理,整个AI流水无缝从单机迁移到集群变得越来越关键,Spark NPL得益于原生的构建Apache Spark ML之上,能够在spark集群做任意扩展, 而Spark的分布式执行计划以及Cache的优化也能助力提升Spark NLP性能。
不同于AllenNLP以及NLP Architect这样面向研究的NLP库,我们致力于向企业提供我们的Spark NLP库。
Spark NLP使用Apache 2.0的许可协议, 不同于Stanford CoreNLP(商业化需要付费)以及SpaCy模型使用的ShareAlike CC许可协议,该协议是完全免费应用于商品化。
支持多语言编程不仅提高了Spark NLP的受众面,而且可以避免在使用过程数据的交换,例如, SpaCy只支持Python, 用户在使用过程需要将数据在JVM进程和Python进程进行交换,这样会导致架构变得复杂以及性能下降。
除了社区贡献,Spark NLP还有一个专门的开发团队,Spark NLP基本上每个月发布两次,在2018年总共发布了26个版本, Spark NLP社区非常欢迎贡献代码,文档,模型以及问题。
Spark NLP 2.0 一大设计目标就是使用者不要了解Spark或者TensorFlow就可以使用Spark和TensorFlow平台带来的好处。用户不必要了解什么是Spark ML的estimator和transformer, 或者什么是tensorFlow graph或者session, 用户也可以使用Spark NLP 构建自己的模型,但是能够以最少时间和学习曲线完成,Spark NLP内置的15种训练流水和模型可以覆盖大部分的用户场景。
用户可以通过pip或者conda安装Spark NLP的python版本,Jupyter以及Databricks的安装以及配置细节可以参考 安装页面 (https://nlp.johnsnowlabs.com/docs/en/install), Spark NLP 被广泛应用在各种组件当中,包括Zepplin, SageMaker, Azure,GCP, Cloudera以及Vanilla spark,支持K8S和非K8S环境。
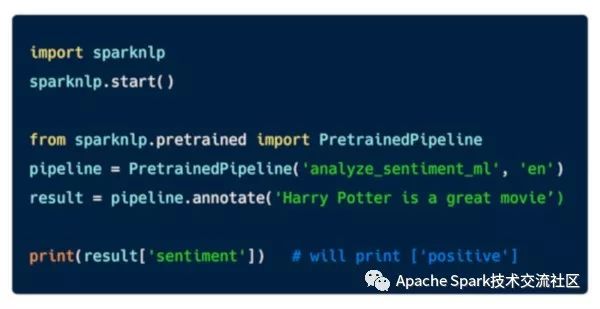
下图是展示的是情绪分析的简单例子:
下图是利用Bert模型训练命名实体识别的例子:
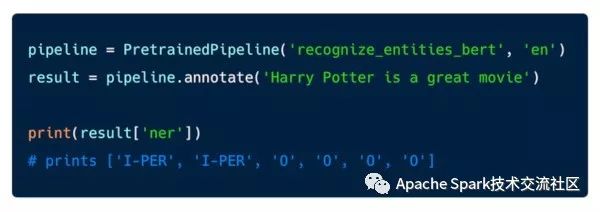
上述例子代码能够在spark集群上处理大量文本,其中有两个关键的方法 - annotate(), 该方法以string类型作为输入, transform(), 该方法的数据输入是spark 的data frame。
Spark NLP是用Scala语言编写的, 可以直接操作Spark Data Frame, 在这过程中数据零拷贝,可以充分利用Spark执行计划以及其他优化,因此对于Scala和Java开发者,使用Spark NLP非常方便。
Spark NLP 可以Maven库中找到, 用户只要加上Spark NLP的依赖就可以使用它, 如果用户希望是有Spark NLP's OCR能力,需要安装额外的依赖。下图是个拼写检查的例子:
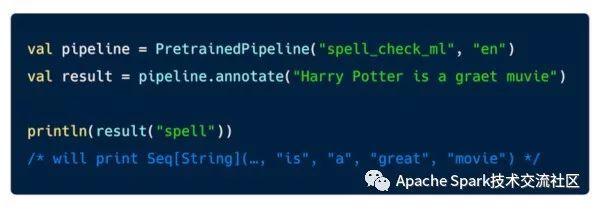
Spark NLP为用户屏蔽许多复杂的细节,因此上面的代码片段都非常简单, 此外Spark NLP也提供了灵活性,用户可以根据自己的需求进行定制。Spark NLP针对训练领域的NLP模型做过深度优化。下面详细介绍Bert模型训练命名实体识别的Python代码:
sparknlp.start() 创建spark session。
PretrainedPipeline() 加载 explain_document_dl流水的英文版本, 预训练模型以及他们的依赖。
启动TensorFlow, TensorFlow的进程跟spark的处于同一个JVM进程,加载预先训练的Embeddings和深度学习的模型(例如NER), 模型可以自动在集群上分发以及共享。
annotate() 启动NLP的推理流程,并且分发各个阶段的算法流程。
NER阶段运行在tensorflow上,分别采用双向LSTM的神经网络以及CNN
Embeddings在推理过程用来将contextual tokens转换为vectors
最后结果以python字典的形式输出
Spark NLP主页包含大量的样例, 文档以及安装说明文档, 此外Spark NLP还提供了docker镜像, 用户可以很方便的在本地构建自己的环境。用户如果遇到任何问题, 用户可以登录Slack寻求帮助。
看完上述内容,你们掌握怎么进行Spark NLP使用入门的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4588192/blog/4590412



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



