一、何为分布式文件文件系统
分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连,它的设计是基于客户端/服务器模式。
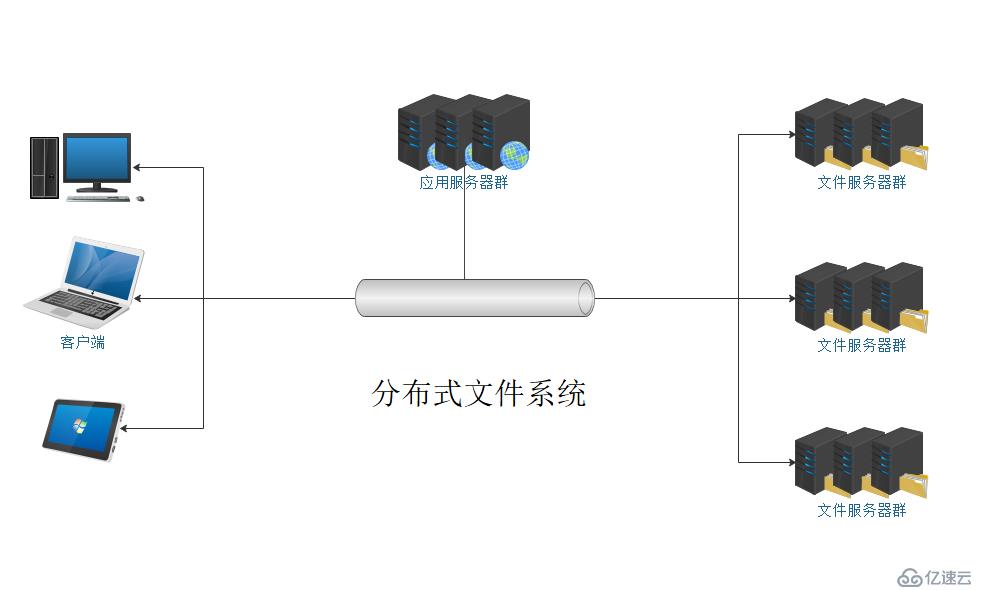
如上图所示,应用服务器和文件服务器分别存在于网络当中,而这里的网络,可以是统一子网,也可以是不同子网。服务器对文件的存取,均在网络进行,这样就可以突破常用存储设备的容量限制。
二、常用分布式文件系统的介绍
1、Lustre
lustre是一个大规模的、安全可靠的,具备高可用性的集群文件系统,它是由SUN公司开发和维护。该项目主要的目的就是开发下一代的集群文件系统,可以支持超过10000个节点,数以PB的数量存储系统。
2、Hadoop
hadoop不仅仅是一个用于存储的分布式文件系统,而其设计更是用来在由通用计算设备组成的大型集群上执行分布式应用的框架。目前主要应用于大数据、区块链等领域。
3、FastDFS
4、Ceph
三、Ceph 介绍
Ceph是一个具有高扩展、高可用、高性能的分布式存储系统,根据场景划分可以将Ceph分为对象存储、块设备存储和文件系统服务。在虚拟化领域里,比较常用到的是Ceph的块设备存储,比如在OpenStack项目里,Ceph的块设备存储可以对接OpenStack的cinder后端存储、Glance的镜像存储和虚拟机的数据存储。比较直观的是Ceph集群可以提供一个raw格式的块存储来作为虚拟机实例的硬盘。
Ceph相比其它存储的优势点在于它不单单是存储,同时还充分利用了存储节点上的计算能力,在存储每一个数据时,都会通过计算得出该数据存储的位置,尽量将数据分布均衡。同时由于Ceph本身的良好设计,采用了CRUSH算法、HASH环等方法,使得它不存在传统的单点故障的问题,且随着规模的扩大性能并不会受到影响。
四、Ceph 构成
Ceph的核心构成包括:Ceph OSD(对象存出设备)、Ceph Monitor(监视器) 、Ceph MSD(元数据服务器)、Object、PG、RADOS、Libradio、CRUSH、RDB、RGW、CephFS
OSD:全称 Object Storage Device,真正存储数据的组件,一般来说每块参与存储的磁盘都需要一个 OSD 进程,如果一台服务器上又 10 块硬盘,那么该服务器上就会有 10 个 OSD 进程。
MON:MON通过保存一系列集群状态 map 来监视集群的组件,使用 map 保存集群的状态,为了防止单点故障,因此 monitor 的服务器需要奇数台(大于等于 3 台),如果出现意见分歧,采用投票机制,少数服从多数。
MDS:全称 Ceph Metadata Server,元数据服务器,只有 Ceph FS 需要它。
Object:Ceph 最底层的存储单元是 Object 对象,每个 Object 包含元数据和原始数据。
PG:全称 Placement Grouops,是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
RADOS:全称Reliable Autonomic Distributed Object Store,是Ceph集群的精华,可靠自主分布式对象存储,它是 Ceph 存储的基础,保证一切都以对象形式存储。
CRUSH:是Ceph使用的数据分布算法,类似一致性哈希,让数据分配到预期的地方。
RBD:全称 RADOS block device,它是 RADOS 块设备,对外提供块存储服务。
RGW:全称 RADOS gateway,RADOS网关,提供对象存储,接口与 S3 和 Swift 兼容。
CephFS:提供文件系统级别的存储。
五、Ceph 部署
1、Ceph拓扑结构
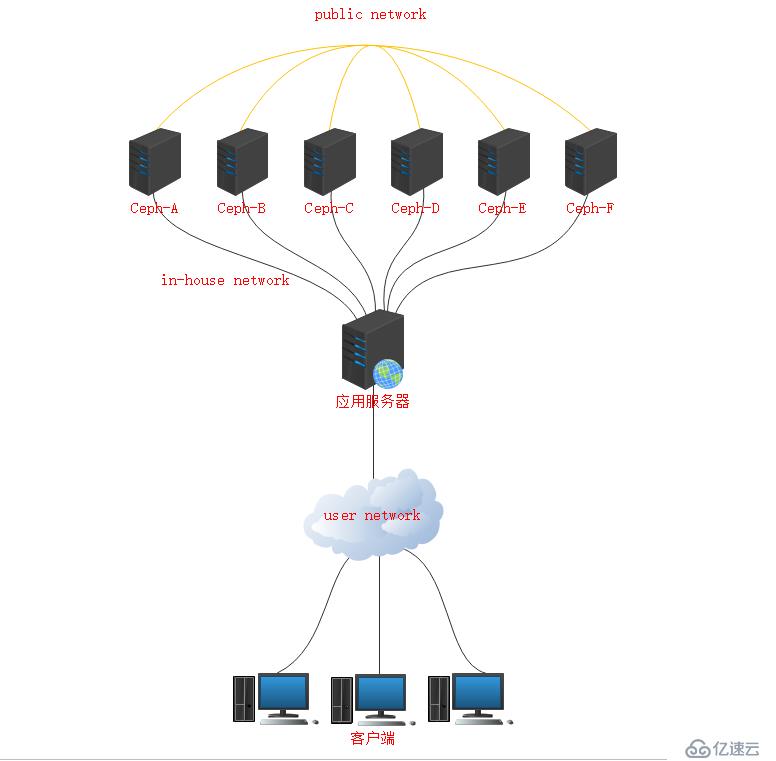
2、服务器规划

3、服务器环境准备
a、配置主机名、IP地址解析,分别在 6 台服务器中执行以下命令:
[root@ceph-a ~]# echo -e "192.168.20.144 ceph-a" >> /etc/hosts
[root@ceph-a ~]# echo -e "192.168.20.145 ceph-b" >> /etc/hosts
[root@ceph-a ~]# echo -e "192.168.20.146 ceph-c" >> /etc/hosts
[root@ceph-a ~]# echo -e "192.168.20.147 ceph-d" >> /etc/hosts
[root@ceph-a ~]# echo -e "192.168.20.148 ceph-e" >> /etc/hosts
[root@ceph-a ~]# echo -e "192.168.20.149 ceph-f" >> /etc/hosts b、配置免密登陆
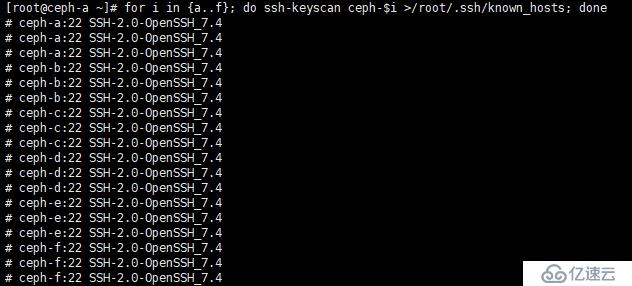
扫描服务器 A 到 F的密钥,其目的主要是避免在进行 ssh 连接或者在后面执行 ceph 类命令出现 yes/no 的交互,在 Ceph-A 中执行以下命令:
[root@ceph-a ~]# for i in {a..f}; do ssh-keyscan ceph-$i >/root/.ssh/known_hosts; done如下图:
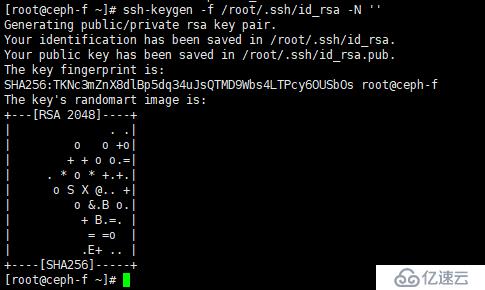
在 Ceph-A 生成私钥,在 Ceph-A 中执行以下命令:
[root@ceph-a ~]# ssh-keygen -f /root/.ssh/id_rsa -N ''如图:
说明:-f 参数指定私钥文件路径, -N 参数声明该过程为非交互式,也就是不用我们手动按回车键等
将私钥文件拷贝到 Ceph-B 到 Ceph-F 服务器中,执行以下命令:
[root@ceph-a ~]# for i in {b..f}; do ssh-copy-id ceph-$i; donec、配置 NTP 网络时间同步服务
在 6 台服务器中安装 chrony 软件包,在服务器 A 执行以下命令即可:
[root@ceph-a ~]# for i in {a..f}; do ssh ceph-$i yum -y install chrony ; done配置 Ceph-A 为 NTP 服务器:
[root@ceph-a ~]# vim /etc/chrony.conf 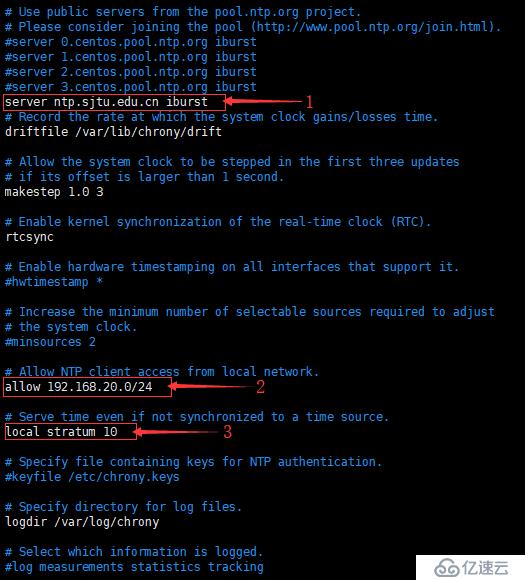
如图,修改图中的三个部分
①、注释掉默认的 NTP 服务器,添加国内的 NTP 服务器,这里添加的是北京邮电大学的 NTP 服务器。
②、允许 192.168.20.0/24 网段进行时间同步。
③、本地时间服务器层级,取消注释即可。
配置 Ceph-B 到 Ceph-F 服务器通过 Ceph-A 进行时间同步
[root@ceph-b ~]# vim /etc/chrony.conf 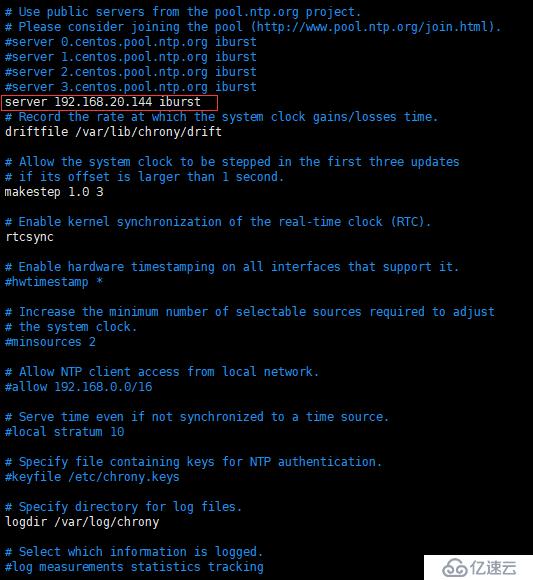
如图,将图中红框内(也就是刚才配置的 Ceph-A)的 NTP 服务器添加进去即可,其他没用的注释。
保存并退出,并将改配置文件复制到 Ceph-C 到 Ceph-F 中:
[root@ceph-b ~]# for i in {c..f}; do scp /etc/chrony.conf ceph-$i:/etc/; done重启 Ceph-A 到 Ceph-F 的 chrony 服务,在 Ceph-A 中执行以下命令:
[root@ceph-a ~]# for i in {a..f}; do ssh ceph-$i systemctl restart chronyd; done同步 Ceph-A 的时间
[root@ceph-a ~]# ntpdate ntp.sjtu.edu.cn 
同步 Ceph-B 到 Ceph-F 的时间,在 Ceph-A 中执行即可:
[root@ceph-a ~]# for i in {b..f}; do ssh ceph-$i ntpdate 192.168.20.144; done 
4、配置 yum 源
之前我们有部署本地 yum 仓库,这里,我们使用之前配置的 yum 仓库。
移除系统自带的 repo 文件,编辑 /etc/yum.repos.d/localhost.repo 文件,将下面内容添加到该文件中:
[Centos-Base]
name=Centos-Base-Ceph
baseurl=http://192.168.20.138
enable=1
gpgcheck=1
priority=2
type=rpm-md
gpgkey=http://192.168.20.138/ceph-key/release.asc清空元数据缓存并重建
[root@ceph-a ~]# yum clean all
[root@ceph-a ~]# yum makecache5、安装 Ceph 服务,这里将 Ceph-A 做为 admin 管理端
a、在 Ceph-A 中安装 ceph-deploy
[root@ceph-a ~]# yum -y install ceph-deployb、在 Ceph-A 中创建 ceph 的工作目录并进入
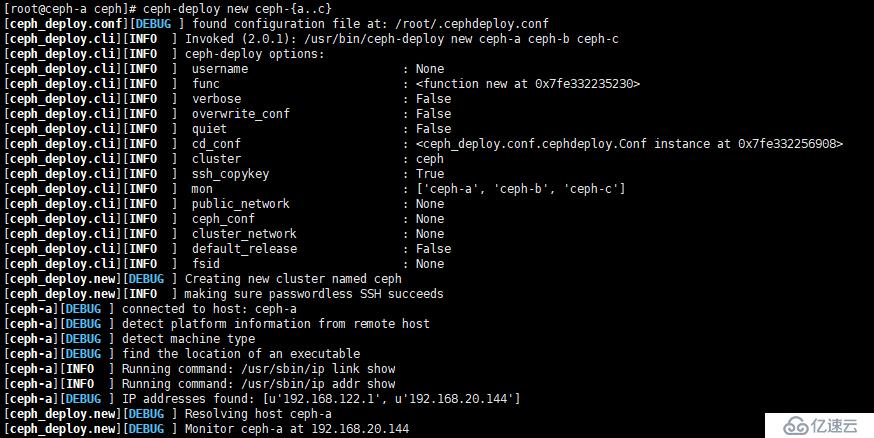
[root@ceph-a ~]# mkdir /etc/ceph && cd /etc/cephc、Ceph-A 到 Ceph-C 中创建集群节点配置文件,Ceph-D 到 Ceph-F 服务器暂有他用,以下操作,均不涉及在内。
[root@ceph-a ~]# ceph-deploy new ceph-{a..c}如图:
d、在 Ceph-A 到 Ceph-C 三个节点中安装 ceph 软件包
[root@ceph-a ceph]# ceph-deploy install ceph-{a..c}如图:
e、初始化 mon 服务
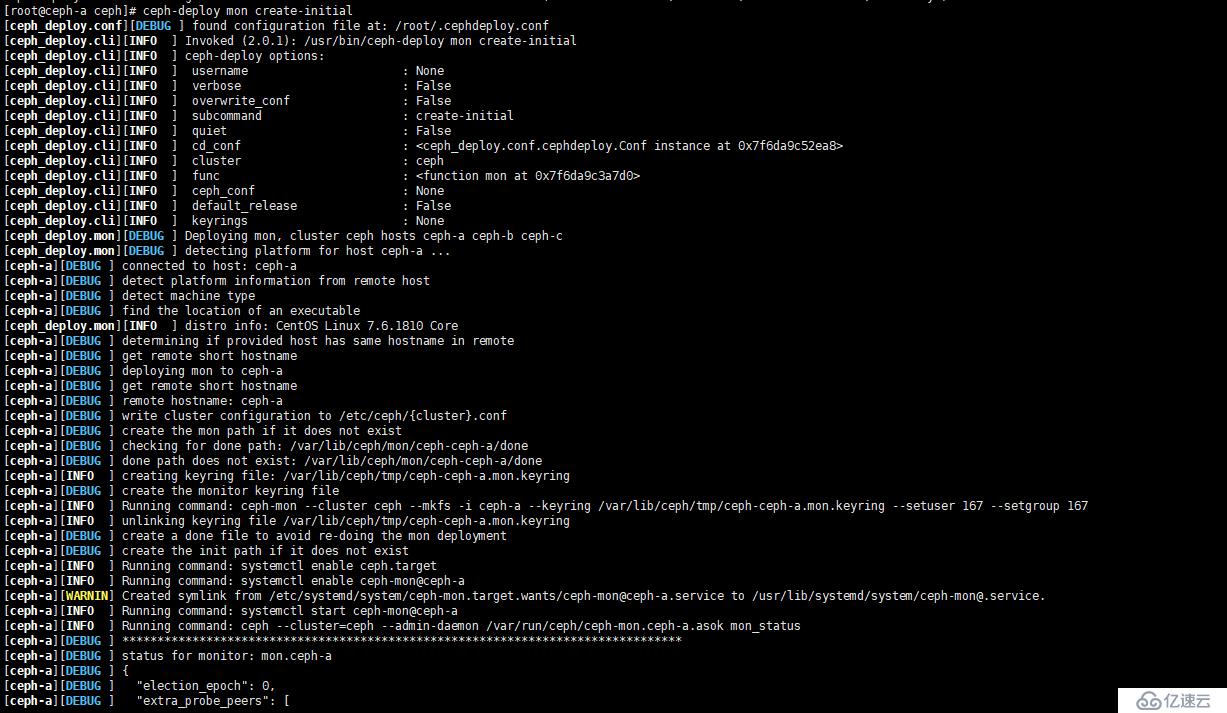
[root@ceph-a ceph]# ceph-deploy mon create-initial如图:
f、创建 OSD 设备
在服务器规划中,我们一共规划了 4 块硬盘,其中 sda 用作系统盘,那么还剩下 sdb、sdc、sdd 三块硬盘,这里,我们将 sdb 硬盘做为日志盘,而 sdc 和 sdd 做为数据盘。
①、将 Ceph-A 到 Ceph-C 的 sdb 硬盘格式化为gpt格式
[root@ceph-a ~]# for i in {a..c}; do ssh ceph-$i parted /dev/sdb mklabel gpt; done说明:如果这里这条命令有报错,则需要把此命令拆分成下面两条命令,然后分别到 Ceph-A、Ceph-B、Ceph-C中单独执行。
parted /dev/sdb mklabel gpt
②、给硬盘 sdb 创建分区
[root@ceph-a ~]# for i in {a..c}; do ssh ceph-$i parted /dev/sdb mkpart primary 1M 50%; done
[root@ceph-a ~]# for i in {a..c}; do ssh ceph-$i parted /dev/sdb mkpart primary 50% 100%; done分区成功与否,可以使用 lsblk 命令进行查看:
[root@ceph-a ~]# lsblk如图:

③、为分区 sdb1 和 sdb2 分配属主属组为 ceph
[root@ceph-a ~]# for i in {a..c}; do ssh ceph-$i chown ceph.ceph /dev/sdb?; done注意:此处有可能会出现下面的错误
[ceph-a][ERROR ]admin_socket:exception getting command descriptions:[Errno 2]No such file or directory解决方案如下:
编辑 ceph.conf ,在最下面加入如下行:
public_network = 192.168.20.0/24
保存并退出,再执行以下命令,将配置文件覆盖推送到三台服务器节点:
[root@ceph-a ceph]# ceph-deploy --overwrite-conf config push ceph-a ceph-b ceph-c ④、此时,我们可以查看一下 ceph 状态,使用命令 ceph health 或者 ceph -s
[root@ceph-a ceph]# ceph health正常情况下会输出 HEALTH_OK ,如果不是,有可能会有以下情况
ceph:health_warn clock skew detected on mon出现此错误,说明我们的服务器时间同步有问题,我们可以先进行时间同步
[root@ceph-a ~]# for i in {b..f}; do ssh ceph-$i ntpdate 192.168.20.144; done如果时间同步后,还是没有解决,则使用以下解决办法:
[root@ceph-a ceph]# vim ceph.conf
在global字段下添加:
mon clock drift allowed = 2
mon clock drift warn backoff = 30
2、向需要同步的 mon 节点推送配置文件:
[root@ceph-a ceph]# ceph-deploy --overwrite-conf config push ceph-a ceph-b ceph-c
这里是向Ceph-A、Ceph-B、Ceph-C推送,也可以后跟其它不连续节点
3. 重启 mon 服务(centos7环境下)
[root@ceph-a ceph]# for i in {a..c}; do ssh ceph-$i systemctl restart ceph-mon.target; done
4.验证:
[root@ceph-a ceph]# ceph health
显示 OK ,就说明正常了使用 ceph -s 查看状态时,也有可能会出现下面情况:
如图:
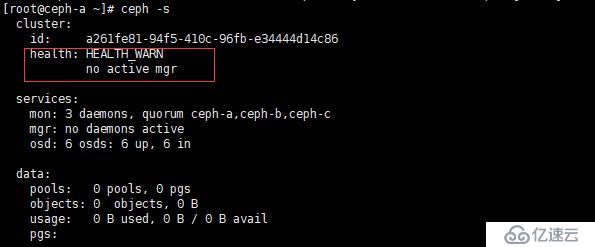
如图红框中所示,no active mgr,这种情况,需要我们手动创建管理进程,解决方案如下
[root@ceph-a ceph]# ceph-deploy mgr create ceph-{a..c}再次查看状态,如下图
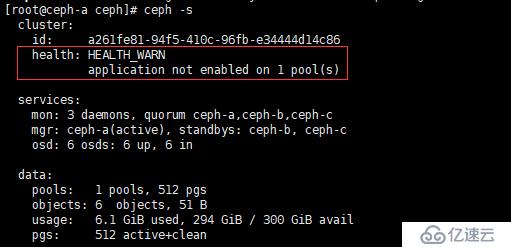
发现变成了application not enabled on 1 pool(s),这种情况,我们要执行
[root@ceph-a ceph]# ceph osd pool application enable cephrbd imagecephrbd:为我们手动创建的 pool
image:为我们手动创建的镜像
再次查看状态
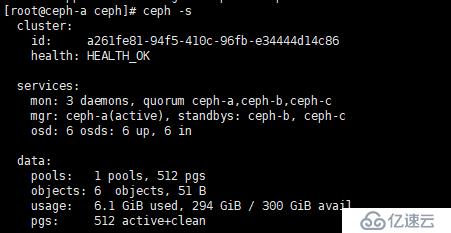
发现已经变成 OK ,表示正常
⑤、初始化 sdc、sdd 硬盘,清空硬盘数据
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy disk zap ceph-$i /dev/sdc; done
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy disk zap ceph-$i /dev/sdd; done如图:
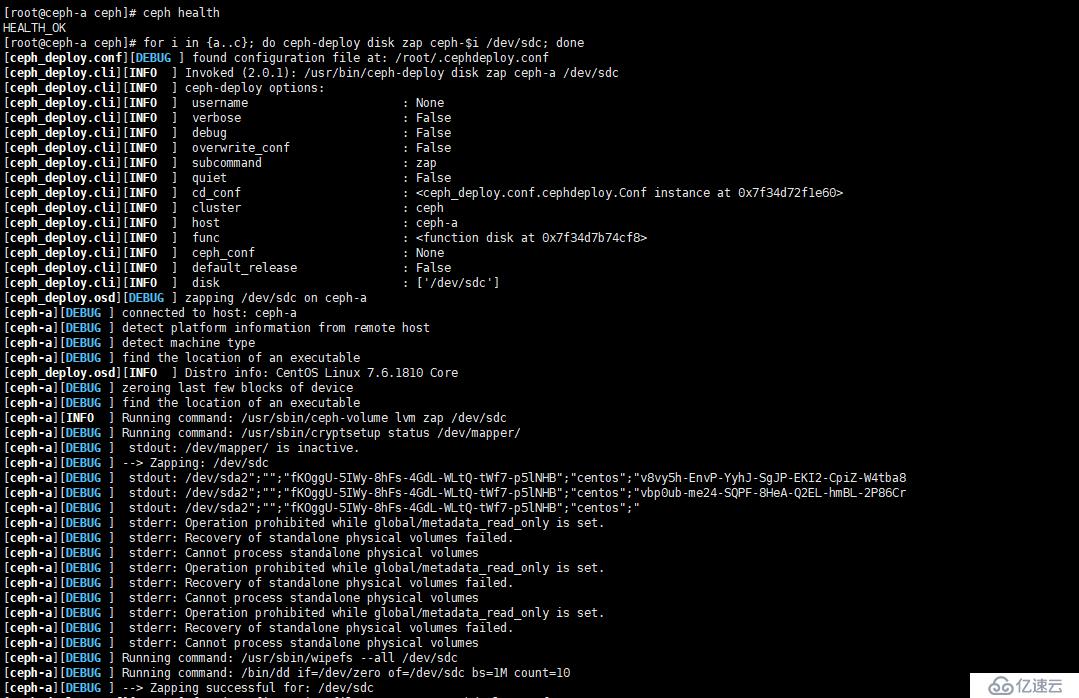
注意:在 13.2.0 之前的版本中,应使用以下命令:
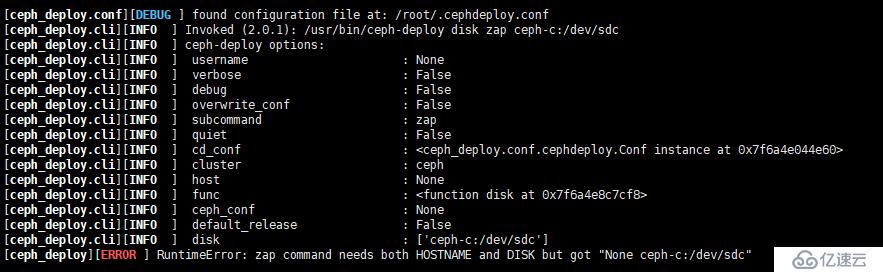
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy disk zap ceph-$i:/dev/sdc ceph-$i:/dev/sdd; done 但是上面的命令在本例 13.2.2 版本不适合,否则,会有下面的报错,这个坑,花了好长时间,才发现是命令格式错误(官方文档也一样,不是最新版的,很多地方并不适用于最新版)
⑥、创建 OSD 存储空间,这里把 sdb1 做为 sdc 的日志盘,把 sdb2 做为 sdd 的日志盘
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy osd create --data /dev/sdc --journal /dev/sdb1 ceph-$i; done
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy osd create --data /dev/sdd --journal /dev/sdb2 ceph-$i; done如图:
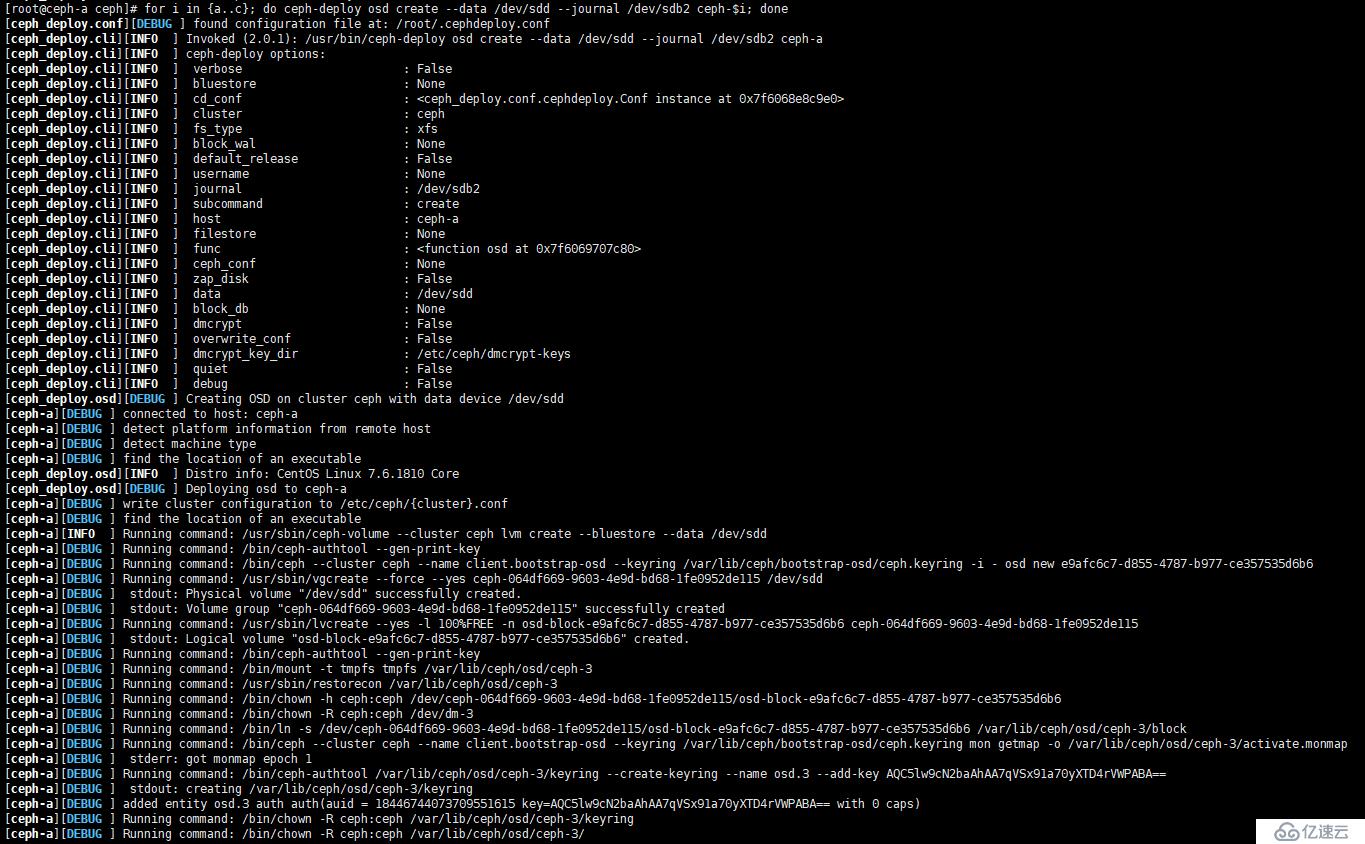
--data:指定数据盘
--journal:指定日志盘
此处也存在命令格式问题,如果是 13.2.0 之前的版本,则使用下面命令:
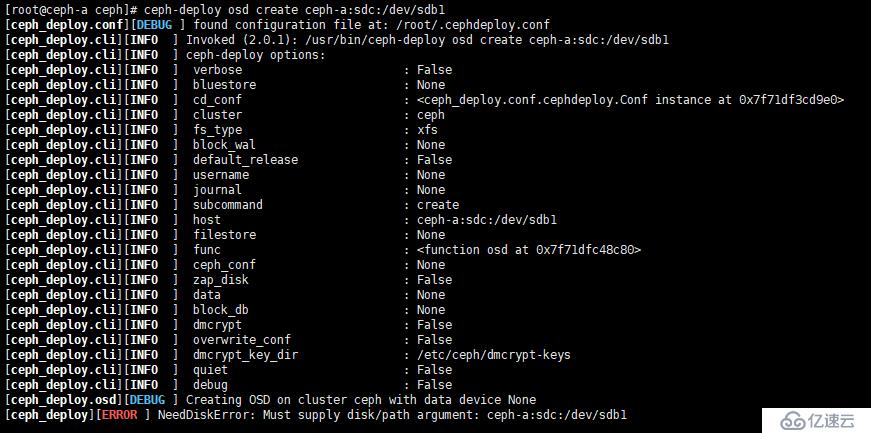
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy osd create ceph-$i:sdc:/dev/sdb1; done
[root@ceph-a ceph]# for i in {a..c}; do ceph-deploy osd create ceph-$i:sdc:/dev/sdb1; done如果在本例中使用上面命令,则会报以下错误,如图
经过上述步骤,我们的 Ceph 算是安装完成,下面,我们简单的说下 Ceph 应用,更详细的应用后期章节再进行解析。
六、使用 RBD(RADOS 块设备)
1、首先,我们了解一下 Ceph 的存储方式,Ceph 共支持三种存储方式:
a、块存储,这也是使用最多的存储方式。
b、CephFS:这种存储方式了解就行,不建议在生产环境中使用,因为还不够成熟。
c、对象存储:该存储方式也是了解就行,现阶段还不够成熟稳定。仅支持 OpenStack Swift 和 Amazon S3 两种接口,后期有需要,我们再讲解。
2、其次,我们了解一下什么是 ceph 块存储:
a、Ceph 块设备也叫做 RADOS 设备,即:RADOS block device(RBD)。
b、RBD 驱动已经很好的集成在 Linux 内核中。
c、RBD 提供了企业功能,如快照、COW克隆等等。
d、RBD 还支持内存缓存,从而能够大大提高性能。
e、Linux 内核可以直接房访问 Ceph 块存储。
f、KVM 可用借助于 librdb 访问。
3、使用 RBD
①、查看存储池
[root@ceph-a ceph]# ceph osd lspools 一般来说,都会有一个默认的 0 号存储池,但是呢,在小弟在这里查看的时候,却没有默认的 0 号存储池,不知道是不是官方已将其移除,还需后续继续观察。
②、创建 ceph OSD 存储池
[root@ceph-a ~]# ceph osd pool create cephrbd 512如图:

这里,cephrbd 是存储池的名称。
● 通常在创建pool之前,需要覆盖默认的 pg_num,官方推荐:
● 若少于5个OSD, 设置 pg_num 为128。
● 5~10个OSD,设置 pg_num 为512。
● 10~50个OSD,设置 pg_num 为4096。
● 超过50个OSD,可以参考 pgcalc 计算。
③、创建名为 image 的镜像,大小为10G
[root@ceph-a ~]# rbd create cephrbd/image --image-feature layering --size 10Gcephrbd/image:表示在存储池 cephrbd 中创建 image 的镜像
--image-feature:该选项指定使用特性,不用全部开启。我们的需求仅需要使用快照、分层存储等特性,开启layering即可
④、查看 cephrbd 存储池中是否有镜像存在
[root@ceph-a ~]# rbd ls cephrbd如图:

⑤、查看镜像信息
[root@ceph-a ~]# rbd info cephrbd/image 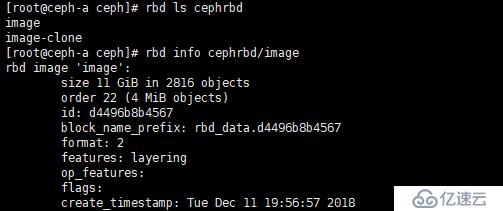
⑥、编写 UDEV 规则,使得 sdb1和 sdb2 重启后,属组属主任然是 ceph
[root@ceph-a ~]# vim /etc/udev/rules.d/87-cephdisk.rules
ACTION=="add",KERNEL=="sdb?",OWNER="ceph",GROUP="ceph"将规则拷贝到 Ceph-B 和 Ceph-C
[root@ceph-a ~]# for i in {b..c}; do scp /etc/udev/rules.d/87-cephdisk.rules ceph-$i:/etc/udev/rules.d/; done4、镜像操作
①、扩容容量
[root@ceph-a ~]# rbd resize --size 15G cephrbd/image将 image 镜像扩容到15G
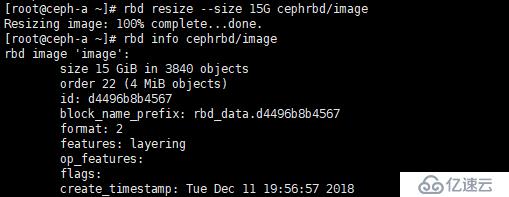
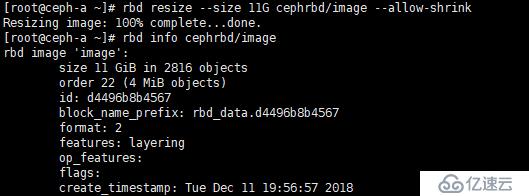
②、缩小容量
[root@ceph-a ~]# rbd resize --size 11G cephrbd/image --allow-shrink 将image 镜像容量缩小至11G
③、删除镜像
[root@ceph-f ceph]# rbd rm cephrbd/demo-img5、使用 Ceph 客户端
在这里,我们将 Ceph-F 服务器做为 Ceph 客户端,并将之前创建的镜像 image 映射到 Ceph-F 做为磁盘使用。
a、在 Ceph-F 安装 Ceph 客户端软件
[root@ceph-f ~]# yum -y install ceph-commonb、将 Ceph-A 的 ceph.conf 和 ceph.client.admin.keyring 拷贝到 Ceph-F
[root@ceph-a ceph]# scp ceph.c* ceph-f:/etc/ceph 
ceph.client.admin.keyring 是 client.admin 用户的密钥文件
c、查看状态
[root@ceph-f ~]# ceph -s
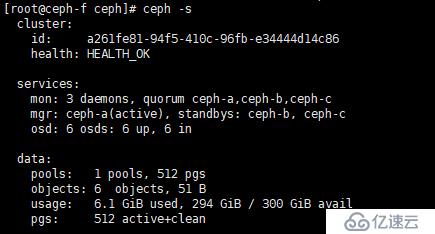
d、映射镜像到本地
[root@ceph-f ceph]# rbd map cephrbd/image 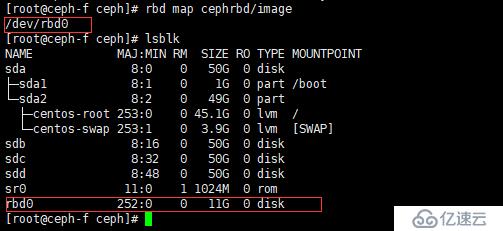

e、查看映射磁盘的信息
[root@ceph-f ceph]# rbd showmapped 

f、格式化、挂载 /dev/rbd0
①、格式化 /dev/rbd0
[root@ceph-f ceph]# mkfs.ext4 /dev/rbd0 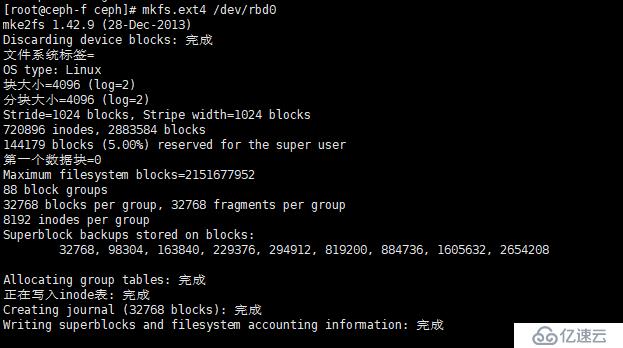
②、将 /dev/rbd0 挂载到 /image,并添加开机自动挂载
[root@ceph-f ceph]# mkdir /image
[root@ceph-f ceph]# mount /dev/rbd0 /image
[root@ceph-f ceph]# echo -e "/dev/rbd0 /image ext4 defaults 0 0" >> /etc/fstabg、往 /image 中写入数据,并查看数据是否写入成功
[root@ceph-f ceph]# echo "hello world" >/image/log.txt
[root@ceph-f ceph]# cat /image/log.txth、创建镜像快照,为 image 镜像创建 image-sn1 的快照
[root@ceph-f ceph]# rbd snap create cephrbd/image --snap image-sn1i、查看 image 快照
[root@ceph-f ceph]# rbd snap ls cephrbd/image

j、删除镜像快照
[root@ceph-f ceph]# rbd snap remove cephrbd/image@image-sn1k、镜像快照操作
①、通过快照进行数据恢复
删除 /iamge/log.txt 文件
[root@ceph-f ceph]# rm -rf /image/log.txt卸载挂载点
[root@ceph-f ceph]# umount /dev/rbd0使用 image-sn1 还原快照
[root@ceph-f ceph]# rbd snap rollback cephrbd/image --snap image-sn1再挂载 /dev/rbd0,查看文件是否存在
[root@ceph-f ceph]# mount /dev/rbd0 /image
[root@ceph-f ceph]# ll /image/②、快照克隆
如果你想从快照恢复出一个新的镜像,则可以使用快照克隆
注意:克隆前,需要对快照进行<保护>(protect)操作,被保护的快照无法删除,取消保护(unprotect)
[root@ceph-f ceph]# rbd snap protect cephrbd/image --snap image-sn1尝试删除刚才保护的快照
[root@ceph-f ceph]# rbd snap remove cephrbd/image@image-sn1 如上图,快照无法删除
克隆 image-sn1 快照,克隆的名称为 image-clone
[root@ceph-f ceph]# rbd clone cephrbd/image --snap image-sn1 cephrbd/image-clone --image-feature layering查看克隆快照的状态
[root@ceph-f ceph]# rbd info cephrbd/image-clone 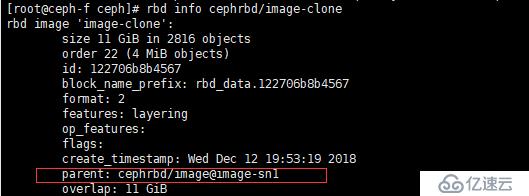
红框中内容说明是:池 cephrbd 的镜像 image 的快照 image-sn1 的克隆
③、合并克隆文件
[root@ceph-f ceph]# rbd flatten cephrbd/image-clone 
查看合并后的信息
[root@ceph-f ceph]# rbd info cephrbd/image-clone 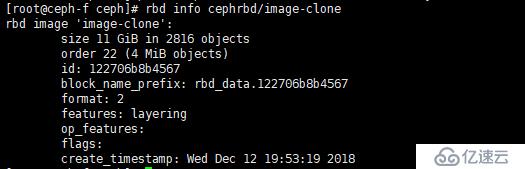
由上图,我们发现它已经变为一个独立的镜像了
查看 cephrbd 池中的镜像
[root@ceph-f ceph]# rbd ls cephrbd 
④、取消映射
[root@ceph-f ceph]# rbd unmap /dev/rbd/cephrbd/image关于 Ceph 更多的应用,小弟会在后期文章中进行细述,今天,我们就到此结束。
关于 Ceph 块设备的应用,请参阅小弟的另外一篇博文:https://blog.51cto.com/4746316/2330070
关于 CephFS 文件系统的应用,请参阅小弟的另外一篇博文:https://blog.51cto.com/4746316/2330186
关于 Ceph 对象存储,请参阅小弟的另外一篇博文:https://blog.51cto.com/4746316/2330455
七、Ceph 部署总结
Ceph 的部署,总体来说还是比较简单,虽然说,看似简单,但是越简单的东西,我们更加需要重视,因为我们认为越简单的地方,才是我们在日常运维中越容易踩坑的地方。就比如,上面部署过程中,遇到的几个问题,就连官方文档中都没有体现出来,导致小弟在填坑时花了不少心思,但好歹还是找出问题所在了。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



