今天给大家介绍一下Transformer的原理及与RNN encoder-decoder比较是怎样的。文章的内容小编觉得不错,现在给大家分享一下,觉得有需要的朋友可以了解一下,希望对大家有所帮助,下面跟着小编的思路一起来阅读吧。
1、与RNN encoder-decoder比较
靠attention机制,不使用rnn和cnn,并行度高
通过attention,抓长距离依赖关系比rnn强
transformer的特征抽取能力比RNN系列模型好,seq2seq最大的问题将encoder端的所有信息压缩到一个固定长度的张量中。
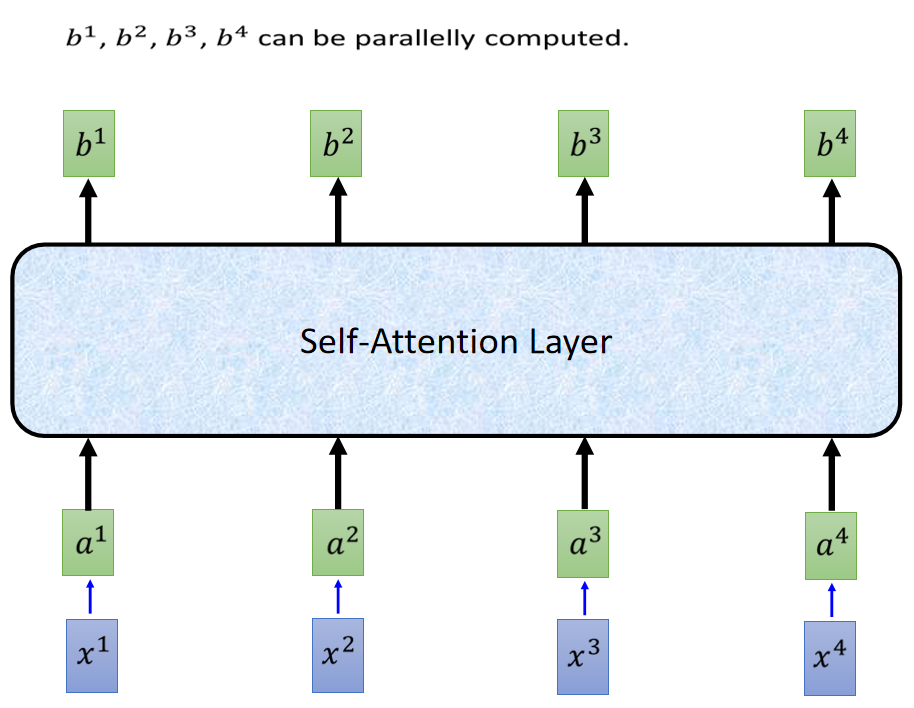
2. Transformer认识
1) RNN(LSTM, GRU)训练时迭代,串行的,需等当前词处理完,再处理下一个词。Transformer的训练(encoder,decoder)是并行的,所有词是同时训练 ,增加了计算效率。

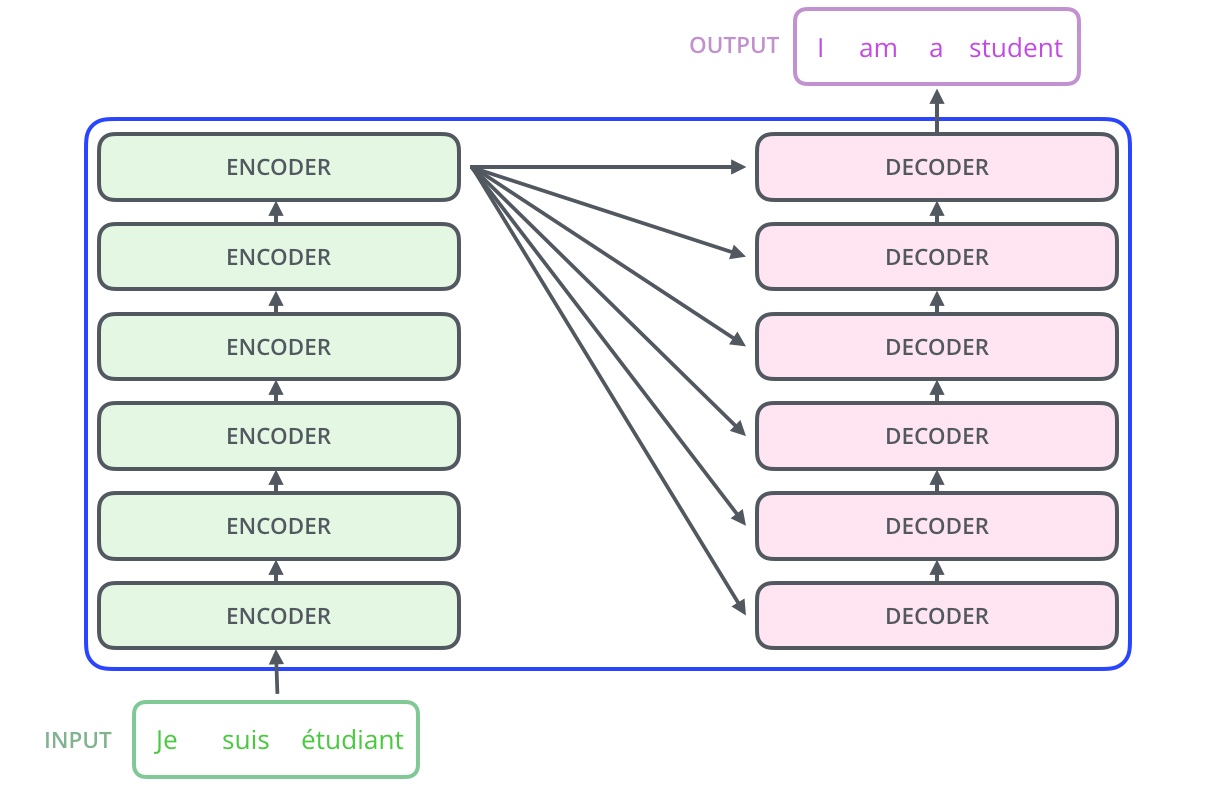
2) Transformer模型由Encoder和Decoder组成。
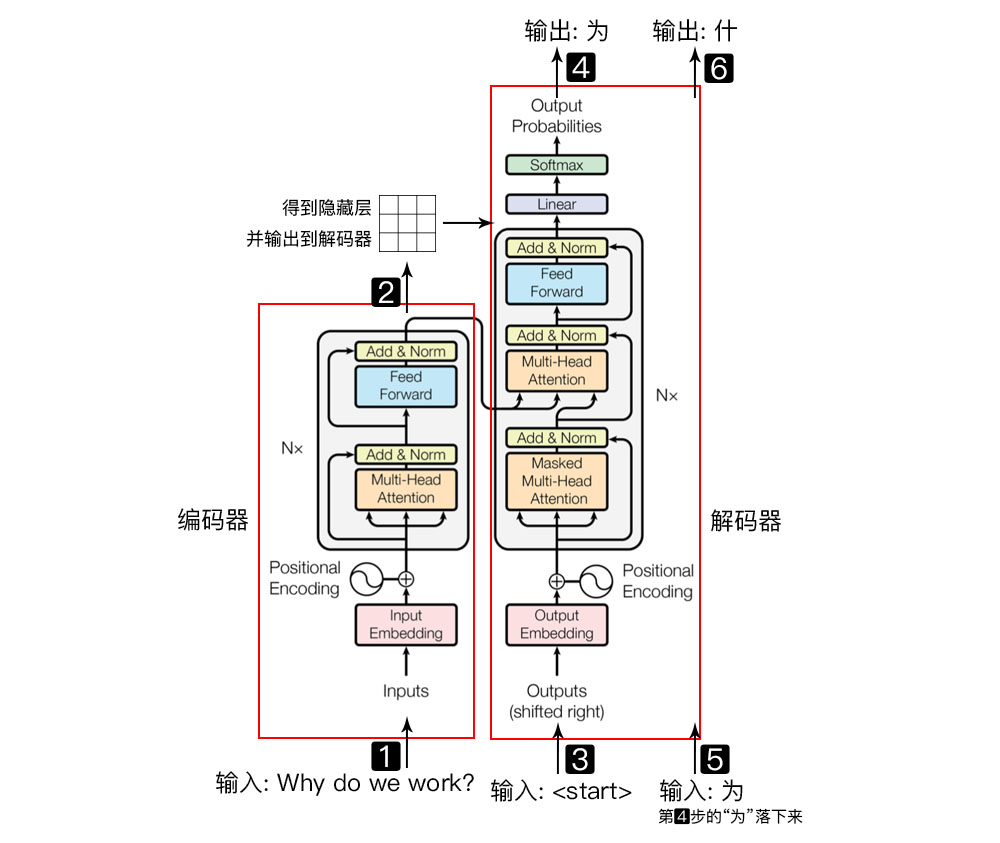
3. positional encoding
1)self-attention无RNN中的位置信息,在embedding input后加上positional.
2)位置编码采用二进制表示浪费空间,满足三个条件即可,它应该为每个字输出唯一的编码;不同长度的句子之间,任何两个字之间的差值应该保持一致;它的值应该是有界的。sin, cos是连续且可导。
3)公式: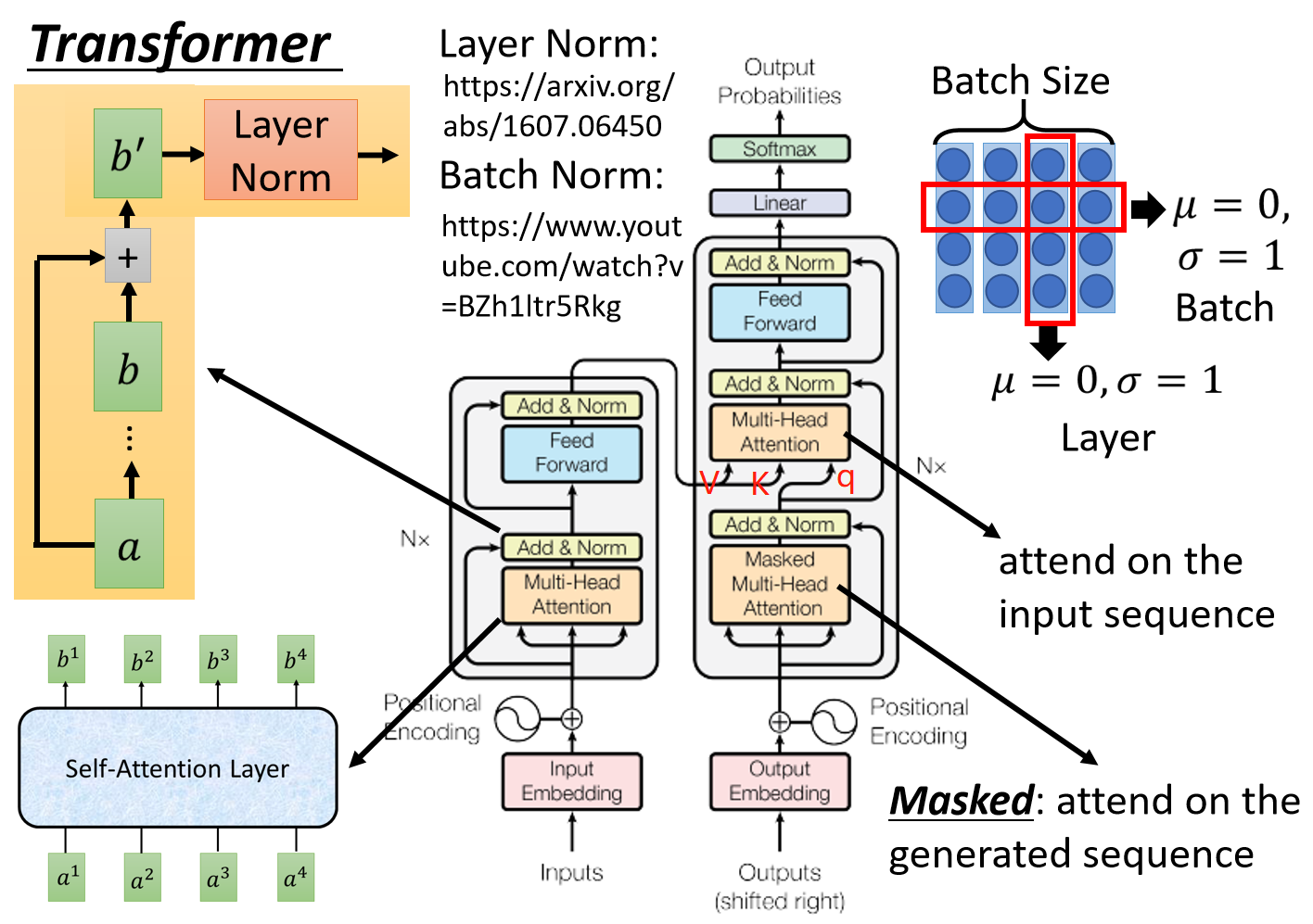
1)残差网络:b` = b + a, b = (attention or feed farward)(a)
2)归一化:与RNN搭配的是Layer Normalization, Transformer用LN
3) BN和LN的区别,BN在batch层对同一个dimention做normalization, 均值为0,方差为1;LN不考虑batch层,不同dimention的均值mean为0,方差为1.
5. mask
1) padding mask
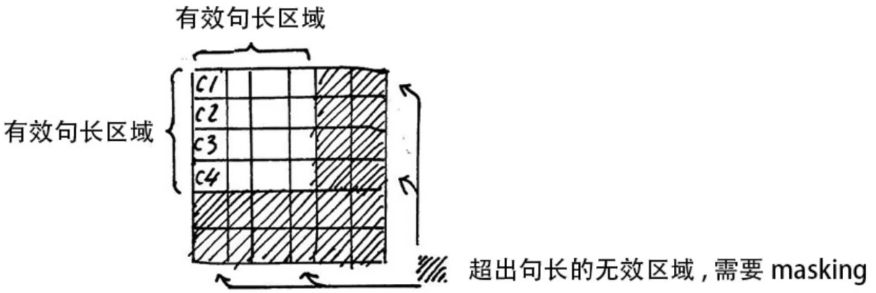
在softmax时对0也会进行运算,exp(0)=1, 这样让无效的部分参与了运算,会产生隐患,所以需做一个mask操作,让无效区域不参与运算,一般让无效区域加一个很大的负数偏置。
Tips: 我们通常使用 mini-batch 来计算,也就是一次计算多句话,即x的维度是 [batch_size, seq_length],seq_length是句长,而一个 mini-batch 是由多个不等长的句子组成的,我们需要按照这个 mini-batch 中最大的句长对剩余的句子进行补齐,一般用 0 进行填充,这个过程叫做 padding.
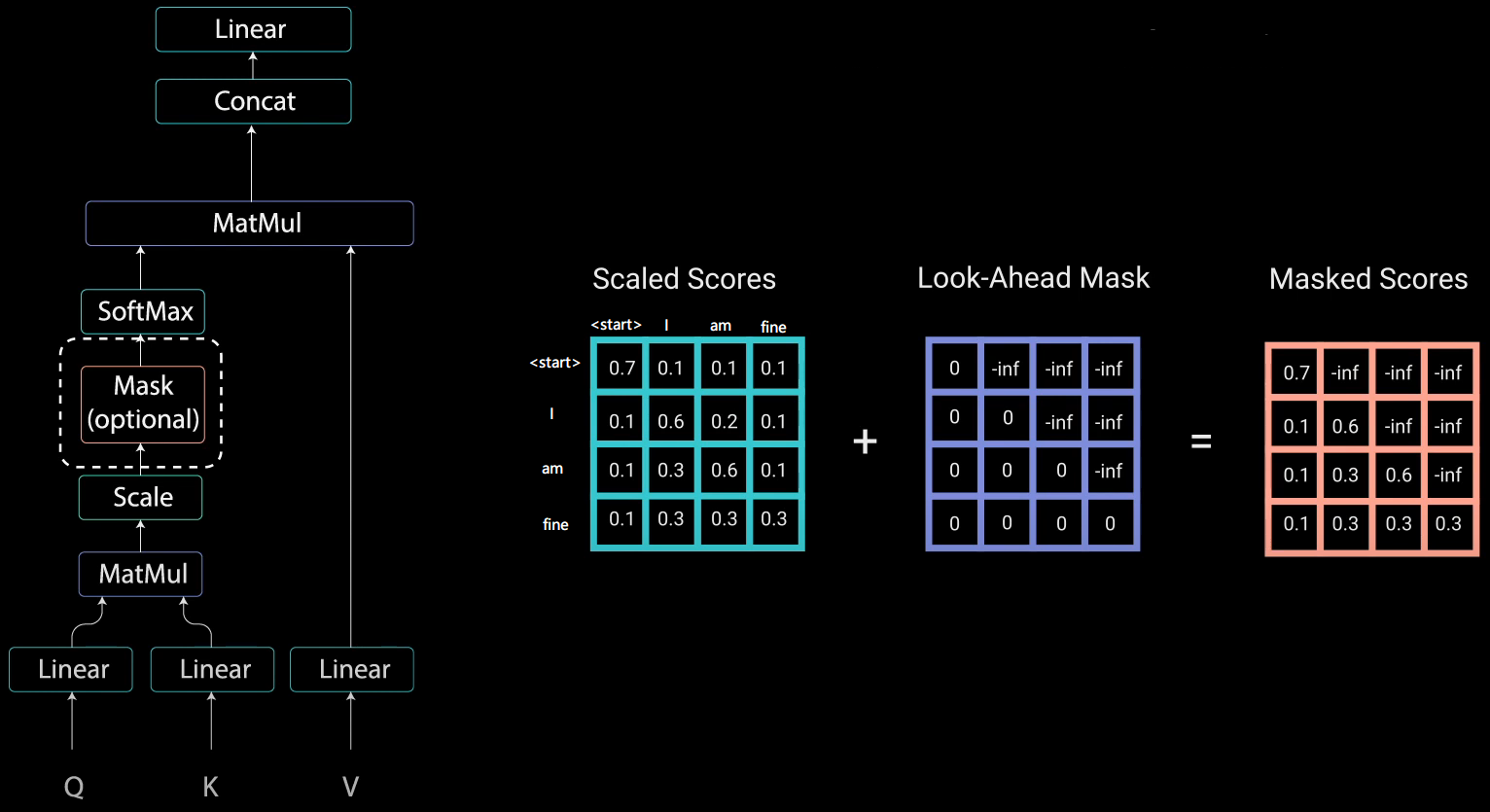
2) squence mask
mask, 不给模型看到未来的信息。当Encoder的输入是:机器学习,则decoder的输入是:<start>machine learning
Transformer Decoder改为self-Attention, 在训练过程中不像Seq2Seq中RNN的时间驱动机制(t时刻结束才能看到t+1时刻的词),而使得所有未来词暴露在Decoder中。Mask使得上三角的词为0, softmax(-inf)=0
6. self-attention & multi-head attention
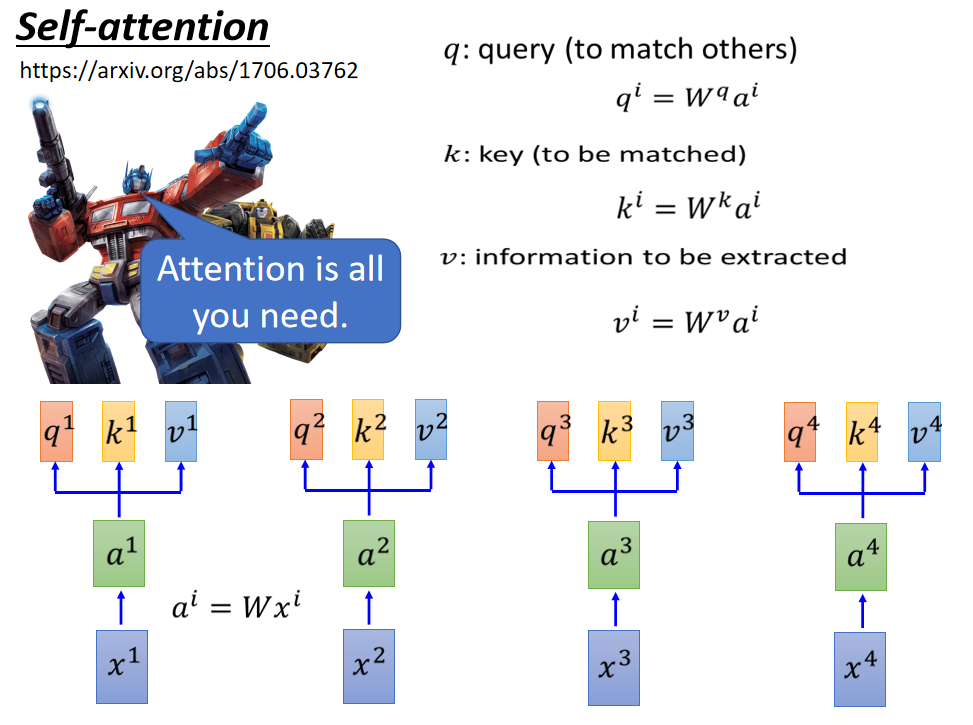
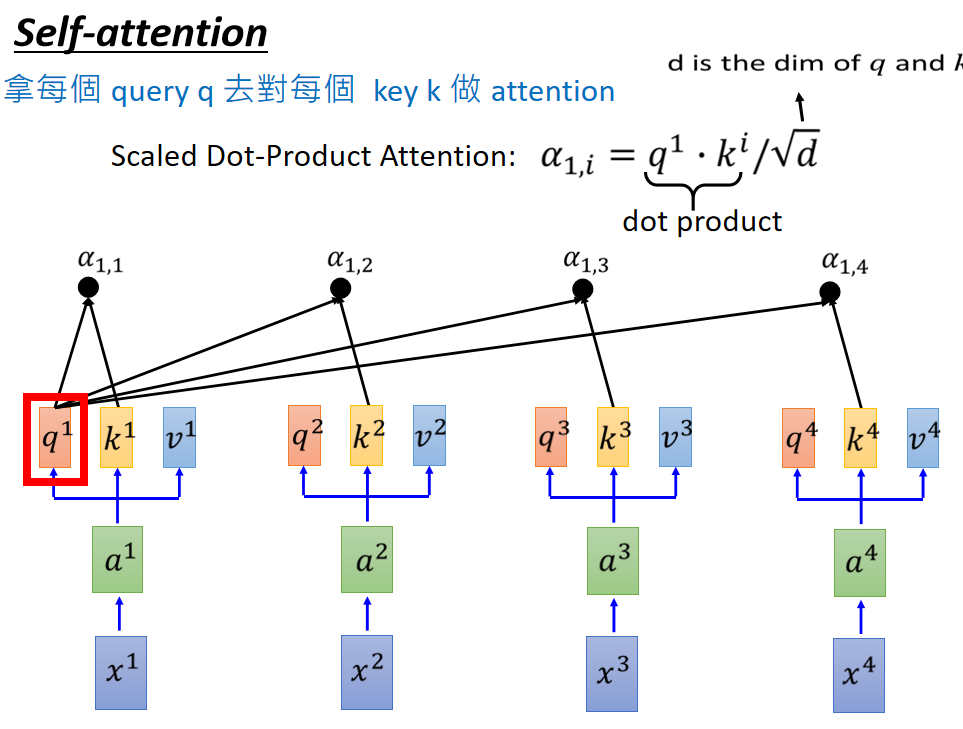

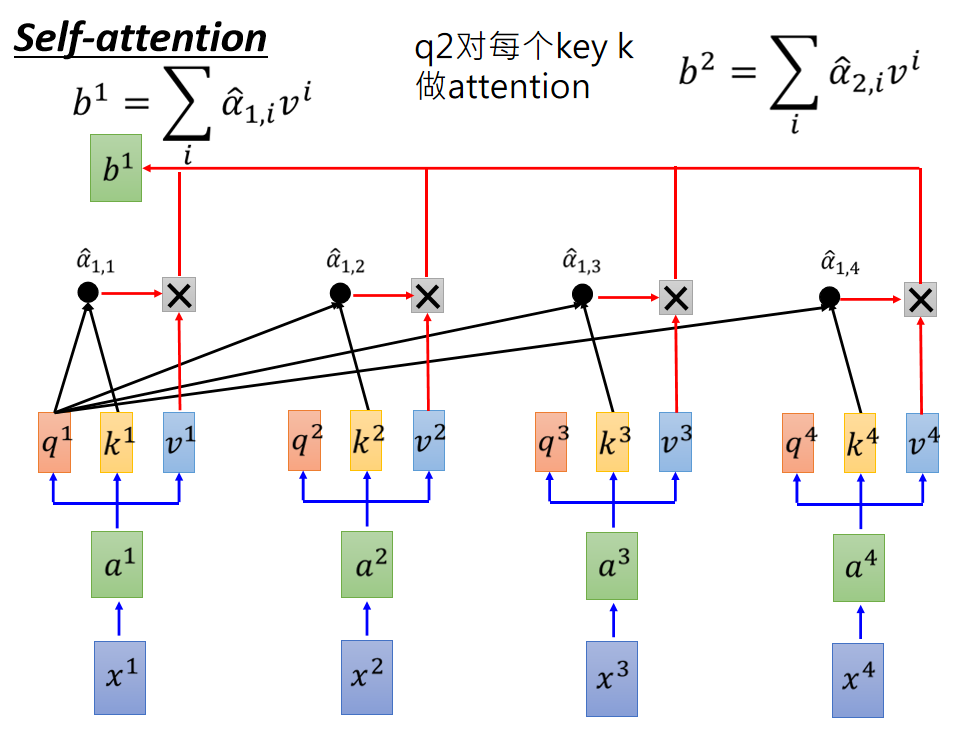
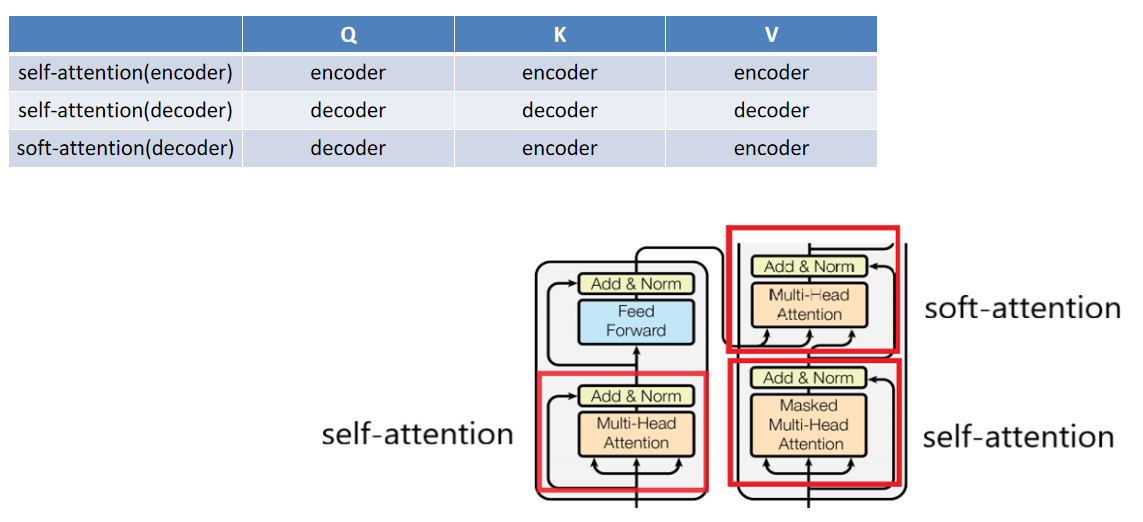
根据位置不同,分为self-attention和soft-attention
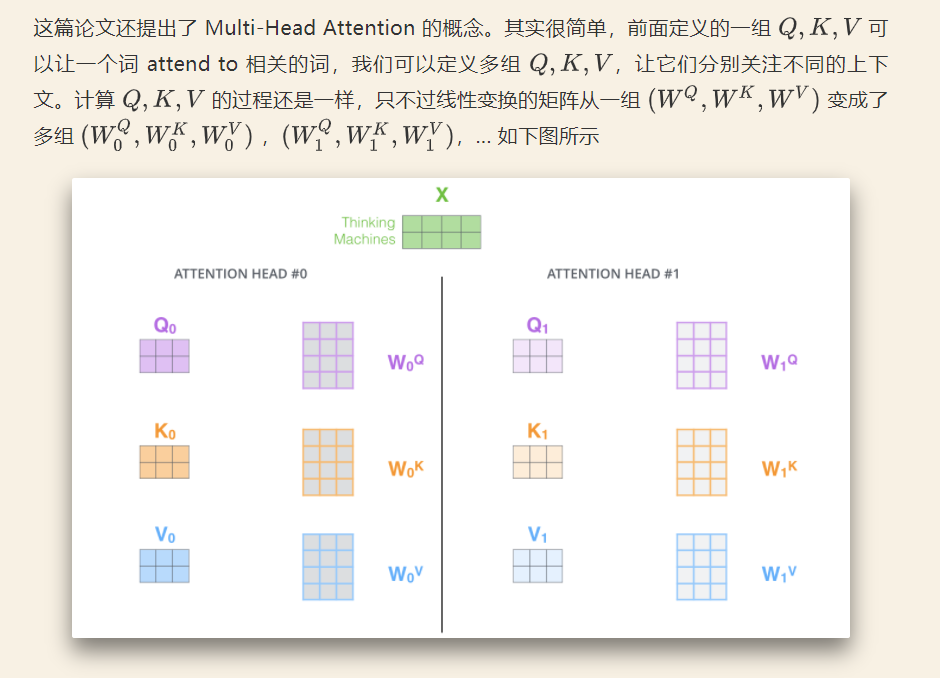
2) multi-head attention
multi-head可以去关注不同点,注意力侧重点可以在不同方面,最后再将各方面的信息综合起来,有助于捕捉到更丰富的特征。
以上就是Transformer的原理及与RNN encoder-decoder比较是怎样的的全部内容了,更多与Transformer的原理及与RNN encoder-decoder比较是怎样的相关的内容可以搜索亿速云之前的文章或者浏览下面的文章进行学习哈!相信小编会给大家增添更多知识,希望大家能够支持一下亿速云!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/872413/blog/4585215



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



